


































Gemini For Museums: Using Gemini Deep Research To Create Rich Historical Backgrounders For A Seminal Collection Of Picture Bibles
Over the last two weeks, we've used Gemini Deep Research to produce richly detailed historical background reports for a collection…

Gemini For Museums: From Cellphone Photo Of A Civil War Map To A Full Historical Backgrounder
Continuing our series applying Gemini Deep Research to write historical backgrounders for historical artifacts, earlier today we demonstrated Deep Research's…

Gemini For Museums: Identifying And Contextualizing A Fragile Folded 1939 Estonian Map From A Cellphone Photo Of The Visible Panels
Earlier this week we used Gemini Deep Research to identify a trio of Estonian ceramics that had remained unlabeled in…

Gemini For Museums: From Handwritten Marginalia To A Maggs Bros Catalog Entry
One of the more fascinating museum applications of Gemini we've been exploring is its potential to identify and transcribe marginalia…

Gemini For Museums: From A Cellphone Photograph To A Rich Historical Backgrounder & Identification Of A Trio Of Estonian Ceramics
Amongst The Collection are a small handful of physical artifacts alongside its primary focus on books and manuscripts. Among those…

Gemini For Museums: Using Gemini Deep Research To Curate A Collection Of Estonian History Into A National Founding Narrative
As we continue our explorations how Gemini Deep Research could be used by museum curators to craft narratives around specific…
Some Fascinating Insights From Media Trends' Inaugural "Contrarian Narrative Scenarios"
Yet another new experimental addition to our Media Trends reports is the "Contrarian Narrative Scenarios" section that asks Gemini to…

Adding Several Exciting New Experimental Narrative Analysis Sections To Our Media Trends Reports
Earlier this week we added a power new "Geopolitical Framing" section to our Media Trends reports that explores the narrative…

Gemini For Museums: Using Gemini Deep Research To Create Rich Historical Backgrounders For An Americana Collection
In honor of America's 250th, we posted a brief look at the Collection's small Americana archive, which encompass an incredible…
Gemini For Museums: Using Gemini Deep Research To Compile Bespoke Historical Contexts For Items
One of the most important roles of museums and other cultural institutions is not just putting items on display, but…
Using Gemini + Veo To Turn Centuries-Old Jode & Visscher Engravings Into "Living Animations"
The masterful copperplate engravings in seminal picture Bibles like the Jode (the first picture Bible) and the Visscher Royal (a…

