
Following yesterday's experiments on document-level embeddings using the Universal Sentence Encoder family, we wanted to explore how well the same approach might work at the subdocument level, comparing individual sentences against a given query sentence. While this could be used to perform sentence-level semantic similarity search across the news, the same approach could be used for a far more interesting task: scan worldwide news coverage in realtime for statements that have been reviewed by fact checkers.
Using the same Colab code as before, we simply set "sent1" to the Quick Take summary from a FactCheck.org fact check relating to the false claim that Covid-19 vaccines embed microchips in recipients for tracking:
- "A video circulating on social media falsely claims that vaccines for COVID-19 have a microchip that “tracks the location of the patient.” The chip, which is not currently in use, would be attached to the end of a plastic vial and provide information only about the vaccine dose. It cannot track people." (FactCheck.org)
We then used the same three USE models (USE CMLM Multilingual, USE, USE-Large) to compute the similarity of that verdict summary against a selection of sentences from a news article listing common Covid-19 falsehoods and one reporting routine Covid-19 news updates. This tests two competing demands on the system:
- The model's ability to return a high similarity score between the claim and sentences highly related to that claim. This allows the model to scan news in realtime and flag related passages.
- The model's ability to return a low similarity score between the claim and sentences that discuss Covid-19 more generally in the context of routine Covid-19 updates. This ensures the model is able to distinguish between routine Covid-19 content and passages sufficiently related to the fact check.
ONLINE NEWS
To test the ability of such a system to accurately scan online news coverage for sentence-level references to this fact check claim, we selected a set of sentences from a Healthline article documenting a number of common vaccine falsehoods and a Washington Post article discussing vaccination rates and calls for mandatory vaccination. The first 6 sentences are from Healthline and the remaining 5 from the Washington Post.
- "Misinformation and falsehoods about the COVID-19 vaccines have made their way into social media and beyond" (Healthline)
- "These are the sorts of notions that are held by many people who are reluctant and hesitant about getting the COVID-19 vaccine… [leaving many people] uncertain of the information they encounter, particularly on social media and even from conversations with their neighbor,” Dr. William Schaffner, professor of preventive medicine and infectious diseases at Vanderbilt University Medical Center in Nashville, told Healthline." (Healthline)
- "Healthline turned to medical experts to set the record straight on some of the most common myths currently circulating" (Healthline)
- "Conspiracy theories about the government using vaccines to track people and rich people like Bill Gates being behind the notion are false" (Healthline)
- "Physically, chips are not small enough that they could be inoculated with a needle. The COVID-19 vaccines are old-fashioned simple public health. Bad disease; good vaccine. Let’s get the vaccine in order to prevent the bad disease. It’s nothing more complicated than that,” said Schaffner" (Healthline)
- "The government put a microchip in COVID-19 vaccines to track you" (Healthline)
- "Medical groups representing millions of doctors, nurses, pharmacists and other health workers on Monday called for mandatory vaccinations of all U.S. health personnel against the coronavirus, framing the move as a moral imperative as new infections mount sharply." (Washington Post)
- "We call for all health care and long-term care employers to require their employees to be vaccinated against covid-19,” the American Medical Association, the American Nurses Association and 55 other groups wrote in a joint statement shared with The Washington Post." (Washington Post)
- "“The health and safety of U.S. workers, families, communities, and the nation depends on it." (Washington Post)
- "The statement — issued by many groups calling for a mandate for the first time — represents an increasingly tough stance by the medical and public health establishment amid the sluggish pace of national vaccinations." (Washington Post)
- "It comes as new cases rip through the nation, driven by the hyper-transmissible delta variant." (Washington Post)
In an ideal system we would expect the following:
- Sentences 5 & 6 would have the highest similarity scores, since they are directly related to the fact check summary.
- Sentences 1-4 would have moderate similarity, since they all describe vaccine falsehoods.
- Sentences 7-11 should have low similarity, since they represent routine daily Covid-19 coverage unrelated to the targeted falsehood.
