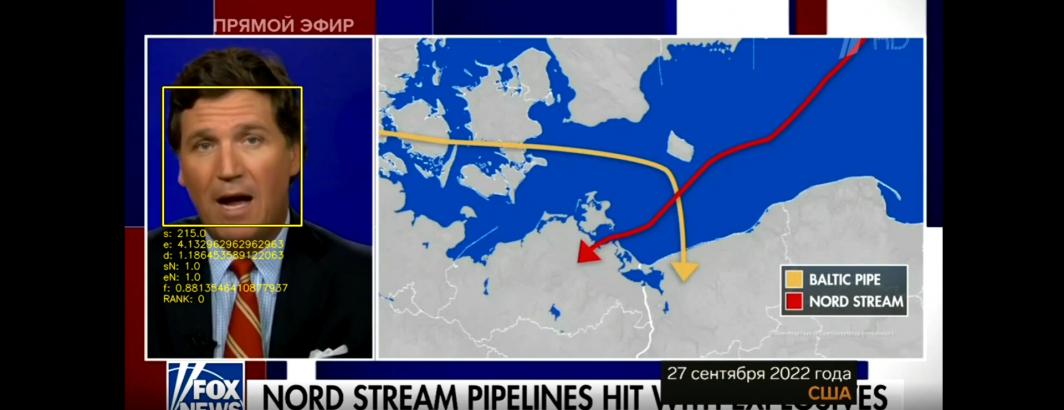
Last month, in collaboration with the Internet Archive's TV News Archive, we demonstrated scanning a year of Russia1's "60 Minutes" for all appearances of Tucker Carlson. Let's repeat that analysis with a more advanced tool that also generates a distance score of the extracted face compared with the source face, allowing us to post-filter to remove false positives, identify the strongest matches, etc. Here we analyze all 342 episodes of 60 Minutes archived by the Archive from May 19, 2022 to March 17, 2023, totaling 757,559 images representing 50,504 minutes of airtime. Of those images, 237,551 (31.4%) were identified as containing no human faces, meaning almost two-thirds of 60 Minutes' airtime over the past year contained at least one human face – a reminder of the importance of faces to television news. In total, 760,887 unknown faces and 1,921 faces identified as Tucker Carlson were identified.
First, we'll install a few helper apps we'll need:
apt-get -y install parallel apt-get -y install jq
Now we'll download the inventory file of all of the Russia 1 shows archived by the Archive and compile just the 60 Minutes episodes (NOTE that since the Archive's EPG data for Russia 1 does not begin until May 2022, we'll miss the first two months of broadcasts):
start=20220101; end=20230318; while [[ ! $start > $end ]]; do echo $start; start=$(date -d "$start + 1 day" "+%Y%m%d"); done > DATES
mkdir JSON
time cat DATES | parallel --eta 'wget -q https://storage.googleapis.com/data.gdeltproject.org/gdeltv3/iatv/visualexplorer/RUSSIA1.{}.inventory.json -P ./JSON/'
rm IDS.tmp; find ./JSON/ -depth -name '*.json' | parallel --eta 'cat {} | jq -r .shows[].id >> IDS.tmp'
grep '60_minut' IDS.tmp | sort > IDS
Now we'll download all of the video ngram files for these broadcasts and unpack them (given the number of small files this is best done in a RAM disk on a large-memory VM):
mkdir IMAGES
time cat IDS | parallel --eta 'wget -q https://storage.googleapis.com/data.gdeltproject.org/gdeltv3/iatv/visualexplorer/{}.zip -P ./IMAGES/'
time find ./IMAGES/ -depth -name '*.zip' | parallel --eta 'unzip -n -q -d ./IMAGES/ {} && rm {}'
time find ./IMAGES/ -depth -name "*.jpg" | wc -l
Now we'll download a package called "face_recognition":
apt-get -y install build-essential brew install cmake pip3 install face_recognition
Create a subdirectory called "KNOWN" that contains one image of each of the faces you wish to search for, with the filename you want to appear as the recognized face. Here we'll download our Tucker Carlson face:
mkdir KNOWN wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/2022-tve-facedetect-scan-tuckerface.png mv 2022-tve-facedetect-scan-tuckerface.png KNOWN/TuckerCarlson.png
You can have multiple faces in the KNOWN directory, allowing you to search for multiple faces at once in a single pass.
