
Word use similarity like the Global Similarity Graph measure the overlap of word use between two textual passages, but depend on the exact same words being used to describe the same entities and concepts. An article about a "knife attack" and one about a "stabbing incident" would have zero assessed similarity using word overlap similarity since they do not share any words, even though they describe the same concept. Word embeddings offer a powerful look at the similarity of isolated words, but they do not incorporate context, meaning "I can do it" and "a can of dog food" treat "can" the same way. Sentence and document embeddings, in contrast, operate similar to word embeddings, but over larger passages.
One such textual embedding approach is the the Universal Sentence Encoder family, which encompasses a range of models for encoding small amounts of text into high-dimensional vector representations that can be used to assess semantic similarity between passages, including those that share few or even no words and several of the models have particular applicably to semantic similarity tasks. We want to use an off-the-shelf pretrained model, so we explored a range of models available on TensorFlow Hub before settling on the USE family as the best tradeoff between performance and accuracy and most aligned with our need for a highly performant semantic similarity capability.
MODELS
Here we explore three USE models:
- Universal Sentence Encoder V4. This is a Deep Averaging Network, which trades somewhat reduced accuracy for immensely improved speed, vastly reduced hardware requirements and nearly linear runtime with sentence length. It is a monolingual English model.
- Universal Sentence Encoder Large V5. This is a Transformer architecture, which imposes significantly higher computational complexity with an attendant dramatic speed reduction. It too is a monolingual English model.
- Universal Sentence Encoder CMLM Multilingual V1 (requires an accompanying preprocessor V2). This is a BERT Transformer architecture, but is much more complex and has a dramatically reduced inference speed. It supports more than 100 languages, placing text across all supported languages into the same shared vector space, allowing similarity comparisons irrespective of language.
SPEED
All embedding applications present a triple tradeoff of inference speed, hardware requirements and accuracy. Accuracy is important, but given GDELT's scale and the rate at which new content arrives, speed is more important, while due to the experimental nature of our embedding use, we wanted to minimize the amount of hardware required.
To test the performance of each of the three models, we spun up a 4-core E2 VM with 32GB of RAM and a 500GB SSD disk (e2-highmem-4) and launched the three models and the preprocessor in docker containers using TensorFlow Serve:
docker run -t -p 8501:8501 --rm --name tf-serve-universal-sentence-encoder-large -v "/TENSORFLOW/models:/models" -e MODEL_NAME="universal-sentence-encoder-large" -t tensorflow/serving & docker run -t -p 9501:9501 --rm --name tf-serve-universal-sentence-encoder -v "/TENSORFLOW/models:/models" -e MODEL_NAME="universal-sentence-encoder" -t tensorflow/serving --rest_api_port=9501 & docker run -t -p 10501:10501 --rm --name tf-serve-universal-sentence-encoder-cmlm-multiligual-base -v "/TENSORFLOW/models:/models" -e MODEL_NAME="universal-sentence-encoder-cmlm-multiligual-base" -t tensorflow/serving --rest_api_port=10501 & docker run -t -p 11501:11501 --rm --name tf-serve-universal-sentence-encoder-cmlm-multilingualpreprocess -v "/TENSORFLOW/models:/models" -e MODEL_NAME="universal-sentence-encoder-cmlm-multilingualpreprocess" -t tensorflow/serving --rest_api_port=11501 &
Counterintuitively, when running the USE CMLM model under TensorFlow serve, the preprocessor and embedding model use different parameter names. Thus, if you simply feed the output of the preprocessor in order to the embedder, you will receive an error about invalid parameter names.
Instead, first run the text through the preprocessor:
time curl -d '{"instances": ["The U.S. and Germany have reached an agreement allowing the completion of a controversial Russian natural-gas pipeline, according to officials from Berlin and Washington, who expect to announce the deal as soon as Wednesday, bringing an end to years of tension between the two allies The Biden administration will effectively waive Washington’s longstanding opposition to the pipeline, Nord Stream 2, a change in the U.S. stance, ending years of speculation over the fate of the project, which has come to dominate European energy-sector forecasts. Germany under the agreement will agree to assist Ukraine in energy-related projects and diplomacy The U.S. and Germany have reached an agreement allowing the completion of a controversial Russian natural-gas pipeline, according to officials from Berlin and Washington, who expect to announce the deal as soon as Wednesday, bringing an end to years of tension between the two allies The Biden administration will effectively waive Washington’s longstanding opposition to the pipeline, Nord Stream 2, a change in the U.S. stance, ending years of speculation over the fate of the project, which has come to dominate European energy-sector forecasts. Germany under the agreement will agree to assist Ukraine in energy-related projects and diplomacy"]}' -X POST http://localhost:11501/v1/models/universal-sentence-encoder-cmlm-multilingualpreprocess:predict
{
"predictions": [
{
"bert_pack_inputs": [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
"bert_pack_inputs_1": [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
"bert_pack_inputs_2": [101, 15088, 158, 119, 156, 119, 14999, 30797, 15284, 65804, 15001, 56644, 68212, 14985, 131909, 14997, 170, 210958, 35229, 19539, 118, 20926, 147602, 117, 33078, 14986, 69759, 15294, 21630, 14999, 17791, 117, 16068, 42155, 14986, 109364, 14985, 25606, 15061, 26768, 15061, 41057, 117, 69207, 15001, 16706, 14986, 16763, 14997, 76357, 18878, 14985, 17054, 252073, 15088, 130263, 39380, 15370, 79360, 399961, 17791, 2976, 188, 227694, 422218, 56882, 14986, 14985, 147602, 117, 24689, 62259, 123, 117, 170, 19963, 14981, 14985, 158, 119, 156, 119, 345915, 117, 79436, 16763, 14997, 441835, 15444, 14985, 90798, 14997, 14985, 20651, 117, 15910, 15535, 16080, 14986, 416476, 24544, 25932, 118, 23086, 457543, 119, 30797, 16019, 14985, 56644, 15370, 38049, 14986, 52905, 38620, 14981, 25932, 118, 25880, 32368, 14999, 55870, 19498, 15088, 158, 119, 156, 102]
}
]
}
Then replace "predictions" with "instances" and rename the "bert_pack_inputs" fields to the following: "input_26", "input_27" and "input_25" (in that order):
time curl -d '{"instances": [
{
"input_26": [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
"input_27": [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
"input_25": [101, 15088, 158, 119, 156, 119, 14999, 30797, 15284, 65804, 15001, 56644, 68212, 14985, 131909, 14997, 170, 210958, 35229, 19539, 118, 20926, 147602, 117, 33078, 14986, 69759, 15294, 21630, 14999, 17791, 117, 16068, 42155, 14986, 109364, 14985, 25606, 15061, 26768, 15061, 41057, 117, 69207, 15001, 16706, 14986, 16763, 14997, 76357, 18878, 14985, 17054, 252073, 15088, 130263, 39380, 15370, 79360, 399961, 17791, 2976, 188, 227694, 422218, 56882, 14986, 14985, 147602, 117, 24689, 62259, 123, 117, 170, 19963, 14981, 14985, 158, 119, 156, 119, 345915, 117, 79436, 16763, 14997, 441835, 15444, 14985, 90798, 14997, 14985, 20651, 117, 15910, 15535, 16080, 14986, 416476, 24544, 25932, 118, 23086, 457543, 119, 30797, 16019, 14985, 56644, 15370, 38049, 14986, 52905, 38620, 14981, 25932, 118, 25880, 32368, 14999, 55870, 19498, 15088, 158, 119, 156, 102]
}
]}' -X POST http://localhost:10501/v1/models/universal-sentence-encoder-cmlm-multiligual-base:predict
The output of the model above will include several fields, of which the embeddings are contained within "lambda8".