The final results of the three models can be seen below:
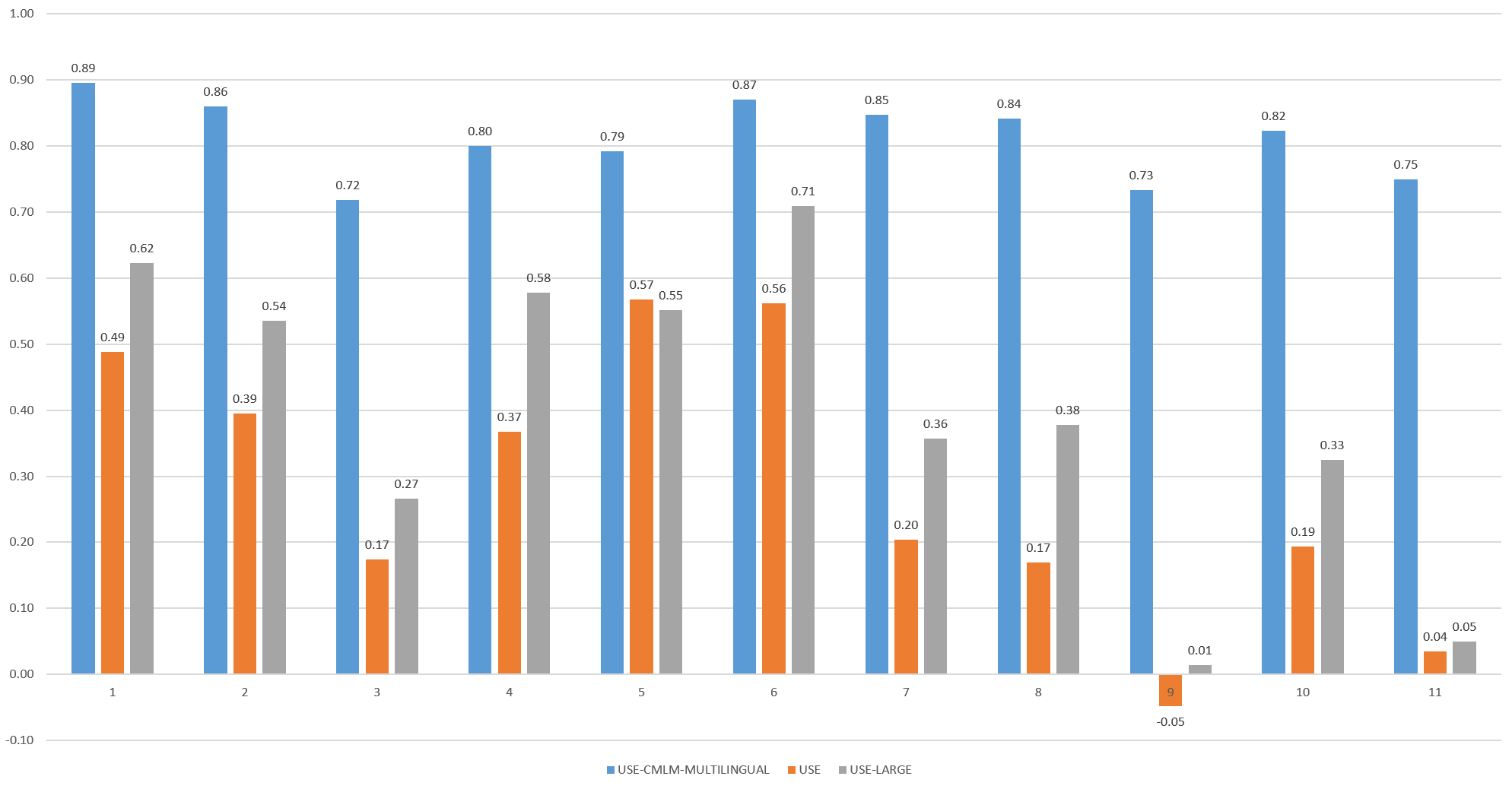
As before, the CMLM Multilingual model scores do not closely track the expected similarity of the passages. The scores of USE and USE-Large, however, are exactly as expected, scoring sentences 5 & 6 as the most similar and assigning higher scores to the misinformation-related sentences than to the routine Covid-19 news sentences. Both USE and USE-Large largely track one another in terms of how they order the sentences, even though USE-Large tends to assign much higher similarity scores than does USE.
From the graph above, it is clear that both USE and USE-Large meet our two criteria. They both assign the two expected sentences the highest scores, assign the other misinformation-related sentences medium-high scores and assign the remaining routine Covid-19 sentences low scores. It is clear that both models could be used to scan news coverage in realtime at the sentence level for sentences highly similar to known fact checks. Moreover, given that sentence embeddings are immutable, as new false claims are identified by fact checkers, they could simply be compared against a sentence-level embeddings database to identify past appearances of those claims in the news.
TELEVISION NEWS
What about television news? Could we apply a similar process to scan television news for statements relating to known fact checks? Using the TV Explorer to search the Internet Archive's Television News Archive for "vaccine" and "microchip" we find a number of relevant clips, including this exchange on CNN's The Lead With Jake Tapper at 1PM PDT on June 9, 2021:
- "i mean, you know, it predates this pandemic, these types of conspiracy theories, i mean you and i have talked about it in the past."
- "i get when people advocate crazy things in order to sell something. she has a book just say no to vaccines, maybe that's it."
- "there is no evidence of this and let's not equivocate."
- "there is no microchip or tracking device or some sort of other product that's attached to these vaccines."
- "you know, it's very — it's harmful when you look overall at vaccine skepticism but one thing i will tell you is that she is probably preaching to an audience that already sort of believes what she says."