Parallel Narratives: July 14th Through The Eyes Of CNN, MSNOW & Fox News
As we continue our series on parallel media narrative universes, yesterday's coverage on CNN, Fox News and MSNOW as usual…
Media Trends Geopolitical Framing: Afghanistan vs Pakistan
Today's Media Trends reports covering yesterday's coverage have a powerful new addition: a new "Geopolitical Framing" section explores how nations…
Adding Geopolitical Framing To Our Media Trends Reports: Narratives On Nations & Leaders
As we continue to explore the kinds of between-the-lines narrative and framing assessment Gemini is capable of, let's explore applying Gemini…
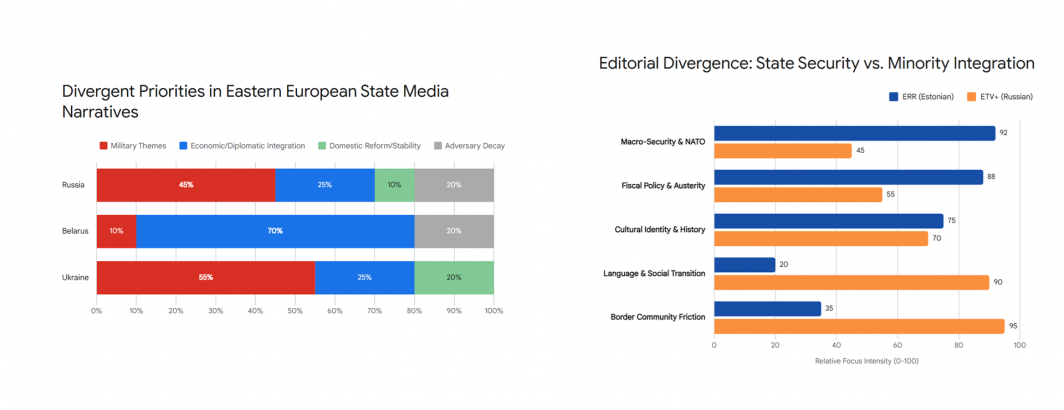
Comparative Media Analysis: Using Gemini Deep Research To Explore A Month Of Russia/Belarusian/Ukrainian & Two Months Of Estonian TV News
Yesterday we used Gemini's Deep Research to explore half a year of Congressional legislative trends and three months of Iranian media….
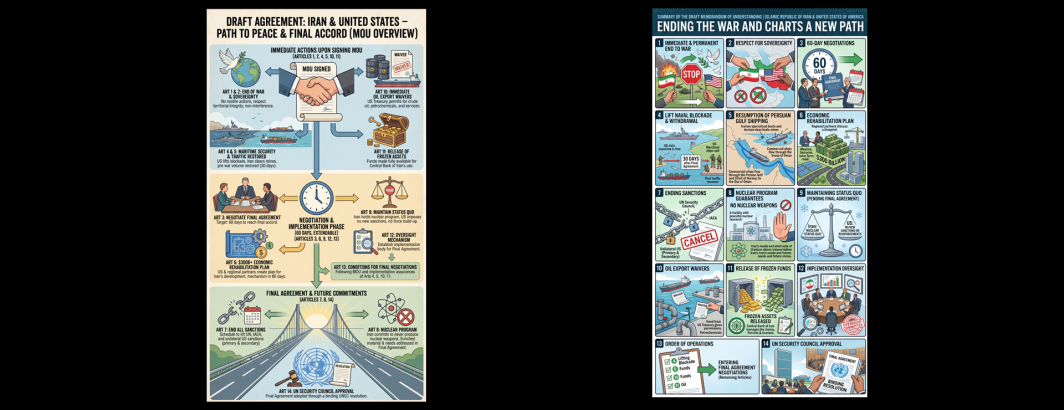
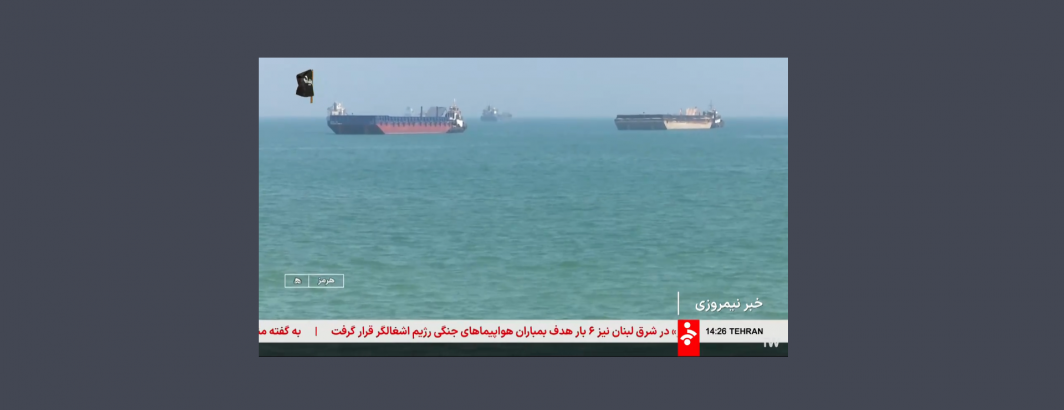
Comparative Media Analysis: Using Gemini Deep Research To Explore Three Months Of Iranian TV News
Earlier today we used Gemini's Deep Research to explore half a year of Congressional legislative trends. Let's repeat this process,…
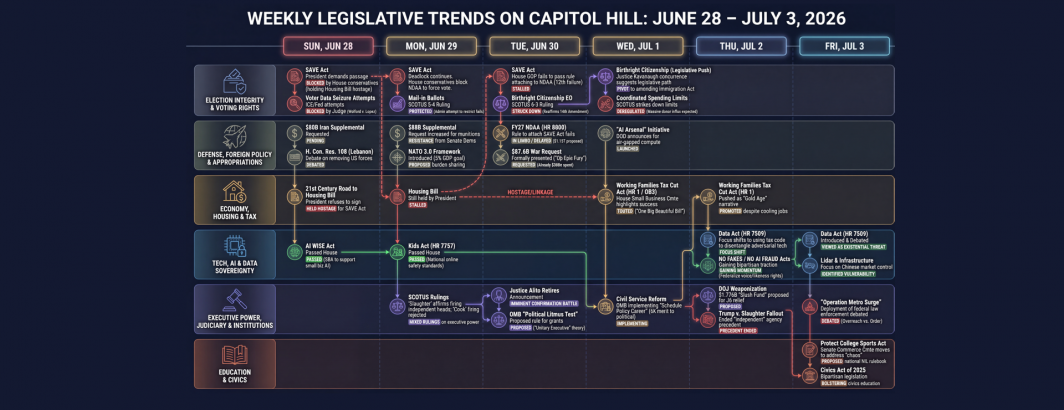
Comparative Media Analysis: Using Gemini Deep Research To Explore Half A Year Of Congressional Legislative Trends
Leveraging our new findings on how Gemini handles PDFs, earlier today we showcased applying Gemini Deep Research to an entire…
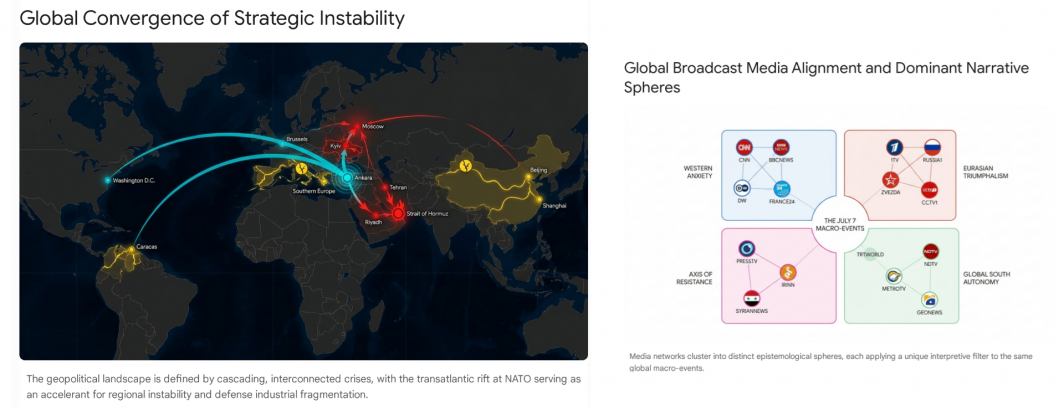