To test model performance, we concatenated the lead and second paragraphs of a randomly selected Wall Street Journal article: "The U.S. and Germany have reached an agreement allowing the completion of a controversial Russian natural-gas pipeline, according to officials from Berlin and Washington, who expect to announce the deal as soon as Wednesday, bringing an end to years of tension between the two allies The Biden administration will effectively waive Washington’s longstanding opposition to the pipeline, Nord Stream 2, a change in the U.S. stance, ending years of speculation over the fate of the project, which has come to dominate European energy-sector forecasts. Germany under the agreement will agree to assist Ukraine in energy-related projects and diplomacy" that offered a reasonable length, narrow topical range and multiple entities.
To test inference performance, we batched together 20 copies of the text above and sent it as 1,000 distinct requests to the server using four parallel threads using GNU parallel to simulate processing 20,000 articles, which is around what GDELT ingests on average in a given 15 minute interval. You can see the results below:
- Universal Sentence Encoder V4. The performance advantage of the DAN is clear here, as the machine never reached beyond 180% CPU and took just 18 seconds to complete. In short, the machine's size could be reduced by half, with no impact. Large batch sizes are required to reach higher CPU levels.
- Universal Sentence Encoder Large V5. The greater cost of the Transformer architecture is clear, as the machine became saturated at 380% CPU and took 16 minutes (53 times slower than the DAN version). Within GPU/TPU acceleration, it would take 106 cores to match the DAN's speed.
- Universal Sentence Encoder CMLM Multilingual V1. The preprocessor required minimal time, just 10 seconds total. The inference stage, however, took 51 minutes at 380% CPU (170 times slower than the DAN version), reflecting that more complex models are difficult to run without GPU or TPU acceleration. Running this model with equivalent speed to the DAN, assuming perfect linear speedup, would require 340 cores.
ACCURACY
Given the enormous differences in inference performance among the three models, how do their results compare in our given semantic similarity task? To assess how well they distinguish sentences of varying similarity, we used four sentences, the first two related to Covid-19 and the second two relating to the Nord Stream 2 pipeline, with the second and third sentences sharing some overlap related to public opinion in the former and diplomatic opinion in the latter (to test how the models cope with content that differs at a macro-topical level but shares subtopical relatedness):
- "A major Texas hospital system has reported its first case of the lambda COVID-19 variant, as the state reels from the rampant delta variant Houston Methodist Hospital, which operates eight hospitals in its network, said the first lambda case was confirmed Monday Houston Methodist had a little over 100 COVID-19 patients across the hospital system last week. That number rose to 185 Monday, with a majority of those infected being unvaccinated, according to a statement released by the hospital Monday" (ABC News)
- "When asked which poses a greater risk to their health, more unvaccinated Americans say the COVID-19 vaccines than say the virus itself, according to a new Yahoo News/YouGov poll — a view that contradicts all available science and data and underscores the challenges that the United States will continue to face as it struggles to stop a growing pandemic of the unvaccinated driven by the hyper-contagious Delta variant. Over the last 18 months, COVID-19 has killed more than 4.1 million people worldwide, including more than 600,000 in the U.S. At the same time, more than 2 billion people worldwide — and more than 186 million Americans — have been at least partially vaccinated against the virus falling ill, getting hospitalized and dying" (Yahoo News)
- "In the midst of tense negotiations with Berlin over a controversial Russia-to-Germany pipeline, the Biden administration is asking a friendly country to stay quiet about its vociferous opposition. And Ukraine is not happy. At the same time, administration officials have quietly urged their Ukrainian counterparts to withhold criticism of a forthcoming agreement with Germany involving the pipeline, according to four people with knowledge of the conversations" (Politico)
- "The U.S. and Germany have reached an agreement allowing the completion of a controversial Russian natural-gas pipeline, according to officials from Berlin and Washington, who expect to announce the deal as soon as Wednesday, bringing an end to years of tension between the two allies The Biden administration will effectively waive Washington’s longstanding opposition to the pipeline, Nord Stream 2, a change in the U.S. stance, ending years of speculation over the fate of the project, which has come to dominate European energy-sector forecasts. Germany under the agreement will agree to assist Ukraine in energy-related projects and diplomacy" (Wall Street Journal)
To make it easier to rapidly experiment with different configurations in comparing the outputs of these four sentences, we used the incredible Colab service, which allows you to run all three models interactively in your browser, completely for free! The final code to run all three is:
#load libraries... import tensorflow_hub as hub import tensorflow as tf !pip install tensorflow_textimport tensorflow_text as text # Needed for loading universal-sentence-encoder-cmlm/multilingual-preprocess import numpy as np #normalize... def normalization(embeds): norms = np.linalg.norm(embeds, 2, axis=1, keepdims=True) return embeds/norms #define our sentences... sent1 = tf.constant(["A major Texas hospital system has reported its first case of the lambda COVID-19 variant, as the state reels from the rampant delta variant Houston Methodist Hospital, which operates eight hospitals in its network, said the first lambda case was confirmed Monday Houston Methodist had a little over 100 COVID-19 patients across the hospital system last week. That number rose to 185 Monday, with a majority of those infected being unvaccinated, according to a statement released by the hospital Monday"]) sent2 = tf.constant(["When asked which poses a greater risk to their health, more unvaccinated Americans say the COVID-19 vaccines than say the virus itself, according to a new Yahoo News/YouGov poll — a view that contradicts all available science and data and underscores the challenges that the United States will continue to face as it struggles to stop a growing pandemic of the unvaccinated driven by the hyper-contagious Delta variant. Over the last 18 months, COVID-19 has killed more than 4.1 million people worldwide, including more than 600,000 in the U.S. At the same time, more than 2 billion people worldwide — and more than 186 million Americans — have been at least partially vaccinated against the virus falling ill, getting hospitalized and dying"]) sent3 = tf.constant(["In the midst of tense negotiations with Berlin over a controversial Russia-to-Germany pipeline, the Biden administration is asking a friendly country to stay quiet about its vociferous opposition. And Ukraine is not happy. At the same time, administration officials have quietly urged their Ukrainian counterparts to withhold criticism of a forthcoming agreement with Germany involving the pipeline, according to four people with knowledge of the conversations"]) sent4 = tf.constant(["The U.S. and Germany have reached an agreement allowing the completion of a controversial Russian natural-gas pipeline, according to officials from Berlin and Washington, who expect to announce the deal as soon as Wednesday, bringing an end to years of tension between the two allies The Biden administration will effectively waive Washington’s longstanding opposition to the pipeline, Nord Stream 2, a change in the U.S. stance, ending years of speculation over the fate of the project, which has come to dominate European energy-sector forecasts. Germany under the agreement will agree to assist Ukraine in energy-related projects and diplomacy"]) ############################################################# #test with USE-CMLM-MULTILINGUAL preprocessor = hub.KerasLayer("https://tfhub.dev/google/universal-sentence-encoder-cmlm/multilingual-preprocess/2") encoder = hub.KerasLayer("https://tfhub.dev/google/universal-sentence-encoder-cmlm/multilingual-base/1") sent1e = encoder(preprocessor(sent1))["default"] sent2e = encoder(preprocessor(sent2))["default"] sent3e = encoder(preprocessor(sent3))["default"] sent4e = encoder(preprocessor(sent4))["default"] sent1e = normalization(sent1e) sent2e = normalization(sent2e) sent3e = normalization(sent3e) sent4e = normalization(sent4e) print ("USE-CMLM-MULTILINGUAL Scores") print (np.matmul(sent1e, np.transpose(sent2e))) print (np.matmul(sent1e, np.transpose(sent3e))) print (np.matmul(sent1e, np.transpose(sent4e))) print (np.matmul(sent2e, np.transpose(sent3e))) print (np.matmul(sent2e, np.transpose(sent4e))) print (np.matmul(sent3e, np.transpose(sent4e))) ############################################################# #now repeat with USE embed_use = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4") sent1e = embed_use(sent1) sent2e = embed_use(sent2) sent3e = embed_use(sent3) sent4e = embed_use(sent4) sent1e = normalization(sent1e) sent2e = normalization(sent2e) sent3e = normalization(sent3e) sent4e = normalization(sent4e) print ("USE Scores") print (np.matmul(sent1e, np.transpose(sent2e))) print (np.matmul(sent1e, np.transpose(sent3e))) print (np.matmul(sent1e, np.transpose(sent4e))) print (np.matmul(sent2e, np.transpose(sent3e))) print (np.matmul(sent2e, np.transpose(sent4e))) print (np.matmul(sent3e, np.transpose(sent4e))) ############################################################# #now repeat with USE-LARGE embed_use = hub.load("https://tfhub.dev/google/universal-sentence-encoder-large/5") sent1e = embed_use(sent1) sent2e = embed_use(sent2) sent3e = embed_use(sent3) sent4e = embed_use(sent4) sent1e = normalization(sent1e) sent2e = normalization(sent2e) sent3e = normalization(sent3e) sent4e = normalization(sent4e) print ("USE-LARGE Scores") print (np.matmul(sent1e, np.transpose(sent2e))) print (np.matmul(sent1e, np.transpose(sent3e))) print (np.matmul(sent1e, np.transpose(sent4e))) print (np.matmul(sent2e, np.transpose(sent3e))) print (np.matmul(sent2e, np.transpose(sent4e))) print (np.matmul(sent3e, np.transpose(sent4e)))
The code above calculates the pairwise similarity of all four sentences to each other. Intuitively, we would expect sentences three and four to have very high similarity, sentences one and two to have medium-high similarity, sentences two and three to have very low, but measurable similarity, and other combinations to have extremely low similarity. How did the results turn out? The figure below shows the final results.