The off-the-shelf CLI tool called "face_recognition" requires a single flat directory of images, rather than nested subdirectories, so rather than modify the script, we'll simply move all of the images to a single directory:
mkdir FRAMES
time find ./IMAGES/ -depth -type d -name 'RUSS*' | parallel --eta 'mv {}/*.jpg ./FRAMES'
Then, running advanced facial recognition over the entire archive requires just a single command:
time face_recognition --cpus -1 --show-distance true --tolerance 0.52 ./KNOWN/ ./FRAMES/ > RESULTS.ALL.TXT&
We used a 64-core CPU-only VM with 400GB of RAM, allowing a 200GB RAM disk to maximize IO. Here we set the "cpus" parameter to "-1" to use all 64 cores.
Based on several small-scale initial tests, we discovered that distance scores (how "dissimilar" the face is from the example face – a lower score means they are more similar) of more than 0.52 were exclusively false positives, so we set tolerance to 0.52 (only faces with distance equal to or lower than this are kept) and use "show-distance" to record all distances. In all, this takes just over 4 hours to complete.
This produces a massive CSV file of 1 million lines with 3 columns (filename, identified face, distance of the face from the example face). For each frame if no faces were found it appears on a single line with "no_persons_found". For each identified face, the frame will be listed on a line with either "unknown_person" or "TuckerCarlson". If four faces are found in a given frame, it will appear four times in the file. Note that for unknown reasons (likely due to a multiprocess issue), a handful of lines are corrupt, with two lines concatenated together. For faces identified as matching Tucker Carlson, the last column will contain the distance score of the face from the Tucker Carlson example.
You can download the complete file:
Here we extract and sort just the Tucker Carlson matches:
grep Tucker RESULTS.ALL.TXT | sort > 60MINUTES-20220326-20230314-face_recog-TUCKERCARLSON.TXT
This yields the final list of Tucker Carlson matches:
The more sophisticated facial extraction and recognition workflow used here reduces the false positive rate of our earlier example. Most importantly, the addition of the distance scores in the third column makes it possible now to post-filter the results to remove any final false positives by simply filtering the CSV file by a lower threshold, rather than reprocessing the entire image archive.
