
Last month we demonstrated searching a year of Russian television news' 60 Minutes to find all appearances of Tucker Carlson. That search took more than 4 hours on a dedicated 64-core VM to run, making it intractable to run interactively. Earlier today we unveiled a database of all 774,615 face embeddings computed from those shows that can be used to perform near-realtime and eventually realtime interactive facial search over the entire archive. Let's explore this by cataloging all appearances of Ukrainian President Volodymyr Zelenskyy on 60 Minutes over the past year in just 19 seconds on a single processor.
In all, 332 of the 342 broadcasts contained at least one image of Zelenskyy totaling 13,064 visual ngrams over 3,479 Clips representing 871 minutes (14.5 hours of airtime). In all, 97% of 60 Minutes episodes over the past year depicted Zelenskyy, totaling 1.72% of its total airtime, reflecting just how much Russian media fixates on him.
You can see a complete montage of all 13,064 frames in the video below, both capturing the sheer extent of Russian television's visual narrative of an exhausted and haggard ordinary man pleading for help (in comparison to its typical depictions of Putin in a sharp suit in the gilded Kremlin) and showcasing the immense power of this workflow in recognizing even minute heavily filtered brief glimpses of his face in the background of the studio.
Download the video. (NOTE: 500MB)
Here are a few of his appearances in context:
-
- RUSSIA1: 05/24/2022 09:00:36 UTC (Frame: 000460) (Dist: 0.38)
- RUSSIA1: 06/28/2022 08:45:28 UTC (Frame: 000233) (Dist: 0.50)
- RUSSIA1: 06/28/2022 08:57:24 UTC (Frame: 000412) (Dist: 0.45)
- RUSSIA1: 06/28/2022 09:17:40 UTC (Frame: 000716) (Dist: 0.36)
- RUSSIA1: 06/28/2022 09:19:08 UTC (Frame: 000738) (Dist: 0.46)
- RUSSIA1: 06/28/2022 09:32:44 UTC (Frame: 000942) (Dist: 0.41)
You can download the complete list of matches:
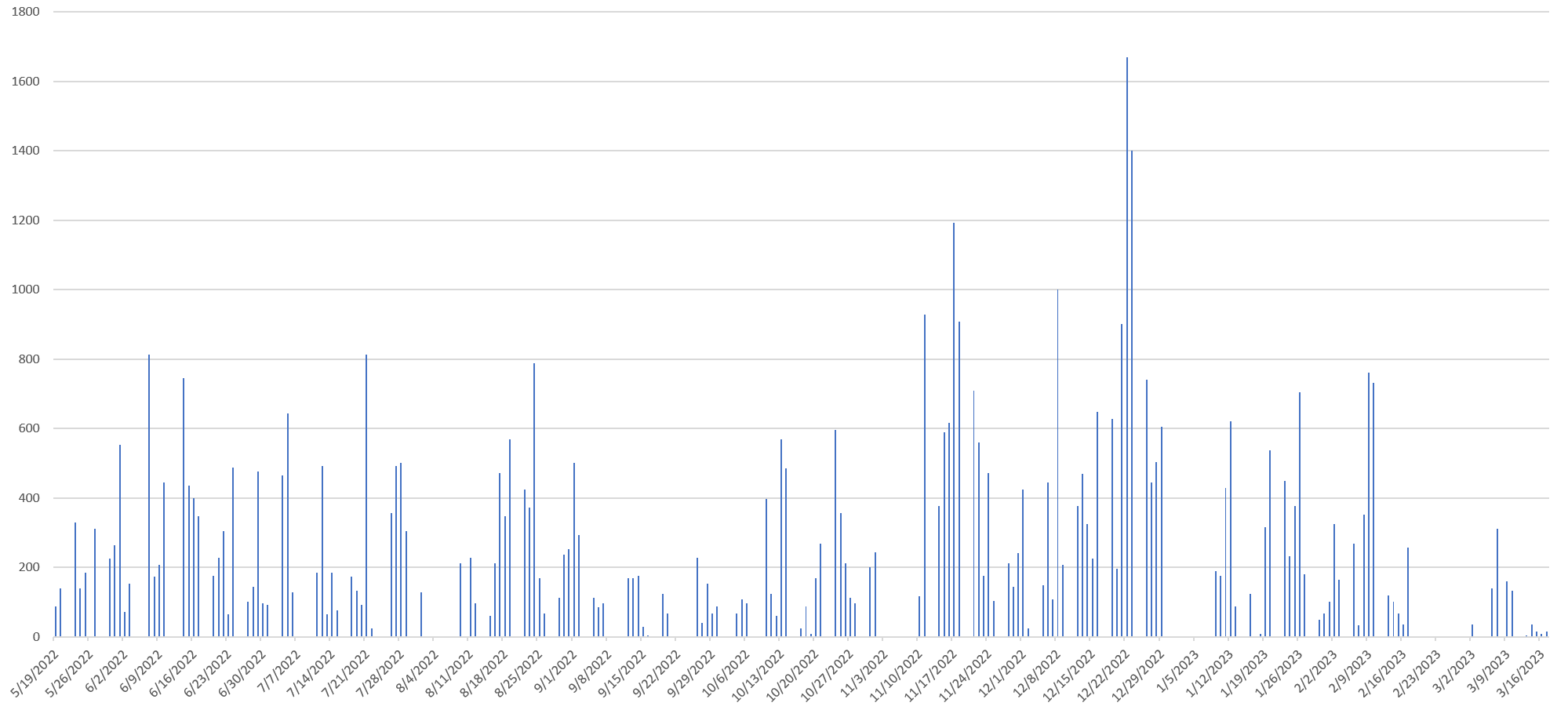
Below you can see a timeline of the total daily seconds of airtime on 60 Minutes over the past year containing his face. Note that the show does not air on weekends and there were several outages in the Internet Archive's TV News Archive's archive of 60 Minutes, including in February 2023 that explain the blank periods in the timeline below. There is a period of systematically lowered appearance of his face in September/October 2022, followed by a period of elevated appearance in November/December 2022.