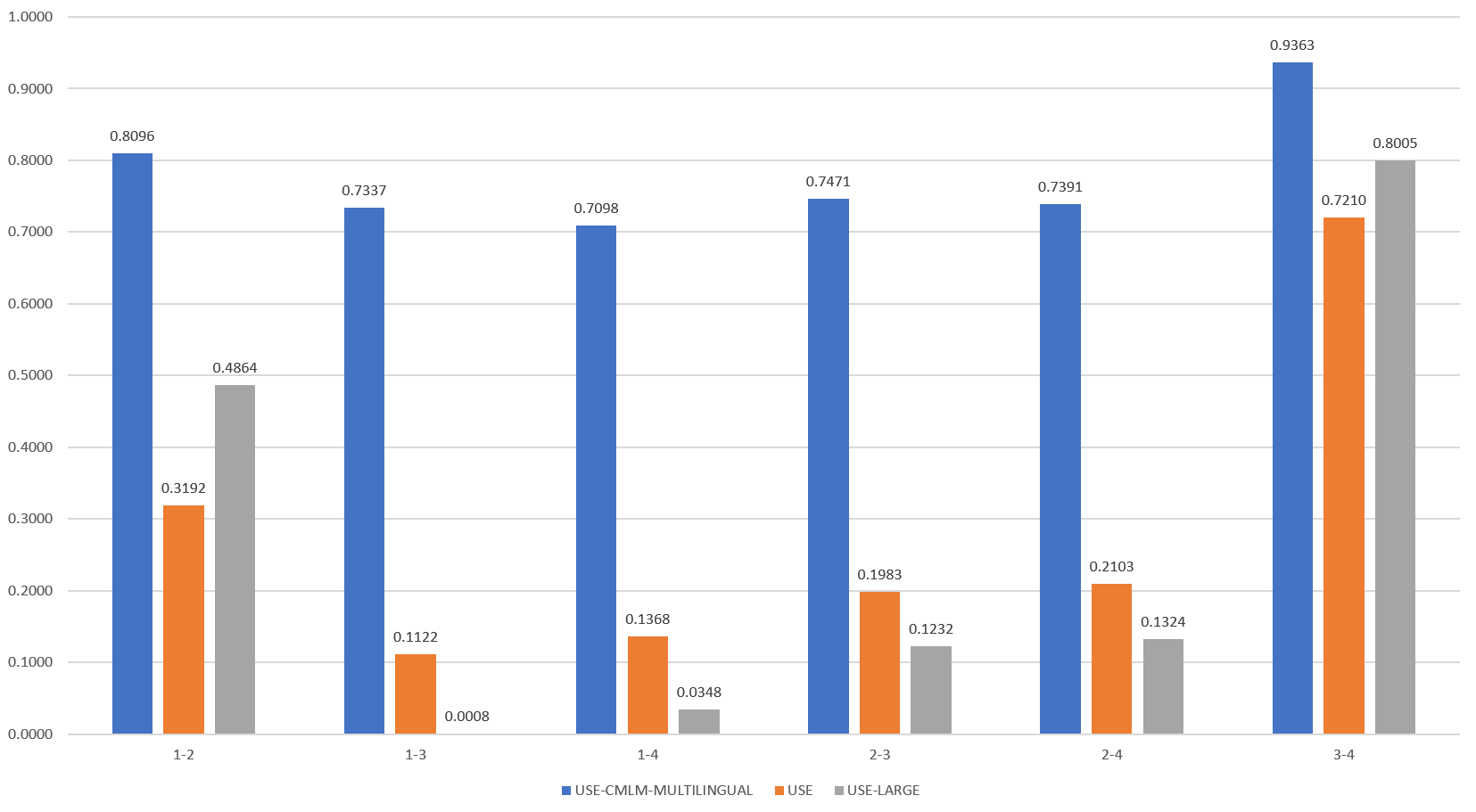
The CMLM Multilingual model is similar to other BERT models in that it returns high similarity scores for all sentence pairs, even highly dissimilar ones. While sentence pairs 1-2 and 3-4 have the highest scores as expected, the other pairs are also all extremely high. USE-Large yields the best performance, strongly distinguishing 1-2 and 3-4 from the other pairs. USE also performs well, though it assesses a much lower similarity score between the first two sentences and higher scores for the others, making it slightly more difficult to distinguish them.
What about a different set of sentences that present an even more complicated macro-micro topical divide? As before, the first two sentences are Covid-related, with both emphasizing reporting of Covid statistics, while the second two are about vote recounts in Arizona relating to the 2020 presidential election. Thus, at a macro level, both sentence pairs are about entirely different topics, though both explore those topics through the lens of counting.
- "Several states scaled back their reporting of COVID-19 statistics this month just as cases across the country started to skyrocket, depriving the public of real-time information on outbreaks, cases, hospitalizations and deaths in their communities. The shift to weekly instead of daily reporting in Florida, Nebraska, Iowa and South Dakota marked a notable shift during a pandemic in which coronavirus dashboards have become a staple for Americans closely tracking case counts and trends to navigate a crisis that has killed more than 600,000 people in the U.S." (Associated Press)
- "The state accounts for one in five new infections in the U.S. and logged 67,413 cases over the past week, according to the Centers for Disease Control and Prevention. Florida had 314 cases per 100,000 people over the past week, second only to Louisiana. The weekly total of new cases reported by Florida jumped more than fourfold between July 1 and July 22, reaching its highest point since mid-January. Epidemiologists say various factors are at play: large numbers of unvaccinated people, a relaxation of preventive measures like mask-wearing and social distancing, the spread of the highly contagious Delta variant of the coronavirus and the congregation of people indoors during hot summer months." (Wall Street Journal)
- "Arizona’s secretary of state had a message for Donald Trump before he appeared in Phoenix on Saturday: Take your loss and accept it and move on. Trump was set to speak at an event organised by Turning Point Action, a conservative group, and called the Rally to Save Our Elections! Republicans in the most populous county in Arizona continue to pursue a controversial audit of ballots in an attempt to prove Trump’s claim that his loss to Joe Biden in the state, and nationally, was caused by widespread voter fraud. It was not." (The Guardian)
- "Arizona county election officials have identified fewer than 200 cases of potential voter fraud out of more than 3 million ballots cast in last year’s presidential election, further discrediting former President Donald Trump’s claims of a stolen election as his allies continue a disputed ballot review in the state’s most populous county." (Associated Press)
The final results can be seen in the chart below:

Here, the CMLM Multilingual model barely distinguishes the two highly similar pairs and it is not immediately clear from the graph above that any of the pairs are dramatically more similar than the others. In contrast, USE and USE-Large track each other closely other than when comparing sentence 2 with sentences 3 and 4, in which USE-Large scores those pairwise similarities at around half the level of USE. Notably, USE yields similar scores for all four cross-pairings of sentences from the Covid and Arizona sets, while USE-Large yields substantially higher similarities for the first Covid sentence against both Arizona sentences versus the second Covid sentence. It is not immediately clear why this is.