Process the full list of frame-level matches into distinct "clips" using a simple PERL script:
#!/usr/bin/perl
use POSIX qw(strftime);
use Time::timegm qw( timegm );
open(FILE, $ARGV[0]);
while(<FILE>) {
($image, $name, $dist) = split/,/, $_; $dist+=0; if ($dist > $ARGV[1]) { next; }; ($ID, $FRAME) = $image=~/^(.*?)\-(\d+)\.jpg/;
($year, $mon, $day) = $ID=~/_(\d\d\d\d)(\d\d)(\d\d)/; $TIMELINE{"$mon/$day/$year"}++;
if ($ID ne $LASTID || ($FRAME - $LASTFRAME) > 4) {
($CHAN) = $ID=~/^(.*?)_\d\d\d\d/;
($year, $mon, $day, $hour, $min, $sec) = $ID=~/(\d\d\d\d)(\d\d)(\d\d)_(\d\d)(\d\d)(\d\d)/;
$timestamp = timegm( $sec, $min, $hour, $day, $mon-1, $year-1900 ) + ( ($FRAME - 1) * 4);
$date = strftime('%m/%d/%Y %H:%M:%S', gmtime($timestamp));
$dist = sprintf("%0.2f", $dist);
print "<li><a href=\"https://api.gdeltproject.org/api/v2/tvv/tvv?id=$ID&play=$timestamp\" TARGET=_BLANK>$CHAN: $date UTC (Frame: $FRAME) (Dist: $dist)</A></li>\n";
$CLIPS++;
}
$LASTID = $ID;
$LASTFRAME = $FRAME;
$UNIQ_IDS{$ID}++;
$TOTFRAMES++;
}
close(FILE);
open(OUT, ">./TIMELINE.TXT");
foreach $key (keys %TIMELINE) { print OUT "$key\t$TIMELINE{$key}\n"; };
close(OUT);
$sec = $TOTFRAMES * 4;
$cnt = scalar(keys %UNIQ_IDS); print "Found $cnt IDs & $CLIPS Clips & $TOTFRAMES Frames = $sec seconds...\n";
Which is run as (retaining our current distance threshold of 0.52):
./makeintoclips.pl ./60MINUTES-20220326-20230314-face_recog-TUCKERCARLSON.TXT 0.52
We can see that while this removes some of the false positives from our previous analysis, it still leaves ones like this one in which one of the angry Biden images in the background is conflated as a Tucker Carlson image:
Looking up that entry in the "60MINUTES-20220326-20230314-face_recog-TUCKERCARLSON.TXT" we can see that it has a score of 0.494917665824298, which is right at the extreme of our threshold. Let's reduce the cutoff a bit to 0.50:
./makeintoclips.pl ./60MINUTES-20220326-20230314-face_recog-TUCKERCARLSON.TXT 0.50
This may remove some genuine matches, but also reduces false positives. Of course, you can use grep to see what matches would be removed at each threshold to fine-tune the cutoff:
./parse_facematch.pl ./60MINUTES-20220326-20230314-face_recog-TUCKERCARLSON.TXT 0.50 | grep '0.50)'
Here are the final matches using 0.50 as a cutoff, matching 91 distinct episodes across 185 Clips totaling 1890 Frames representing 7560 seconds of airtime:
- RUSSIA1: 05/19/2022 10:06:00 UTC (Frame: 001441) (Dist: 0.39)
- RUSSIA1: 05/19/2022 10:08:28 UTC (Frame: 001478) (Dist: 0.33)
- RUSSIA1: 05/19/2022 10:55:52 UTC (Frame: 002189) (Dist: 0.42)
- RUSSIA1: 05/19/2022 16:43:48 UTC (Frame: 002008) (Dist: 0.39)
- RUSSIA1: 05/19/2022 16:45:40 UTC (Frame: 002036) (Dist: 0.47)
- RUSSIA1: 06/03/2022 10:06:36 UTC (Frame: 001450) (Dist: 0.45)
- RUSSIA1: 06/03/2022 16:07:24 UTC (Frame: 001462) (Dist: 0.50)
- RUSSIA1: 06/20/2022 08:52:32 UTC (Frame: 000339) (Dist: 0.37)
- RUSSIA1: 06/20/2022 09:31:04 UTC (Frame: 000917) (Dist: 0.43)
- RUSSIA1: 06/20/2022 09:31:32 UTC (Frame: 000924) (Dist: 0.45)
- RUSSIA1: 06/20/2022 09:35:16 UTC (Frame: 000980) (Dist: 0.40)
- RUSSIA1: 06/20/2022 14:47:36 UTC (Frame: 000265) (Dist: 0.45)
- RUSSIA1: 06/20/2022 16:06:16 UTC (Frame: 001445) (Dist: 0.43)
- RUSSIA1: 06/20/2022 16:07:04 UTC (Frame: 001457) (Dist: 0.36)
- RUSSIA1: 06/20/2022 16:32:48 UTC (Frame: 001843) (Dist: 0.44)
- RUSSIA1: 06/24/2022 14:50:32 UTC (Frame: 000309) (Dist: 0.34)
- RUSSIA1: 06/24/2022 14:50:56 UTC (Frame: 000315) (Dist: 0.34)
- RUSSIA1: 06/24/2022 14:51:32 UTC (Frame: 000324) (Dist: 0.43)
- RUSSIA1: 06/28/2022 08:45:24 UTC (Frame: 000232) (Dist: 0.40)
- RUSSIA1: 07/11/2022 08:45:56 UTC (Frame: 000240) (Dist: 0.37)
- RUSSIA1: 07/11/2022 14:53:48 UTC (Frame: 000358) (Dist: 0.37)
- RUSSIA1: 07/11/2022 16:03:32 UTC (Frame: 001404) (Dist: 0.42)
- RUSSIA1: 07/13/2022 10:05:48 UTC (Frame: 001438) (Dist: 0.36)
- RUSSIA1: 07/13/2022 10:07:28 UTC (Frame: 001463) (Dist: 0.37)
- RUSSIA1: 07/14/2022 08:44:40 UTC (Frame: 000221) (Dist: 0.43)
- RUSSIA1: 07/18/2022 10:06:04 UTC (Frame: 001442) (Dist: 0.48)
- RUSSIA1: 07/18/2022 14:49:16 UTC (Frame: 000290) (Dist: 0.44)
- RUSSIA1: 07/18/2022 14:49:40 UTC (Frame: 000296) (Dist: 0.47)
- RUSSIA1: 07/18/2022 16:03:40 UTC (Frame: 001406) (Dist: 0.44)
- RUSSIA1: 07/22/2022 08:56:08 UTC (Frame: 000393) (Dist: 0.46)
- RUSSIA1: 07/22/2022 14:58:12 UTC (Frame: 000424) (Dist: 0.45)
- RUSSIA1: 07/22/2022 15:03:04 UTC (Frame: 000497) (Dist: 0.40)
- RUSSIA1: 07/29/2022 14:52:32 UTC (Frame: 000339) (Dist: 0.41)
- RUSSIA1: 07/29/2022 14:53:52 UTC (Frame: 000359) (Dist: 0.40)
- RUSSIA1: 08/09/2022 16:04:36 UTC (Frame: 001420) (Dist: 0.42)
- RUSSIA1: 09/05/2022 08:59:16 UTC (Frame: 000440) (Dist: 0.43)
- RUSSIA1: 09/05/2022 16:08:32 UTC (Frame: 001479) (Dist: 0.41)