Comparative Media Analysis: Cross-Comparing An Entire Day Of Media Trends Reports Using Gemini Deep Research By Combining The PDF Reports
As we continue to scale up our cross-comparative global media analyses, thus far we've been heavily constrained by the inability…
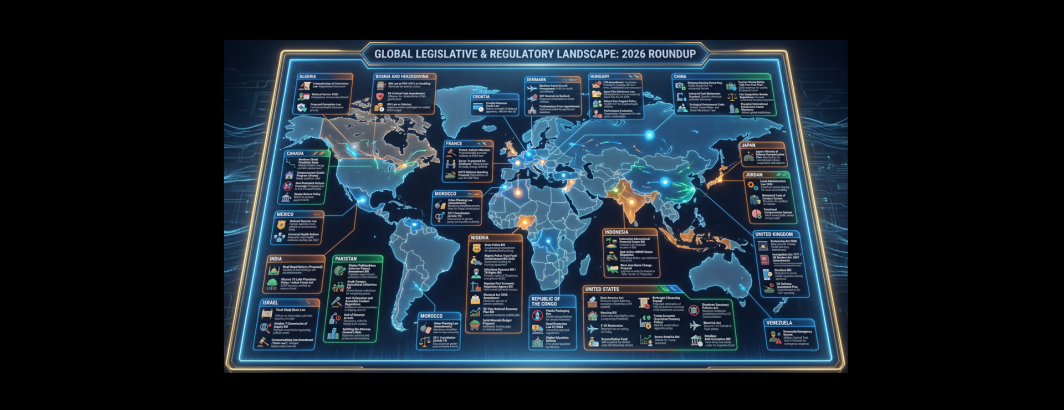
Comparative Media Analysis: Gemini Experiments With PDFs Vs Text For Token Counts Vs Accuracy
As we continue to scale up our comparative media analyses, yesterday we examined how Gemini File Search allowed us to…
Comparative Media Analysis: Experiments With Gemini File Search Comparing One Day Of Global Media Trends Reports
As we continue to scale up our cross-national media analyses, let's explore how Gemini File Search allows us to look…

Visualizing A Trends On Capitol Hill Report As A Claymation Video Using A Gemini Explainer Gem
Last year Google released a set of "Explainer Gems" for Gemini, including one that turns any input into a claymation…

Comparative Media Analysis: First Glimpses At Cross-National Media Comparisons Using Deep Research
Over the last few days we have demonstrated the tremendous potential of applying Gemini's Deep Research capabilities to our daily…

Comparative Media Analysis: A Deep Research Deep Dive On The Parallel Visions Of America On CNN, MSNOW & Fox News
Earlier today we created an infographic montage depicting the parallel visions of America portrayed on CNN, MSNOW and Fox News…
Looking Back On A Week Of The Parallel Visions Of America On CNN, MSNOW & Fox News
What would it look like to visualize the parallel visions of America presented on CNN, MSNOW and Fox News, to…