Rather than distinguishing dissimilar topics, another common use case of similarity scoring lies in mapping out the narrative landscape of a common topical space, such as taking a collection of Covid-related coverage and attempting to carve it into subtopical narratives. To test how well the models perform on this more challenging use case, we repeated the same process on the following four Covid-related lead paragraphs:
- "The Biden administration is debating a series of steps to further contain the Covid-19 pandemic, which, after 18 months, is again surging in parts of the country where vaccination rates are low. A senior administration health official said the government is actively exploring how to provide extra vaccine shots to vulnerable populations, who officials now increasingly expect will require boosters, as they await the US Food and Drug Administration's full approval of the three vaccines currently authorized for emergency use. The White House on Friday announced a purchase of hundreds of millions of additional Pfizer doses, in part to be prepared in case the booster shots are needed." (CNN)
- "St. Louis County and city health departments recommended on Thursday that vaccinated residents wear masks indoors when among people whose vaccination statuses are unknown, as concern mounts over the delta coronavirus variant. Both health departments issued a joint public health advisory that adjusted their mask guidance for fully vaccinated individuals, following in the footsteps of Los Angeles County. " (The Hill)
- "Pfizer and BioNTech’s Covid-19 vaccine is just 39% effective in Israel where the delta variant is the dominant strain, but still provides strong protection against severe illness and hospitalization, according to a new report from the country’s Health Ministry. The efficacy figure, which is based on an unspecified number of people between June 20 and July 17, is down from an earlier estimate of 64% two weeks ago and conflicts with data out of the U.K. that found the shot was 88% effective against symptomatic disease caused by the variant." (CNBC)
- "Seven months after the first coronavirus shots were rolled out, vaccinated Americans — including government, business and health leaders — are growing frustrated that tens of millions of people are still refusing to get them, endangering themselves and their communities and fueling the virus’s spread. Alabama Gov. Kay Ivey (R) on Thursday lashed out amid a surge of cases in her state, telling a reporter it’s “time to start blaming the unvaccinated folks.” The National Football League this week imposed new rules that put pressure on unvaccinated players, warning their teams could face fines or be forced to forfeit games if those players were linked to outbreaks." (Washington Post)
Here the first lead relates to a mix of actions that partially overlap with the second lead about masking, heavily overlaps with the fourth and is unrelated to the third. In fact, the fourth lead can be thought of as an explainer for the first, as a nuanced form of an entailment task. The results can be seen below:
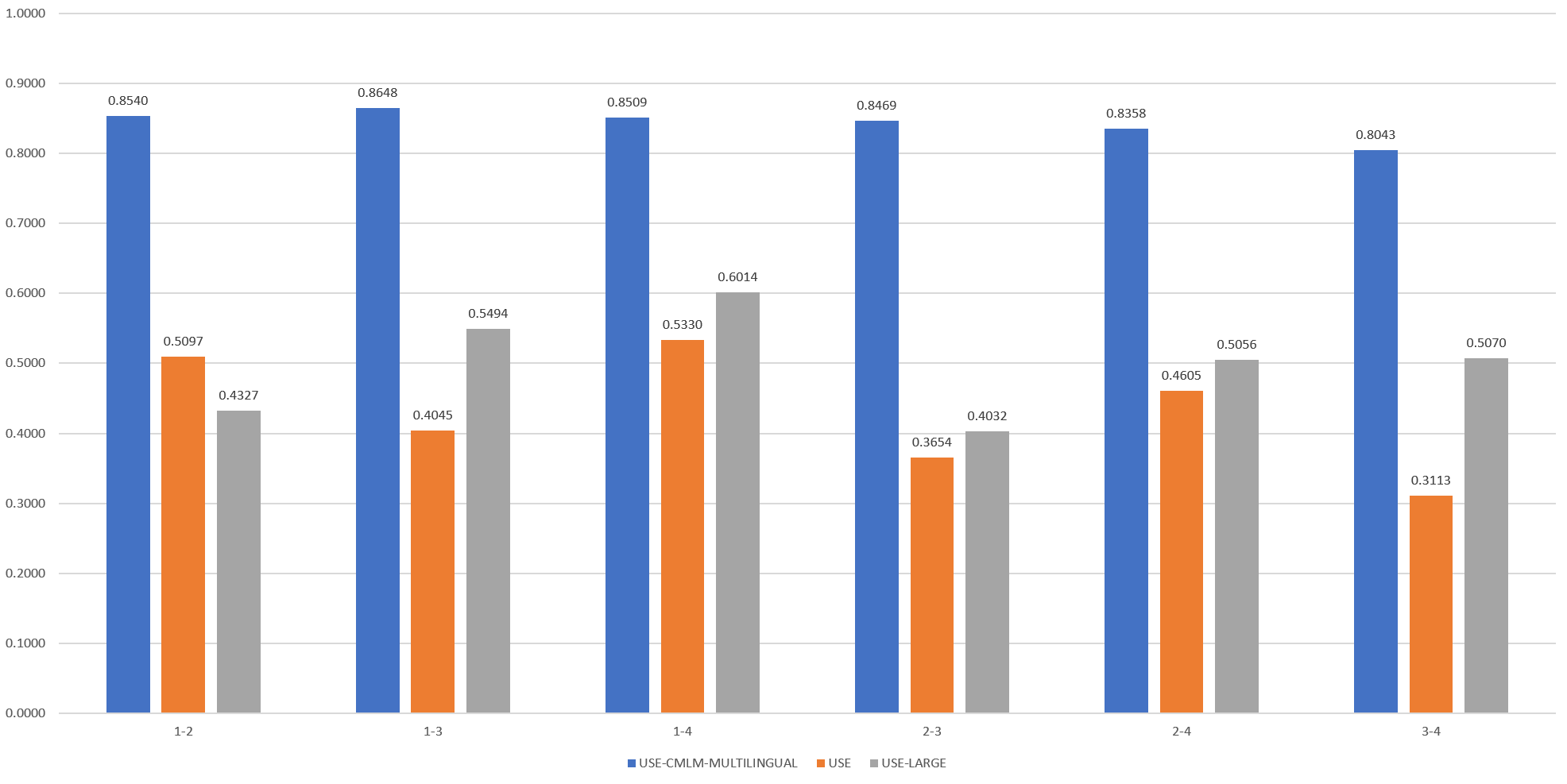
The CMLM Multilingual model does not appear to offer any measurable separation of the four articles. Both USE and USE-Large group leads 1 and 4 as the most similar, as was expected, and 2 (masking) and 3 (delta vaccine efficacy) as among the least similar. Yet, they diverge noticeably for 3-4, where USE-Large scores them as roughly as similar as many of the other sentences, while USE scores them as the least similar. The same situation plays out for 1-3. Human judgement might suggest that lead 3 should be scored as the least similar, since it is the odd one out, reporting on vaccine efficacy in another country, while the other three sentences are about domestic policy. None of the three clearly group the sentences, though in this case USE-Large results in a more muddy grouping, while USE at least separates out the vaccine efficacy lead as the least similar, groups 1-4 (a nuanced form of entailment) as the most similar, and sees masking requirements as being more similar to the policy proscriptions of the first, but still highly similar to the policy enactments of the fourth.
Looking across these three graphs, it appears that CMLM Multilingual, like most BERT architectures, struggles to provide clear delineation for similarity ranking. There is no clear winner between USE and USE-Large, despite the latter's formidably greater computational requirements, with USE-Large providing better separation in some situations and USE offering better stratification in others. In two of the three sets, USE-Large resulted in suboptimal groupings compared to human judgement, while even in the first graph, depending on how the sentences are interpreted in terms of primary and subtopical focus, USE's groupings may be seen as at least on par or even more intuitive than USE-Large.