The facial scanning tool is powerful enough to recognize a filtered image like the one below where Zelenskyy's face is softened with a slight blur filter, had its contrast severely reduced and turned into a greyscale blue image:

Similarly, amidst the sea of faces in the image below that most human analysts would likely skim right over, it picks up on his softened, saturated and shadowed face hidden and partially obscured in the lower-left behind one of the speakers.

What does the technical workflow look like to create this montage and how do we leverage the massive embeddings dataset we released earlier today?
First we'll install a set of dependencies:
apt-get -y install pigz apt-get -y install wget apt-get -y install build-essential brew install cmake pip3 install face_recognition pip3 install scikit-learn
Now we'll download the complete May 19, 2022 – March 18, 2023 face embedding database we released earlier today, unpack it and rename it to DATABASE.json:
wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/FACEEMBED-60MINUTES-20220519-20230318.json.gz pigz -d ./FACEEMBED-60MINUTES-20220519-20230318.json.gz mv FACEEMBED-60MINUTES-20220519-20230318.json DATABASE.json
Now we'll rehydrate it as a massive pickle file, renaming a number of the fields into what the face_recognition library is expecting.
Save the following script to "json_to_pickle.py":
import json
import pickle
import numpy as np
merged = []
with open('./DATABASE.json', encoding='utf-8') as fh:
for line in fh:
obj = json.loads(line)
merged.append({'faceID': obj['faceid'], 'imagePath': obj['image'], 'loc': (obj["box"][0], obj["box"][1], obj["box"][2], obj["box"][3]), 'encoding': np.array(obj["encoding"])})
fh = open("./DATABASE.pickle", "wb")
fh.write(pickle.dumps(merged))
fh.close()
And run as:
time python3 ./json_to_pickle.py
This will take around 1 minute and 5GB of RAM to load the entire JSON file, reformat it and save to a single monolithic pickle file.
At this point we're ready to use this pickle file as an embeddings database to scan against a known set of faces. For the Tucker Carlson analysis, we used the face_recognition package, which accepts a directory of known images and scans a directory of unknown images, extracting all faces, building embeddings for each and comparing them against the known images. We're going to take that tool and modify it slightly so that instead of extracting and computing embeddings for a directory of unknown images, it will use our precomputed embedding database. Thus, it will need to compute an embedding only for the single known image of Zelenskyy. The core of its computation will simply be scoring the distance between simple 128-dimension vectors.
We're going to use the original face_recognition_cli.py as our base and modify it slightly to use our database.
