
Using the new Global Similarity Graph, it takes only a single line of SQL to compile a list of the top story clusters of the last 15 minutes. The query below orders all URLs from today according to how many URLs in the previous 30 minutes they were clustered against, displaying the top 5 most similar for each:
SELECT fromurl, avg(simScore) avgsim, ARRAY_AGG(toUrl order by simScore desc limit 5), count(1) cnt FROM `gdelt-bq.gdeltv2.gsg` where DATE(fromDate) = "2021-07-02" group by fromUrl order by cnt desc
This yields a list like the following, showing how easy it is to generate a "top stories" list.
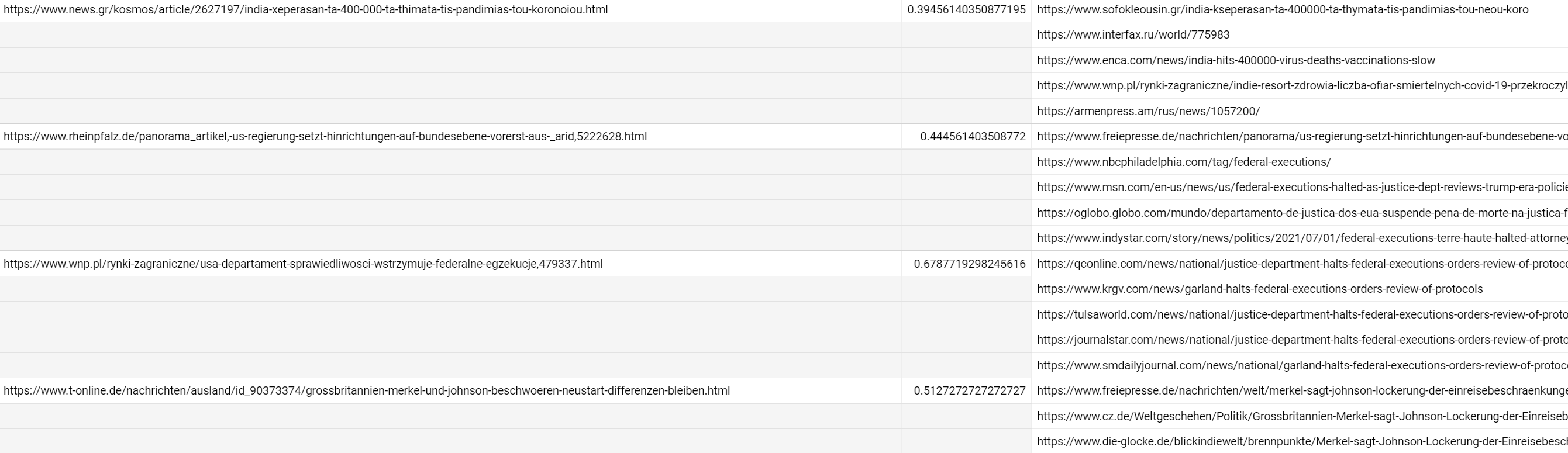
To avoid clustering against other stories by the same news outlet you can add a simple domain filter:
SELECT fromurl, avg(simScore) avgsim, ARRAY_AGG(toUrl order by simScore desc limit 5), count(1) cnt FROM `gdelt-bq.gdeltv2.gsg` where DATE(fromDate) = "2021-07-02" and NET.REG_DOMAIN(toUrl) != NET.REG_DOMAIN(fromUrl) group by fromUrl order by cnt desc
We hope this showcases some of the ways this new dataset can be used!