Accuracy aside, however, the fact that USE took just 18 seconds on just 2 cores to complete our computational benchmark compared with 16 minutes across 4 cores for USE-Large suggests that given the lack of a clear accuracy winner, USE is the clear favorite based on speed, performing inference 106x faster than USE-Large in a CPU-only environment.
The extreme performance of the DAN-based USE model suggests an interesting possibility: processing the full text of each article, instead of just its lead paragraph. To test this approach, we first checked the computational feasibility of fulltext analysis using the full article text of the first article from the set above (the CNN article), which totals 1,725 words and 10,781 characters and the second (the The Hill article) (385 words / 2,524 characters). Neither the USE nor the USE-Large models truncate their inputs within this textual length range, meaning we can test on the entire document text. We scored the full text of the CNN article through both models 100 times using GNU parallel with four threads and a batch size of one.
- USE. The USE model is so efficient that a batch size of 1 is insufficient to fully utilize the encoder. The CNN article took just 1.4 seconds at 80% CPU utilization to process all 100 iterations and the The Hill article took just 1.3 seconds at 70% CPU. As reflected in the original paper, despite the USE model's O(n) complexity, its runtime remains essentially flat as the number of words increases, meaning it can efficiently handle article fulltexts with minimal speed decrease.
- USE-Large. The USE-Large model saturates the CPUs even with a batch size of 1, taking 1m27s at 390% CPU for the CNN article (it takes 1.5 seconds to process a single copy) and 14 seconds at 390% CPU for the The Hill article. Note the exponentially higher runtime for the longer article, reflecting its O(n^2) complexity and rapid increase in runtime with word length.
To test whether adding the fulltext would change the similarity scores dramatically, we repeated the same four-passage test, this time with:
- 1: Lead paragraph of CNN article from above.
- 2: Lead paragraph of The Hill article from above.
- 3: Fulltext of CNN article from above.
- 4: Fulltext of The Hill article from above.
The final results can be seen below:
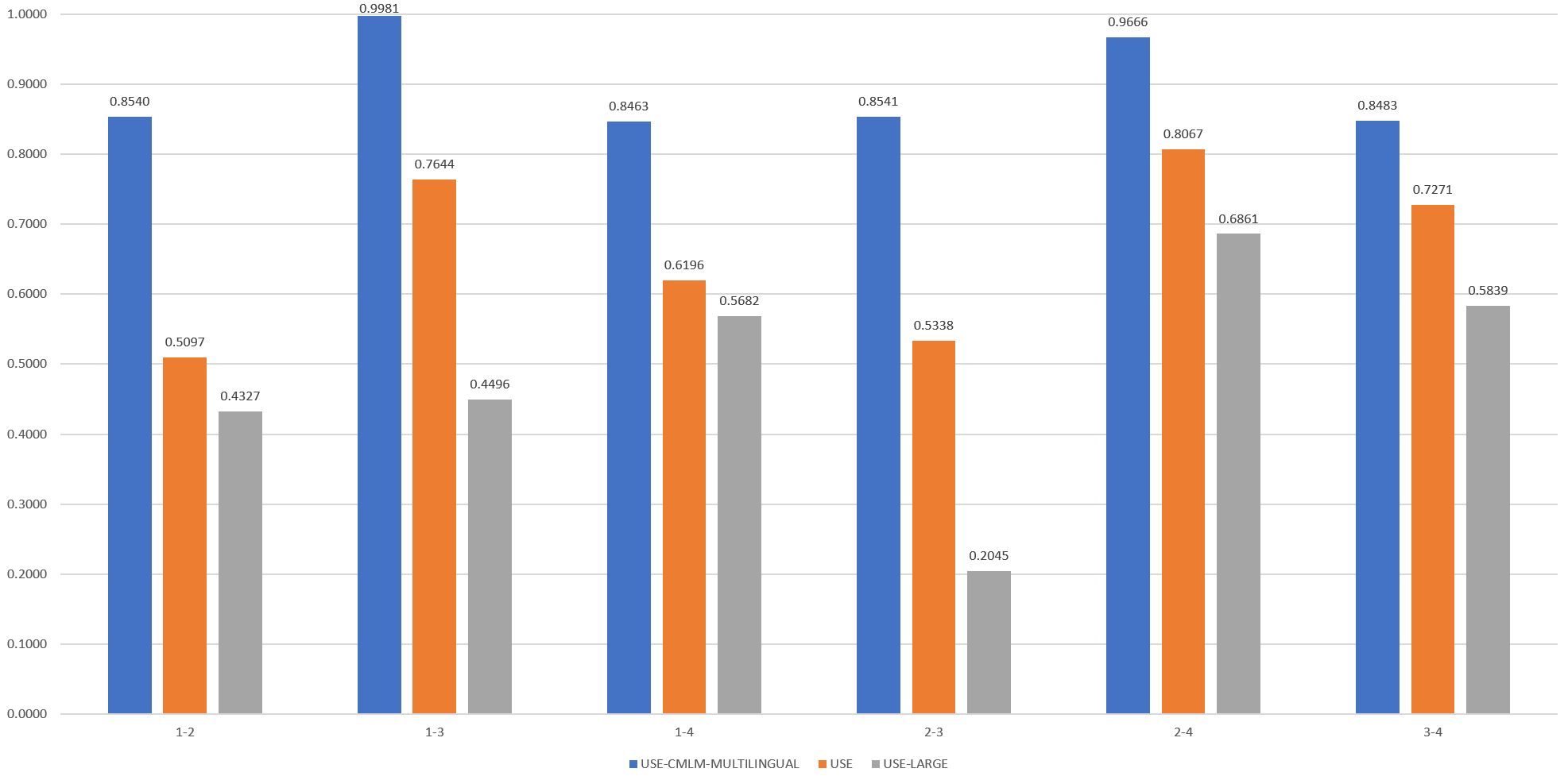
Here even the CMLM Multilingual model accurately differentiates the two lead-fulltext pairs (1-3 and 2-4), but scores the others relatively similarly. Strangely, USE-Large scores the lead and fulltext versions of CNN as among the least similar, though it scores the two versions of the The Hill article as the most similar. This suggests that the additional text changes its embeddings dramatically, while USE's embeddings are changed less. This is problematic for retrieval, as it means that a highly similar snippet will be ranked as having low similarity to even the original article from which it came.
According to USE-Large, the most similar three pairings are, in order, The Hill Lead – The Hill Fulltext, CNN Fulltext – The Hill Fulltext and CNN Lead – The Hill Fulltext. In contrast, according to USE, the most similar three pairings are, in order, The Hill Lead – The Hill Fulltext, CNN Lead – CNN Fulltext and CNN Fulltext – The Hill Fulltext. While the first two are the same for both models, USE's grouping of the two fulltext articles together is more intuitive than USE-Large's grouping the CNN lead with the The Hill's fulltext, since the CNN lead is so different.