- RUSSIA1: 09/27/2022 08:59:08 UTC (Frame: 000438) (Dist: 0.39)
- RUSSIA1: 09/27/2022 15:06:00 UTC (Frame: 000541) (Dist: 0.40)
- RUSSIA1: 09/28/2022 10:52:20 UTC (Frame: 002136) (Dist: 0.40)
- RUSSIA1: 09/28/2022 14:44:20 UTC (Frame: 000216) (Dist: 0.41)
- RUSSIA1: 09/28/2022 14:45:16 UTC (Frame: 000230) (Dist: 0.43)
- RUSSIA1: 09/28/2022 14:46:12 UTC (Frame: 000244) (Dist: 0.36)
- RUSSIA1: 09/28/2022 14:48:56 UTC (Frame: 000285) (Dist: 0.46)
- RUSSIA1: 09/28/2022 16:42:44 UTC (Frame: 001992) (Dist: 0.48)
- RUSSIA1: 09/29/2022 09:31:40 UTC (Frame: 000926) (Dist: 0.35)
- RUSSIA1: 09/29/2022 10:18:12 UTC (Frame: 001624) (Dist: 0.37)
- RUSSIA1: 09/29/2022 16:19:48 UTC (Frame: 001648) (Dist: 0.37)
- RUSSIA1: 10/04/2022 08:50:12 UTC (Frame: 000304) (Dist: 0.36)
- RUSSIA1: 10/04/2022 10:15:56 UTC (Frame: 001590) (Dist: 0.43)
- RUSSIA1: 10/04/2022 14:57:00 UTC (Frame: 000406) (Dist: 0.41)
- RUSSIA1: 10/04/2022 16:11:20 UTC (Frame: 001521) (Dist: 0.42)
- RUSSIA1: 10/05/2022 10:20:56 UTC (Frame: 001665) (Dist: 0.42)
- RUSSIA1: 10/05/2022 15:45:08 UTC (Frame: 001128) (Dist: 0.45)
- RUSSIA1: 10/05/2022 16:17:52 UTC (Frame: 001619) (Dist: 0.45)
- RUSSIA1: 10/06/2022 08:43:52 UTC (Frame: 000209) (Dist: 0.40)
- RUSSIA1: 10/14/2022 14:57:12 UTC (Frame: 000409) (Dist: 0.42)
- RUSSIA1: 10/14/2022 14:58:40 UTC (Frame: 000431) (Dist: 0.42)
- RUSSIA1: 10/26/2022 15:21:36 UTC (Frame: 000775) (Dist: 0.37)
- RUSSIA1: 10/27/2022 09:21:16 UTC (Frame: 000770) (Dist: 0.38)
- RUSSIA1: 10/27/2022 09:23:16 UTC (Frame: 000800) (Dist: 0.46)
- RUSSIA1: 10/27/2022 09:30:40 UTC (Frame: 000911) (Dist: 0.45)
- RUSSIA1: 10/31/2022 09:42:20 UTC (Frame: 001086) (Dist: 0.49)
- RUSSIA1: 10/31/2022 09:42:52 UTC (Frame: 001094) (Dist: 0.49)
- RUSSIA1: 10/31/2022 10:07:44 UTC (Frame: 001467) (Dist: 0.39)
- RUSSIA1: 10/31/2022 10:09:00 UTC (Frame: 001486) (Dist: 0.41)
- RUSSIA1: 10/31/2022 10:49:48 UTC (Frame: 002098) (Dist: 0.41)
- RUSSIA1: 10/31/2022 10:50:20 UTC (Frame: 002106) (Dist: 0.40)
- RUSSIA1: 10/31/2022 14:53:08 UTC (Frame: 000348) (Dist: 0.38)
- RUSSIA1: 10/31/2022 14:53:48 UTC (Frame: 000358) (Dist: 0.40)
- RUSSIA1: 10/31/2022 16:08:56 UTC (Frame: 001485) (Dist: 0.45)
- RUSSIA1: 10/31/2022 16:10:00 UTC (Frame: 001501) (Dist: 0.44)
- RUSSIA1: 11/11/2022 09:54:40 UTC (Frame: 001271) (Dist: 0.37)
- RUSSIA1: 11/11/2022 14:40:20 UTC (Frame: 000156) (Dist: 0.34)
- RUSSIA1: 11/14/2022 16:00:20 UTC (Frame: 001356) (Dist: 0.44)