Using the same process we used for online news, we score the similarity of each of these five closed captioning sentences against the FactCheck.org claim and receive the following results:
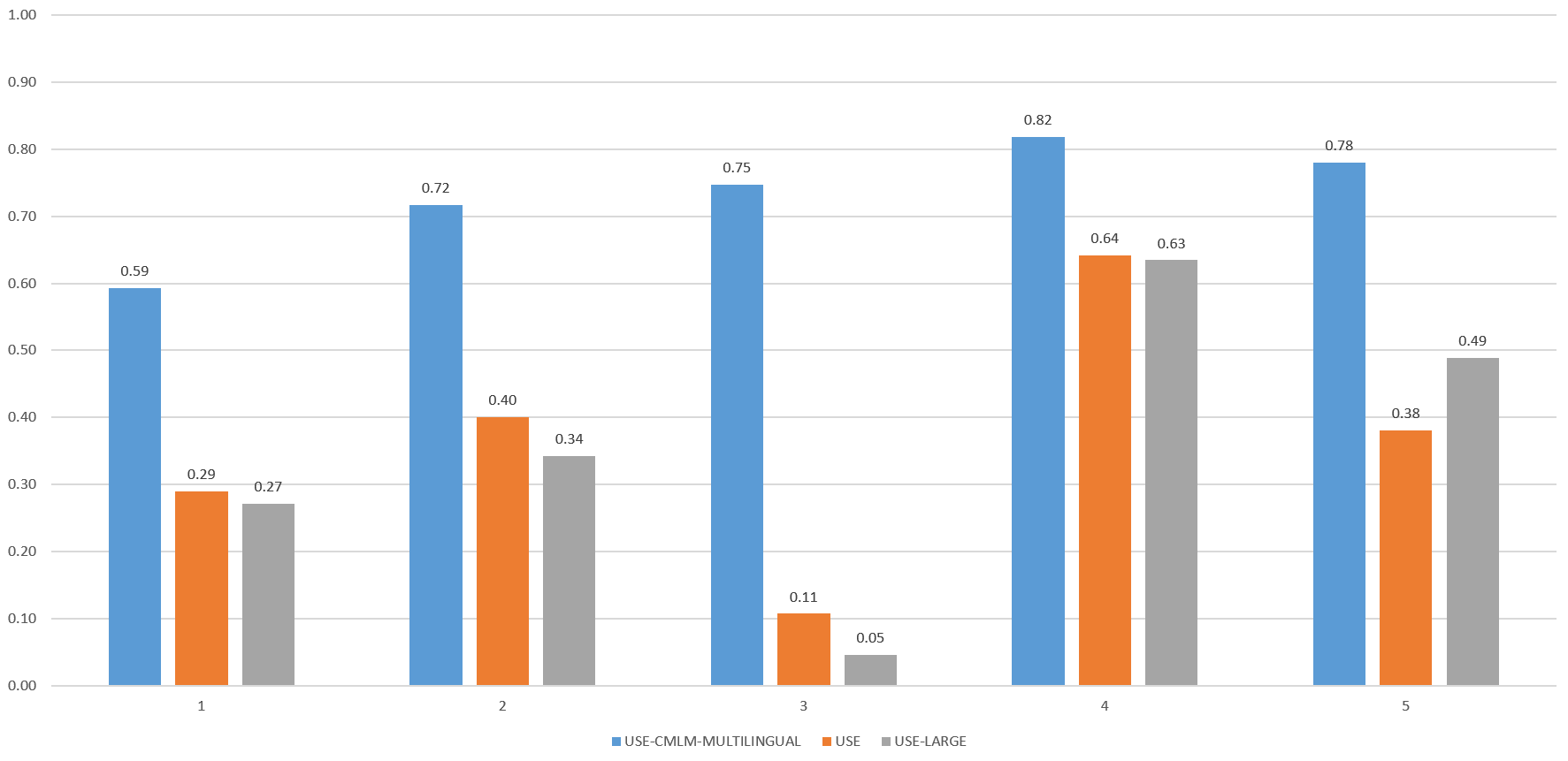
Both USE and USE-Large correctly score sentence 4 as the most similar to the fact check claim, while scoring the remaining sentences as much lower. This suggests that despite television's more informal stream-of-consciousness narrative style, we are able to accurately use USE and USE-Large to identify references to a given fact check claim across television news programming!
CONCLUSION
We've demonstrated that sentence-level embeddings can be applied to successfully scan both online and television news coverage for statements highly similar to a known fact check claim. Both USE and USE-Large yield scores sufficient to distinguish unrelated, related and peripherally related sentences with sufficient stratification to permit automated scanning of the news. Moreover, the extraordinary computational efficiency of the base USE model means it is theoretically tractable to generate sentence-level news coverage embeddings in realtime that would permit realtime scanning of global news for references to fact checked claims.
Further, the immutability of embeddings means as new fact checks are published, historical embeddings could be rapidly scanned to identify past references to the claim. The approach's success on both online and television news, despite considerable narrative differences, suggests the possibility of realtime multimodal scanning.
To refine the results, reduce false positives and identify narrative drift, a production application would likely use such embeddings to identify highly similar sentences and then apply further modeling to the resulting matches, but the ability of embeddings to at the very least identify candidate sentences at scale with this speed and accuracy suggests this approach has significant potential.
Given such a collection of sentence-level embeddings, fine-grained search and retrieval also becomes possible, pointing users not just to relevant coverage, but to the specific statement within that coverage of relevance to their query. Applied to such a fine-grained dataset, narrative mapping could map not just document-level similarity, but actually examine argument-level similarity and even document-level structural segmentation.
We're excited to see where these possibilities take you!