Finally, what if we repeat our Covid-19 analysis from above, in which we tested four Covid-related lead paragraphs, but replace the lead paragraphs with the fulltext of those four articles? Thus, instead of the four lead paragraphs below, we use the fulltext of the four articles:
- "The Biden administration is debating a series of steps to further contain the Covid-19 pandemic, which, after 18 months, is again surging in parts of the country where vaccination rates are low. A senior administration health official said the government is actively exploring how to provide extra vaccine shots to vulnerable populations, who officials now increasingly expect will require boosters, as they await the US Food and Drug Administration's full approval of the three vaccines currently authorized for emergency use. The White House on Friday announced a purchase of hundreds of millions of additional Pfizer doses, in part to be prepared in case the booster shots are needed." (CNN)
- "St. Louis County and city health departments recommended on Thursday that vaccinated residents wear masks indoors when among people whose vaccination statuses are unknown, as concern mounts over the delta coronavirus variant. Both health departments issued a joint public health advisory that adjusted their mask guidance for fully vaccinated individuals, following in the footsteps of Los Angeles County. " (The Hill)
- "Pfizer and BioNTech’s Covid-19 vaccine is just 39% effective in Israel where the delta variant is the dominant strain, but still provides strong protection against severe illness and hospitalization, according to a new report from the country’s Health Ministry. The efficacy figure, which is based on an unspecified number of people between June 20 and July 17, is down from an earlier estimate of 64% two weeks ago and conflicts with data out of the U.K. that found the shot was 88% effective against symptomatic disease caused by the variant." (CNBC)
- "Seven months after the first coronavirus shots were rolled out, vaccinated Americans — including government, business and health leaders — are growing frustrated that tens of millions of people are still refusing to get them, endangering themselves and their communities and fueling the virus’s spread. Alabama Gov. Kay Ivey (R) on Thursday lashed out amid a surge of cases in her state, telling a reporter it’s “time to start blaming the unvaccinated folks.” The National Football League this week imposed new rules that put pressure on unvaccinated players, warning their teams could face fines or be forced to forfeit games if those players were linked to outbreaks." (Washington Post)
The results can be seen below:
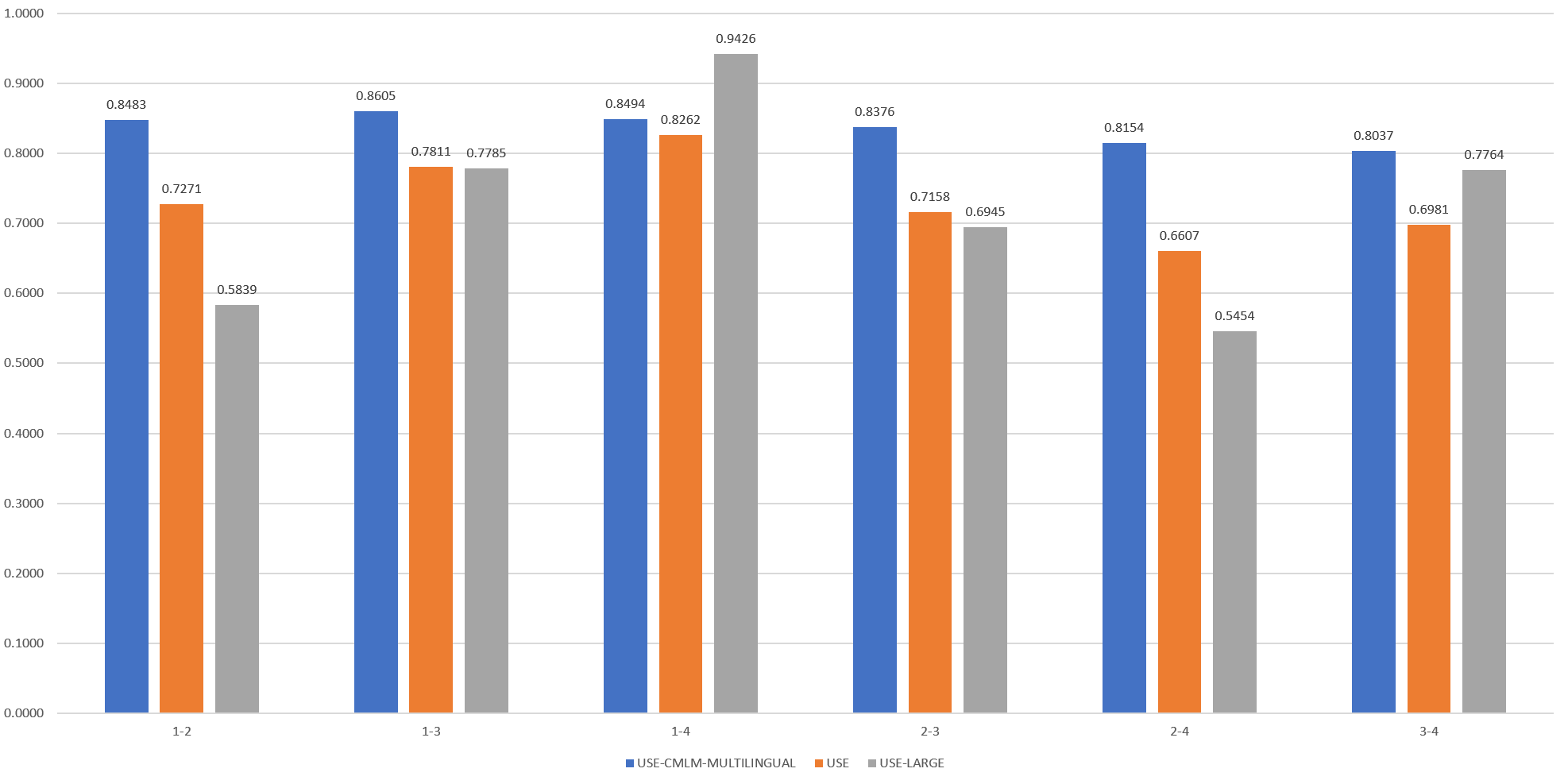
As with the lead paragraph analysis, CMLM Multilingual does not appear to distinguish the four articles in a meaningful way. USE and USE-Large both group articles 1 and 4 as the most similar, though strangely, both also group 1 and 3 as the second most similar and both yield a nearly identical score for the pairing. A closer look at the CNBC article suggests why: while the opening of the article focuses on Israel's vaccine efficacy report, the remainder of the article discusses more generalized Covid-19 news in the US, ranging from masking to social distancing to vaccine resistance, closely matching the first article. USE and USE-Large differ the most on 1-4 (essentially an entailment pair), where USE-Large rates the pair as far more similar than USE and for 1-2 and 2-4, in which USE-Large scores them noticably less similar than USE.
It is clear that expanding to fulltext from lead paragraphs changes the results and that USE and USE-Large again agree at the macro-level and disagree on the other rankings, though neither is clearly "better" than the other. On the other hand, USE is clearly the more computationally scalable.