- RUSSIA1: 11/17/2022 10:56:04 UTC (Frame: 002192) (Dist: 0.46)
- RUSSIA1: 11/17/2022 14:44:40 UTC (Frame: 000221) (Dist: 0.43)
- RUSSIA1: 11/17/2022 16:31:52 UTC (Frame: 001829) (Dist: 0.39)
- RUSSIA1: 11/18/2022 08:37:24 UTC (Frame: 000112) (Dist: 0.44)
- RUSSIA1: 11/22/2022 08:52:08 UTC (Frame: 000333) (Dist: 0.49)
- RUSSIA1: 11/25/2022 10:10:28 UTC (Frame: 001508) (Dist: 0.36)
- RUSSIA1: 11/25/2022 16:40:52 UTC (Frame: 001964) (Dist: 0.40)
- RUSSIA1: 11/28/2022 10:03:56 UTC (Frame: 001410) (Dist: 0.46)
- RUSSIA1: 11/28/2022 10:05:56 UTC (Frame: 001440) (Dist: 0.31)
- RUSSIA1: 11/30/2022 08:51:52 UTC (Frame: 000329) (Dist: 0.26)
- RUSSIA1: 11/30/2022 14:54:16 UTC (Frame: 000365) (Dist: 0.30)
- RUSSIA1: 12/01/2022 10:11:12 UTC (Frame: 001519) (Dist: 0.41)
- RUSSIA1: 12/08/2022 10:08:36 UTC (Frame: 001480) (Dist: 0.35)
- RUSSIA1: 12/08/2022 14:50:08 UTC (Frame: 000303) (Dist: 0.33)
- RUSSIA1: 12/08/2022 14:51:08 UTC (Frame: 000318) (Dist: 0.42)
- RUSSIA1: 12/08/2022 15:14:20 UTC (Frame: 000666) (Dist: 0.35)
- RUSSIA1: 12/12/2022 08:49:20 UTC (Frame: 000291) (Dist: 0.35)
- RUSSIA1: 12/13/2022 08:36:08 UTC (Frame: 000093) (Dist: 0.36)
- RUSSIA1: 12/13/2022 14:59:44 UTC (Frame: 000447) (Dist: 0.37)
- RUSSIA1: 12/13/2022 15:00:24 UTC (Frame: 000457) (Dist: 0.50)
- RUSSIA1: 12/15/2022 09:02:04 UTC (Frame: 000482) (Dist: 0.35)
- RUSSIA1: 12/15/2022 14:41:44 UTC (Frame: 000177) (Dist: 0.43)
- RUSSIA1: 12/15/2022 16:52:20 UTC (Frame: 002136) (Dist: 0.46)
- RUSSIA1: 12/20/2022 15:03:28 UTC (Frame: 000503) (Dist: 0.37)
- RUSSIA1: 12/20/2022 15:03:56 UTC (Frame: 000510) (Dist: 0.32)
- RUSSIA1: 12/20/2022 15:04:20 UTC (Frame: 000516) (Dist: 0.39)
- RUSSIA1: 12/22/2022 09:07:32 UTC (Frame: 000564) (Dist: 0.33)
- RUSSIA1: 12/22/2022 09:10:00 UTC (Frame: 000601) (Dist: 0.37)
- RUSSIA1: 12/22/2022 10:02:52 UTC (Frame: 001394) (Dist: 0.32)
- RUSSIA1: 12/22/2022 10:04:16 UTC (Frame: 001415) (Dist: 0.45)
- RUSSIA1: 12/22/2022 16:09:56 UTC (Frame: 001500) (Dist: 0.37)
- RUSSIA1: 12/23/2022 16:39:48 UTC (Frame: 001948) (Dist: 0.40)
- RUSSIA1: 12/23/2022 16:42:56 UTC (Frame: 001995) (Dist: 0.42)
- RUSSIA1: 12/26/2022 08:54:04 UTC (Frame: 000362) (Dist: 0.30)
- RUSSIA1: 12/26/2022 08:54:52 UTC (Frame: 000374) (Dist: 0.33)
- RUSSIA1: 12/26/2022 14:55:28 UTC (Frame: 000383) (Dist: 0.35)
- RUSSIA1: 12/26/2022 14:56:20 UTC (Frame: 000396) (Dist: 0.26)
- RUSSIA1: 12/27/2022 09:32:32 UTC (Frame: 000939) (Dist: 0.38)
