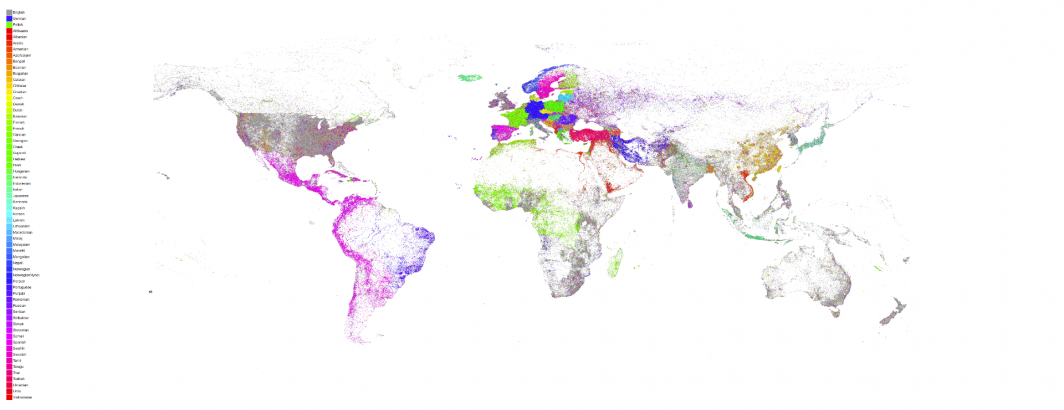
In 2015 we created a map of the linguistic geography of Planet Earth as seen through the eyes of GDELT. For every location worldwide we tallied up every mention GDELT had ever seen of that location, constructed a histogram of the languages of all those articles that mentioned it and then colored the location by the most common language of news coverage that mentioned it. In essence, for any given location on earth, what is the most common language of news coverage that mentions it?
Any location may receive attention from media all across the world in all the world's languages, but there is likely one language that covers that location more than any other. For example, Paris is regularly mentioned by presses in countless countries, but is mentioned in the French language press more than any other language.
Today we've recreated that map, looking over more than 850 million articles in 65 languages spanning nearly four years and 6.6 billion location references. The resulting map shows the incredible richness and diversity of the linguistic geography of Planet Earth.
It also reminds us of just how much of the world we miss when we look only at English. Only through the kind of planetary-scale mass machine translation pioneered by GDELT's Translingual program can we truly begin to see the world through others' eyes.
It also demonstrates once again the incredible power of BigQuery in that we can take 850 million articles and 6.6 billion references and convert them into a visual map in just 45 seconds. GraphViz is used to generate the final visualization.
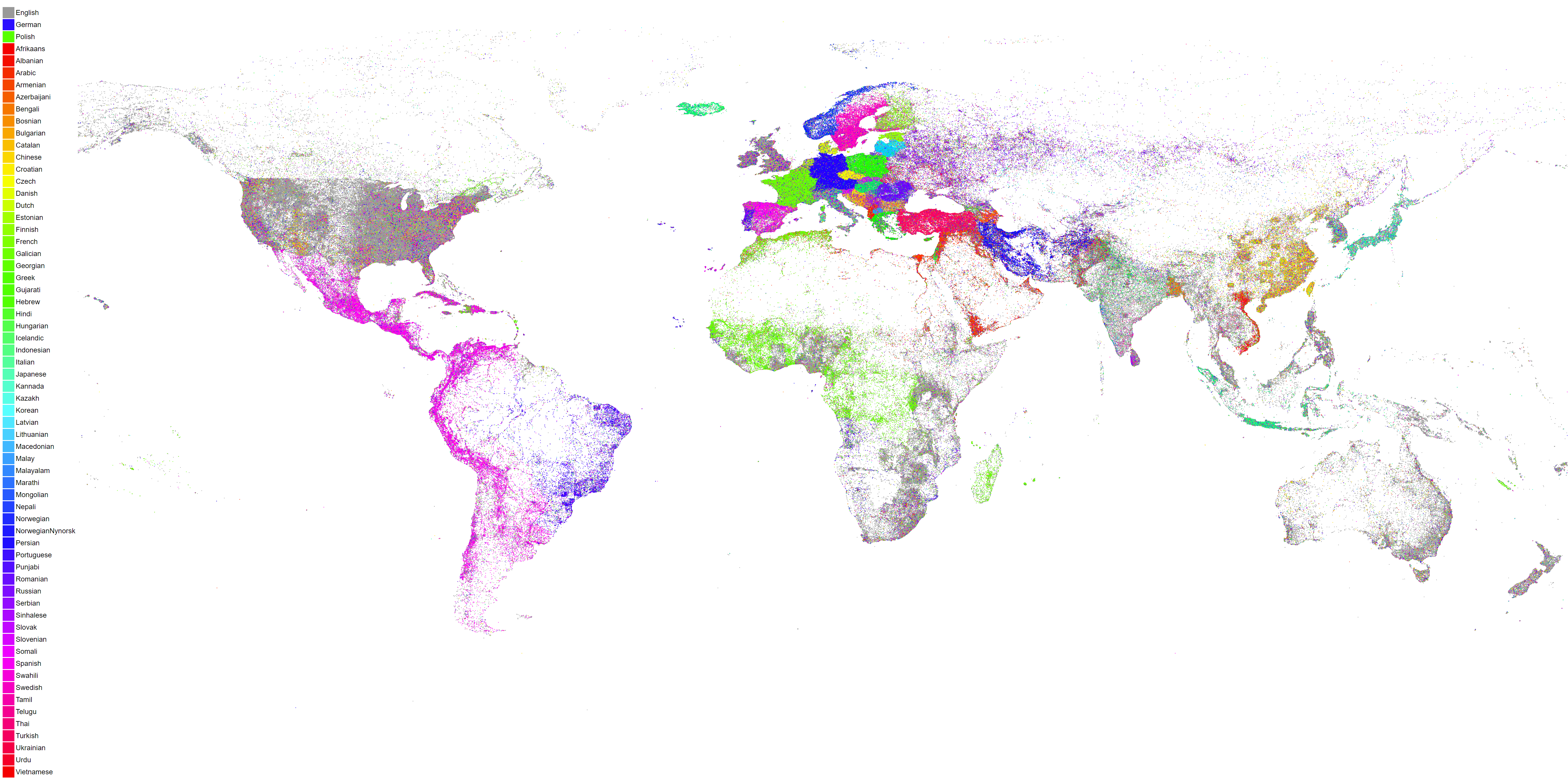
We have several different versions of this map available for download:
- 4K White Background No Legend
- 4K White Background With Legend
- 4K Black Background No Legend
- 4K Black Background With Legend
- 16K White Background No Legend
- 16K White Background With Legend
- 16K Black Background No Legend
- 16K Black Background With Legend
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
TECHNICAL DETAILS
The maps above were created by following largely the same code and workflow as the original 2015 map with a few changes.
