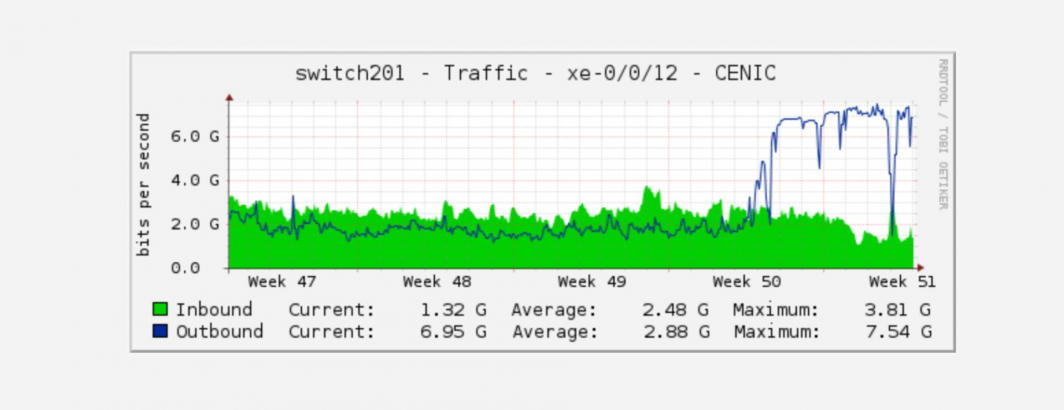
As part of our incredible ongoing research collaborations with the Internet Archive, we frequently work at collections scale, running complex and pioneering analyses across the entirety of breathtakingly large datasets. In the creation of one of our newest forthcoming datasets we've been collaborating with the Archive's Television News Archive on a new analysis. Here's what it looks like to saturate a 10GB/s research link in the service of research!
Internet2, ho! The @internetarchive generally exchanges 2gigabits/sec to Universities for research and stuff, and then, 7Gbits! all good, we love it. (Thank you @CENICNews )
datamining and machine learning start analyzing whole collections– what a library is for! pic.twitter.com/8Hczs71znt
— Brewster Kahle (@brewster_kahle) December 17, 2020