- RUSSIA1: 12/27/2022 09:34:16 UTC (Frame: 000965) (Dist: 0.32)
- RUSSIA1: 12/27/2022 10:09:00 UTC (Frame: 001486) (Dist: 0.42)
- RUSSIA1: 12/27/2022 10:10:20 UTC (Frame: 001506) (Dist: 0.33)
- RUSSIA1: 12/27/2022 10:12:04 UTC (Frame: 001532) (Dist: 0.38)
- RUSSIA1: 12/27/2022 10:18:52 UTC (Frame: 001634) (Dist: 0.49)
- RUSSIA1: 12/27/2022 15:29:32 UTC (Frame: 000894) (Dist: 0.39)
- RUSSIA1: 12/27/2022 15:31:16 UTC (Frame: 000920) (Dist: 0.35)
- RUSSIA1: 12/27/2022 15:51:16 UTC (Frame: 001220) (Dist: 0.37)
- RUSSIA1: 12/27/2022 16:11:08 UTC (Frame: 001518) (Dist: 0.45)
- RUSSIA1: 12/27/2022 16:12:56 UTC (Frame: 001545) (Dist: 0.31)
- RUSSIA1: 01/10/2023 10:48:20 UTC (Frame: 002076) (Dist: 0.47)
- RUSSIA1: 01/10/2023 10:50:52 UTC (Frame: 002114) (Dist: 0.41)
- RUSSIA1: 01/10/2023 16:58:36 UTC (Frame: 002230) (Dist: 0.36)
- RUSSIA1: 01/11/2023 09:20:52 UTC (Frame: 000764) (Dist: 0.34)
- RUSSIA1: 01/11/2023 10:19:28 UTC (Frame: 001643) (Dist: 0.34)
- RUSSIA1: 01/12/2023 08:55:56 UTC (Frame: 000390) (Dist: 0.42)
- RUSSIA1: 01/12/2023 09:00:16 UTC (Frame: 000455) (Dist: 0.48)
- RUSSIA1: 01/12/2023 14:52:32 UTC (Frame: 000339) (Dist: 0.41)
- RUSSIA1: 01/12/2023 16:44:28 UTC (Frame: 002018) (Dist: 0.35)
- RUSSIA1: 01/12/2023 16:47:32 UTC (Frame: 002064) (Dist: 0.41)
- RUSSIA1: 01/12/2023 16:49:28 UTC (Frame: 002093) (Dist: 0.40)
- RUSSIA1: 01/13/2023 10:07:16 UTC (Frame: 001460) (Dist: 0.35)
- RUSSIA1: 01/13/2023 10:09:36 UTC (Frame: 001495) (Dist: 0.30)
- RUSSIA1: 01/13/2023 10:52:08 UTC (Frame: 002133) (Dist: 0.47)
- RUSSIA1: 01/19/2023 09:02:20 UTC (Frame: 000486) (Dist: 0.41)
- RUSSIA1: 01/19/2023 09:02:40 UTC (Frame: 000491) (Dist: 0.39)
- RUSSIA1: 01/19/2023 15:08:44 UTC (Frame: 000582) (Dist: 0.42)
- RUSSIA1: 01/20/2023 14:59:20 UTC (Frame: 000441) (Dist: 0.41)
- RUSSIA1: 01/20/2023 15:03:32 UTC (Frame: 000504) (Dist: 0.42)
- RUSSIA1: 01/20/2023 15:04:16 UTC (Frame: 000515) (Dist: 0.35)
- RUSSIA1: 01/25/2023 09:53:12 UTC (Frame: 001249) (Dist: 0.34)
- RUSSIA1: 01/25/2023 09:54:16 UTC (Frame: 001265) (Dist: 0.36)
- RUSSIA1: 01/25/2023 09:55:28 UTC (Frame: 001283) (Dist: 0.44)
- RUSSIA1: 01/27/2023 10:01:36 UTC (Frame: 001375) (Dist: 0.34)
- RUSSIA1: 01/27/2023 10:03:24 UTC (Frame: 001402) (Dist: 0.41)
- RUSSIA1: 01/27/2023 16:05:28 UTC (Frame: 001433) (Dist: 0.36)
- RUSSIA1: 01/27/2023 16:07:20 UTC (Frame: 001461) (Dist: 0.46)