What if we return to our original article set of two Covid-related articles and two relating to Nord Stream 2 and use their fulltext instead of their lead paragraphs? Recall that these are the lead paragraphs of the four articles:
- "A major Texas hospital system has reported its first case of the lambda COVID-19 variant, as the state reels from the rampant delta variant Houston Methodist Hospital, which operates eight hospitals in its network, said the first lambda case was confirmed Monday Houston Methodist had a little over 100 COVID-19 patients across the hospital system last week. That number rose to 185 Monday, with a majority of those infected being unvaccinated, according to a statement released by the hospital Monday" (ABC News)
- "When asked which poses a greater risk to their health, more unvaccinated Americans say the COVID-19 vaccines than say the virus itself, according to a new Yahoo News/YouGov poll — a view that contradicts all available science and data and underscores the challenges that the United States will continue to face as it struggles to stop a growing pandemic of the unvaccinated driven by the hyper-contagious Delta variant. Over the last 18 months, COVID-19 has killed more than 4.1 million people worldwide, including more than 600,000 in the U.S. At the same time, more than 2 billion people worldwide — and more than 186 million Americans — have been at least partially vaccinated against the virus falling ill, getting hospitalized and dying" (Yahoo News)
- "In the midst of tense negotiations with Berlin over a controversial Russia-to-Germany pipeline, the Biden administration is asking a friendly country to stay quiet about its vociferous opposition. And Ukraine is not happy. At the same time, administration officials have quietly urged their Ukrainian counterparts to withhold criticism of a forthcoming agreement with Germany involving the pipeline, according to four people with knowledge of the conversations" (Politico)
- "The U.S. and Germany have reached an agreement allowing the completion of a controversial Russian natural-gas pipeline, according to officials from Berlin and Washington, who expect to announce the deal as soon as Wednesday, bringing an end to years of tension between the two allies The Biden administration will effectively waive Washington’s longstanding opposition to the pipeline, Nord Stream 2, a change in the U.S. stance, ending years of speculation over the fate of the project, which has come to dominate European energy-sector forecasts. Germany under the agreement will agree to assist Ukraine in energy-related projects and diplomacy" (Wall Street Journal)
Examining the fulltext of each article, we get the following graph:
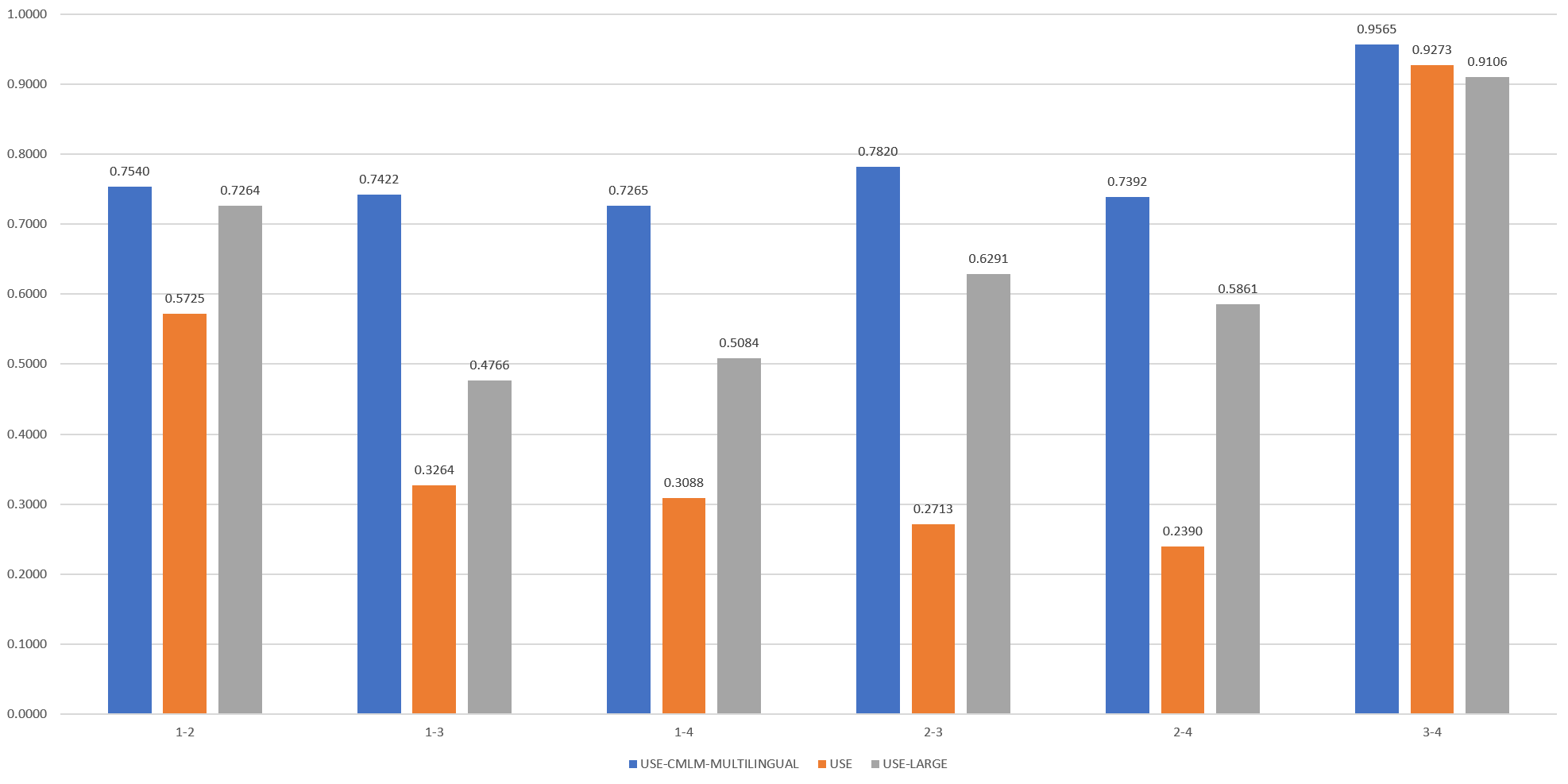
Recall that when we compared these four articles by using only their lead paragraphs, all three models showed high similarity for 3-4, medium to low similarity for 1-2 and low similarity for the other article pairings. This time we can again see high similarity for 3-4, though this time the similarity scores are extremely high. USE and USE-Large both find 1-2 to be the next-similar pairing, though USE-Large again finds them to be more similar than USE. However, the remaining four pairings are dramatically different from their lead paragraph scores.
With lead paragraph scores, USE-Large assigned pairing 1-2 a similarity score of 0.4864 and the four cross-topical pairings ranged between 0.0008 and 0.1324 (a separation of at least 3.67 between the 1-2 score and 2-4 score). In contrast, USE assigned pairing 1-2 a score of 0.3192 and scores of 0.1122 to 0.2103 for the cross-topical pairings, a separation of just 1.5. Using fulltext scores, the difference between USE-Large's 1-2 score and the highest of the cross-topical pairings (2-3) is just 1.15, while the difference between USE's 1-2 score and its highest cross-topical score (1-3) is 1.75. USE-Large's cross-topical scores using fulltext are more difficult to understand, while USE's fulltext scores are more readily interpretable.
This suggests that USE-Large benefits from using short lead paragraphs, both in its inference runtime and accuracy, while USE is so efficient that it can be applied to article fulltext without any slowdown compared with lead paragraph, while its accuracy compared with human intuition is considerably improved.
MULTILINGUAL ACCURACY
Since the CMLM Multilingual model natively supports more than 100 languages, we also wanted to test how well cross-language similarity performs. To this end, we compared the real English language paragraph below with a synthetic paragraph designed to encapsulate a common cross-section of Covid-19 narratives.