The BigQuery SQL query was modified to round to 3 decimals instead of 2 to yield a higher resolution map:
SELECT lat, long, lang, COUNT(*) as numarticles FROM ( select ROUND(FLOAT(REGEXP_EXTRACT(SPLIT(V2Locations,';'),r'^[2-5]#.*?#.*?#.*?#.*?#(.*?)#.*?#')), 3) as lat, ROUND(FLOAT(REGEXP_EXTRACT(SPLIT(V2Locations,';'),r'^[2-5]#.*?#.*?#.*?#.*?#.*?#(.*?)#')), 3) as long, REGEXP_EXTRACT(TranslationInfo, 'srclc:(.*?);') as lang from [gdelt-bq:gdeltv2.gkg] ) where lat is not null and long is not null group by lat,long, lang
The two PERL scripts were also changed into "computetoplangbyloc_new.pl" and "bqcsvtomap_withlang_new.pl". Like the original map, you run the BigQuery SQL above, save the results to a new table and then export them to a CSV file. Download the CSV file to local disk and call it something like "results.csv". Download the rest of the files as described in the original blog post. Then run the preprocessing PERL script like "./computetoplangbyloc_new.pl ./results.csv". It will generate an outfile file called "./results.csv.LOCSBYLANDS.TXT".
The rendering script that actually generates the map ("bqcsvtomap_withlang_new.pl") has been changed to accept several parameters on the command line. You now run it as "./bqcsvtomap_withlang_new.pl WIDTH HEIGHT BACKGROUNDCOLOR INPUTFILE OUTPUTIMAGE". The WIDTH and HEIGHT parameters are expressed in pixels. Typical values are "4000 2000" and "12288 6144". Note that the specified pixel sizes will typically be modified by the rendering engine when it runs. The INPUTFILE is the output file generated by the "computetoplangbyloc_new.pl" preprocessing script and OUTPUTIMAGE is the filename of the final PNG image to generate.
To create the maps above the following commands were used:
- ./bqcsvtomap_withlang_new.pl 4000 2000 FFFFFF ./results.csv.LOCSBYLANGS.TXT white-4k.png
- ./bqcsvtomap_withlang_new.pl 12288 6144 FFFFFF ./results.csv.LOCSBYLANGS.TXT white-16k.png
- ./bqcsvtomap_withlang_new.pl 4000 2000 000000 ./results.csv.LOCSBYLANGS.TXT black-4k.png
- ./bqcsvtomap_withlang_new.pl 12288 6144 000000 ./results.csv.LOCSBYLANGS.TXT black-16k.png
Finally, the legends were composited on top of the images in Photoshop using the prerendered PNG images from the original blog post.