- RUSSIA1: 01/30/2023 10:04:28 UTC (Frame: 001418) (Dist: 0.48)
- RUSSIA1: 01/30/2023 10:07:20 UTC (Frame: 001461) (Dist: 0.34)
- RUSSIA1: 01/30/2023 10:39:12 UTC (Frame: 001939) (Dist: 0.48)
- RUSSIA1: 01/30/2023 10:52:56 UTC (Frame: 002145) (Dist: 0.46)
- RUSSIA1: 01/30/2023 10:53:48 UTC (Frame: 002158) (Dist: 0.50)
- RUSSIA1: 01/30/2023 10:54:08 UTC (Frame: 002163) (Dist: 0.44)
- RUSSIA1: 02/02/2023 08:58:08 UTC (Frame: 000423) (Dist: 0.35)
- RUSSIA1: 02/02/2023 08:58:36 UTC (Frame: 000430) (Dist: 0.34)
- RUSSIA1: 02/02/2023 09:00:24 UTC (Frame: 000457) (Dist: 0.42)
- RUSSIA1: 02/02/2023 14:49:48 UTC (Frame: 000298) (Dist: 0.35)
- RUSSIA1: 02/02/2023 14:50:52 UTC (Frame: 000314) (Dist: 0.49)
- RUSSIA1: 02/02/2023 14:52:52 UTC (Frame: 000344) (Dist: 0.27)
- RUSSIA1: 02/09/2023 08:44:40 UTC (Frame: 000221) (Dist: 0.47)
- RUSSIA1: 02/09/2023 08:47:20 UTC (Frame: 000261) (Dist: 0.47)
- RUSSIA1: 02/09/2023 14:52:36 UTC (Frame: 000340) (Dist: 0.41)
- RUSSIA1: 02/09/2023 14:53:04 UTC (Frame: 000347) (Dist: 0.48)
- RUSSIA1: 02/09/2023 14:55:00 UTC (Frame: 000376) (Dist: 0.47)
- RUSSIA1: 02/09/2023 16:48:52 UTC (Frame: 002084) (Dist: 0.45)
- RUSSIA1: 02/15/2023 14:57:44 UTC (Frame: 000417) (Dist: 0.42)
- RUSSIA1: 02/16/2023 09:04:40 UTC (Frame: 000521) (Dist: 0.45)
- RUSSIA1: 02/16/2023 14:53:48 UTC (Frame: 000358) (Dist: 0.38)
- RUSSIA1: 02/16/2023 16:48:12 UTC (Frame: 002074) (Dist: 0.41)
- RUSSIA1: 02/17/2023 10:22:52 UTC (Frame: 001694) (Dist: 0.44)
- RUSSIA1: 02/17/2023 16:02:08 UTC (Frame: 001383) (Dist: 0.37)
- RUSSIA1: 03/07/2023 08:55:48 UTC (Frame: 000388) (Dist: 0.39)
- RUSSIA1: 03/07/2023 15:00:08 UTC (Frame: 000453) (Dist: 0.41)
- RUSSIA1: 03/10/2023 10:47:44 UTC (Frame: 002067) (Dist: 0.36)
- RUSSIA1: 03/13/2023 08:53:08 UTC (Frame: 000348) (Dist: 0.43)
- RUSSIA1: 03/13/2023 09:03:32 UTC (Frame: 000504) (Dist: 0.43)
- RUSSIA1: 03/13/2023 09:04:44 UTC (Frame: 000522) (Dist: 0.38)
- RUSSIA1: 03/13/2023 09:05:24 UTC (Frame: 000532) (Dist: 0.32)
- RUSSIA1: 03/13/2023 10:21:00 UTC (Frame: 001666) (Dist: 0.38)
- RUSSIA1: 03/13/2023 10:25:52 UTC (Frame: 001739) (Dist: 0.42)
- RUSSIA1: 03/13/2023 14:58:56 UTC (Frame: 000435) (Dist: 0.42)
- RUSSIA1: 03/13/2023 16:13:44 UTC (Frame: 001557) (Dist: 0.39)
That's all there is to it!
This analysis is part of an ongoing collaboration between the Internet Archive and its TV News Archive, the multi-party Media-Data Research Consortium and GDELT.