- "A major Texas hospital system has reported its first case of the lambda COVID-19 variant, as the state reels from the rampant delta variant Houston Methodist Hospital, which operates eight hospitals in its network, said the first lambda case was confirmed Monday Houston Methodist had a little over 100 COVID-19 patients across the hospital system last week. That number rose to 185 Monday, with a majority of those infected being unvaccinated, according to a statement released by the hospital Monday" (ABC News) (English 1)
- "Covid-19 cases are surging in the country, with hospitals overwhelmed and oxygen cylinders in short supply. Doctors have been sent to staff new Covid-19 wards being opened in multiple hospitals in multiple cities, while delta and lamba variants are spreading and vaccination numbers remain lower than hoped and more than 500 infections were reported, with 10 deaths as the hospital system strained under the sharply rising number of infections." (Synthetic) (English 2)
We also used Google Translate to translate the synthetic paragraph ("English 2") into several other languages:
-
"Los casos de Covid-19 están aumentando en el país, los hospitales están abrumados y los cilindros de oxígeno escasean. Se han enviado médicos al personal de nuevas salas de Covid-19 que se están abriendo en varios hospitales en varias ciudades, mientras que las variantes delta y lamba se están extendiendo y los números de vacunación siguen siendo más bajos de lo esperado y se informaron más de 500 infecciones, con 10 muertes debido a que el sistema hospitalario se tensó. bajo el número cada vez mayor de infecciones." (Spanish)
-
"Les cas de Covid-9 augmentent dans le pays, les hôpitaux étant débordés et les bouteilles d'oxygène en nombre insuffisant. Des médecins ont été envoyés pour doter en personnel de nouveaux services Covid-19 ouverts dans plusieurs hôpitaux de plusieurs villes, tandis que les variantes delta et lamba se propagent et que le nombre de vaccinations reste inférieur à ce qui était espéré et plus de 500 infections ont été signalées, avec 10 décès alors que le système hospitalier était tendu sous la forte augmentation du nombre d'infections." (French)
- "تتزايد حالات الإصابة بفيروس Covid-19 في البلاد ، مع اكتظاظ المستشفيات ونقص أسطوانات الأكسجين. تم إرسال الأطباء إلى عنابر جديدة لفيروس كوفيد -19 للموظفين يتم افتتاحها في مستشفيات متعددة في مدن متعددة ، بينما تنتشر متغيرات دلتا ولامبا ولا تزال أعداد التطعيمات أقل مما كان متوقعًا وتم الإبلاغ عن أكثر من 500 إصابة ، مع 10 وفيات مع إجهاد نظام المستشفى في ظل الارتفاع الحاد في عدد الإصابات." (Arabic)
- "Covid-19 病例在该国激增,医院不堪重负,氧气瓶供不应求。 医生已被派往多个城市的多家医院开设的新 Covid-19 病房,而 delta 和lamba 变种正在传播,疫苗接种数量仍低于预期,据报道有 500 多例感染,由于医院系统紧张,10 人死亡 在感染人数急剧上升的情况下。" (Chinese Simplified)
- "Число случаев Covid-19 растет в стране, больницы переполнены, а кислородные баллоны не хватает. Врачи направили для персонала новые отделения Covid-19, которые открываются в нескольких больницах в нескольких городах, в то время как распространяются варианты дельта и ламба, а количество вакцинаций остается ниже, чем ожидалось, и было зарегистрировано более 500 случаев заражения, 10 из которых умерли из-за напряжения больничной системы в условиях резко возрастающего числа инфекций." (Russian)
- "Covid-19 ဖြစ်ပွားမှုများမှာဆေးရုံများနှင့်အောက်စီဂျင်ဆလင်ဒါများပြတ်လပ်မှုနှင့်အတူတိုင်းပြည်အတွင်းမြင့်တက်လျက်ရှိသည်။ မြို့ကြီးများရှိဆေးရုံများစွာတွင် Covid-19 ရပ်ကွက်အသစ်များဖွင့်လှစ်ထားသော Covid-19 ရပ်ကွက်အသစ်များကို ၀ န်ထမ်းများထံသို့ဆရာဝန်များစေလွှတ်ခဲ့သည် ရောဂါကူးစက်မှုသိသိသာသာမြင့်တက်အရေအတွက်အောက်မှာ။" (Burmese)
- "ผู้ป่วยโควิด-19 กำลังเพิ่มขึ้นในประเทศ โดยโรงพยาบาลล้นมือและถังออกซิเจนขาดตลาด แพทย์ถูกส่งไปยังเจ้าหน้าที่หอผู้ป่วย Covid-19 แห่งใหม่ที่กำลังเปิดในโรงพยาบาลหลายแห่งในหลายเมืองในขณะที่เดลต้าและแลมบากำลังแพร่กระจายและจำนวนการฉีดวัคซีนยังคงต่ำกว่าที่คาดหวังและมีรายงานการติดเชื้อมากกว่า 500 รายโดยมีผู้เสียชีวิต 10 รายเนื่องจากระบบโรงพยาบาลตึงเครียด ภายใต้จำนวนผู้ติดเชื้อที่เพิ่มขึ้นอย่างรวดเร็ว" (Thai)
- "Covid-19-Fälle nehmen im Land zu, Krankenhäuser sind überlastet und Sauerstoffflaschen knapp. Ärzte wurden geschickt, um neue Covid-19-Stationen zu besetzen, die in mehreren Krankenhäusern in mehreren Städten eröffnet werden, während sich Delta- und Lamba-Varianten ausbreiten und die Impfzahlen niedriger als erhofft bleiben und mehr als 500 Infektionen gemeldet wurden, mit 10 Todesfällen, da das Krankenhaussystem angespannt war unter den stark steigenden Infektionszahlen." (German)
We then ran several comparisons:
- The English lead paragraph against the synthetic one to test how closely it scores two monolingual passages that are highly similar.
- The English lead paragraph against two machine translations (French and Spanish) of the English synthetic paragraph to see whether it yields a different score between the original English synthetic paragraph and two translations of that synthetic paragraph.
- The English synthetic paragraph against a range of machine translations of itself. We specifically did not use the Bitext version of the USE CMLM model (paper), since we are interested in generalized cross-language similarity scoring, rather than parallel text retrieval.
The final scores for each pair are seen below, with "English1" referring to the English lead paragraph and "English2" referring to the English synthetic paragraph and all of the other languages referring to the Google Translate machine translations of the synthetic paragraph.

A perfect model should yield the exact same high score for the three English1-English2/Spanish/French columns and a separate, near-1.0, score for all of the remaining columns, reflecting that the first three columns are comparing the same English lead paragraph against a highly topically similar English passage and two translations of that second passage, while the remaining columns are all comparing exact duplicates of that second passage translated into various languages.
Perhaps most strikingly clear from the chart above is that despite being a multilingual model supporting more than 100 languages, the CMLM Multilingual model yields extremely different results across language pairings (given that this is a BERT architecture with its attendant high similarity scores, the results above are even more notable). It is certainly possible that a portion of these differences lies in accuracy differences across Google Translate's support for each language, though given the narrow topical focus, one would expect less variation even with widely differing translation accuracies.
The English1-English2/French/Spanish results are encouraging in that they are relatively similar, though the translated scores are slightly lower. Yet, when comparing the machine translations of the synthetic paragraph to one another, clear differences emerge among not just high resource and low resource languages, but structural grammatical differences. Spanish and French have extremely high similarity scores, while Thai and Burmese have very low scores.
Thus, in a production application, the Spanish article would appear to be highly similar to the English synthetic one, while the Thai and Burmese versions would appear to be far less relevant and the Arabic version would be significantly less relevant than the Russian version and so on.
It is critical to note that these differences may encode, at least in part, the differences in Google Translate accuracy, but additional experiments taking a small number of articles in the native languages of the pairs above for which an English human translation was available exhibited similar macro-level differences, suggesting this is inherent to the model.
CONCLUSION
Putting this all together, from a computational resourcing standpoint, the CMNM Multilingual model is not tractable to run at any real scale without hardware acceleration and even with GPU/TPU acceleration would likely need to be restricted to just the lead paragraph (perhaps split with the last paragraph for increased accuracy). Most importantly, however, its accuracy at matching human intuition is much more limited compared with the other two models, with its results often difficult to understand – a common issue with BERT models. The ability of the model to natively compute scores for more than 100 languages is a differentiator with the monolingual English USE and USE-Large models, but the results above show that the scores differ so dramatically across language pairs that it would be difficult to use it for real-world cross-language similarity scoring.
While having just a quarter of the runtime of the Mulilingual model, USE-Large nonetheless would require substantial CPU or GPU/TPU acceleration to run tractably on news content. Its O(n^2) scaling makes it intractable to run on anything beyond the lead paragraph even with acceleration and its results are mixed – overall it performs highly similar to USE, but where they differ it is unclear whether USE-Large is more or less accurate in each scenario.
Finally, USE is so efficient that even with large batch sizes it is difficult to consume even a portion of the CPU resources of a quad-core system and does not require any acceleration. Its nearly flat runtime scaling means that it can be applied to article fulltext without a measurable decrease in throughput, opening the possibility of computing scores across the entirety of each article. Moreover, its extreme efficiency opens the door to additionally computing sentence-level embeddings for use with subarticle scoring. Applied to fulltext, its scoring trends are closely aligned with USE-Large and where they differ neither model is the clear winner, suggesting USE's vastly great computational efficiency makes it the clear winner for scalable English-only similarity scores.
In addition, preliminary work testing the three model's robustness to machine translation error suggests USE exhibits much higher robustness to translation error than CMLM or USE-Large. For these tests, an original English paragraph was hand translated into several languages by a native speaker and then machine translated back into English using both high-quality machine translation like Google Translate and several other services that trade lower accuracy for higher speed. At least in the small scale experiments conducted to date, USE exhibited greater robustness to translation error in scoring the similarity of the low-quality translations against the original English passage.
In conclusion, USE's superior computational efficiency, minimal computational requirements, ability to process fulltext with minimal speed reduction and comparable accuracy to USE-Large recommends it for the kinds of global scale news similarity scoring that GDELT requires.