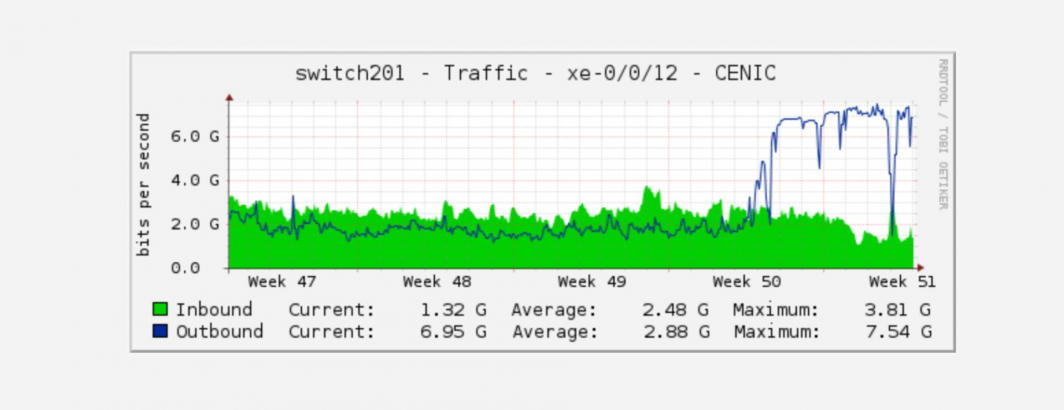
We mentioned earlier this month how our latest collaboration with the Internet Archive has been saturating the Archive's 10GbE research link. To date in collaboration with the Archive we've streamed more than 1.5PB of video and counting through the cloud for analysis (limited only by the 10GbE incoming link). Using stream analysis none of that data is retained or stored on disk, it is multiplexed across a cluster of two dozen 1-core 20GB RAM VM's each with just a 10GB local disk that process the incoming video and stream their residual annotations to GCS. The entire processing fleet is located in GCP's Los Angeles datacenter to be as geographically proximate as possible to reduce network overhead. In turn, the resultant (small) annotation files written to GCS are consumed by a nationally distributed array of services running across all of GCP's US datacenters that analyze those annotation files and produce various subsequent analytic outputs using GCS as a distributed storage fabric and a set of centralized orchestration servers for coordination.
This is the power of the cloud – to be able to locate a processing cluster geographically beside a data source, to stream petabytes of ingested data that are sharded across a lightweight cluster that processes the data in-flight and streams a much smaller set of annotation files out to a globally-distributed storage fabric that in turn can be consumed from yet other data centers. Datasets are no longer massive forklifted artifacts, but rather processed ephemerally in-flight. Here the limiting factor is the speed of the incoming data source link whereas once in the cloud the interconnect speed between cluster nodes and between VMs and GCS allows for almost linear scalability that can dynamically adapt to any ingest rate.