Copy the script below and name it as face_recognition_db.py:
from imutils import paths
import face_recognition
import click
import re
import pickle
import cv2
import os
from constants import ENCODINGS_PATH
import multiprocessing
import itertools
import sys
def scan_known_people(known_people_folder):
known_names = []
known_face_encodings = []
for file in image_files_in_folder(known_people_folder):
basename = os.path.splitext(os.path.basename(file))[0]
img = face_recognition.load_image_file(file)
encodings = face_recognition.face_encodings(img)
if len(encodings) > 1:
click.echo("WARNING: More than one face found in {}. Only considering the first face.".format(file))
if len(encodings) == 0:
click.echo("WARNING: No faces found in {}. Ignoring file.".format(file))
else:
known_names.append(basename)
known_face_encodings.append(encodings[0])
return known_names, known_face_encodings
def image_files_in_folder(folder):
return [os.path.join(folder, f) for f in os.listdir(folder) if re.match(r'.*\.(jpg|jpeg|png)', f, flags=re.I)]
def print_result(filename, name, distance, show_distance=False):
if show_distance:
print("{},{},{}".format(filename["imagePath"], name, distance))
else:
print("{},{}".format(filename, name))
def test_image(image_to_check, known_names, known_face_encodings, tolerance=0.6, show_distance=False):
distances = face_recognition.face_distance(known_face_encodings, image_to_check["encoding"])
result = list(distances <= tolerance)
if True in result:
[print_result(image_to_check, name, distance, show_distance) for is_match, name, distance in zip(result, known_names, distances) if is_match]
def imagesindb(db):
return pickle.loads(open(db, "rb").read())
def process_images_in_process_pool(images_to_check, known_names, known_face_encodings, number_of_cpus, tolerance, show_distance):
if number_of_cpus == -1:
processes = None
else:
processes = number_of_cpus
# macOS will crash due to a bug in libdispatch if you don't use 'forkserver'
context = multiprocessing
if "forkserver" in multiprocessing.get_all_start_methods():
context = multiprocessing.get_context("forkserver")
pool = context.Pool(processes=processes)
function_parameters = zip(
images_to_check,
itertools.repeat(known_names),
itertools.repeat(known_face_encodings),
itertools.repeat(tolerance),
itertools.repeat(show_distance)
)
pool.starmap(test_image, function_parameters)
@click.command()
@click.argument('known_people_folder')
@click.argument('image_to_check')
@click.option('--cpus', default=1, help='number of CPU cores to use in parallel (can speed up processing lots of images). -1 means "use all in system"')
@click.option('--tolerance', default=0.6, help='Tolerance for face comparisons. Default is 0.6. Lower this if you get multiple matches for the same person.')
@click.option('--show-distance', default=False, type=bool, help='Output face distance. Useful for tweaking tolerance setting.')
def main(known_people_folder, image_to_check, cpus, tolerance, show_distance):
known_names, known_face_encodings = scan_known_people(known_people_folder)
# Multi-core processing only supported on Python 3.4 or greater
if (sys.version_info < (3, 4)) and cpus != 1:
click.echo("WARNING: Multi-processing support requires Python 3.4 or greater. Falling back to single-threaded processing!")
cpus = 1
if cpus == 1:
[test_image(image_file, known_names, known_face_encodings, tolerance, show_distance) for image_file in imagesindb(image_to_check)]
else:
process_images_in_process_pool(imagesindb(image_to_check), known_names, known_face_encodings, cpus, tolerance, show_distance)
if __name__ == "__main__":
main()
Now download Zelenskyy's official portrait to create our "known" database of persons to scan the database against:
mkdir KNOWN wget https://upload.wikimedia.org/wikipedia/commons/9/9c/Volodymyr_Zelensky_Official_portrait.jpg mv Volodymyr_Zelensky_Official_portrait.jpg KNOWN/VolodymyrZelensky.png
And finally run the search:
time python3 ./face_recognition_db.py --cpus 1 --tolerance 0.52 --show-distance true ./KNOWN/ ./DATABASE.pickle > 60MINUTES-20220326-20230317-face_recog-ZELENSKYY.TXT; wc -l 60MINUTES-20220326-20230317-face_recog-ZELENSKYY.TXT
This will take just around 20 seconds on a single core. Due to the limitations of Python's multiprocessing capabilities as used in the original script and the speed at which the vector distance calculation runs, using additional cores, such as setting "–cpus -1" to use all cores will actually result either in a slowdown or a speedup of just 1-2 seconds, even on a 64-core system, as Python is unable to parallelize sharding of the source file and instead serializes the passing of each line to all of the processes.
Let's make a movie of the results:
apt-get -y install ffmpeg cut -d ',' -f1 60MINUTES-20220326-20230317-face_recog-ZELENSKYY.TXT > IMAGES.TXT time cat $(cat IMAGES.TXT) | ffmpeg -framerate 5 -i - -vcodec libx264 -vf "pad=ceil(iw/2)*2:ceil(ih/2)*2" -y ./ZELENSKYY-60MINUTES-20220326-20230317.mp4
From more than 4 hours across 64 cores to just 19 seconds on a single core, we are now able to scan a year of 60 Minutes episodes in just a handful of seconds to catalog all of the appearances of Zelenskyy.
Could we speed this up even further, potentially to actual realtime search? Last year ElasticSearch introduced approximate nearest neighbor (ANN) search, which allows efficient realtime vector search at very large scale. Using the latest ElasticSearch version, you could simply load the original DATABASE.json file above into ElasticSearch with an ANN index and create an interactive website where you could upload a face via a web form and get back a complete list of every appearance of that face across all of Russian television in a fraction of a second. For even greater scalability, Google's Vertex AI Matching Engine supports true realtime subsecond searching across extreme QPS service levels over billion-vector databases, enabling production search at enormous scale.