
One of the greatest challenges in analyzing video content over time and space is the unique nature of historical and citizen-created video. From the kinescopic recordings that define early recorded television to the grainy, shakey, blurry pixelated content that often defines cell-phone recordings of important events, such video can strongly resist analysis by traditional video analysis tooling, requiring preprocessing to enhance it. Here we look at four AI-powered image and video enhancement tools across colorizing, upscaling and face restoration. As the terms imply, colorization refers to converting historical grayscale imagery and video into full color. AI upscaling increases the resolution of content by using AI to hallucinate the new pixels, resulting in rich sharp detail in the resized imagery, rather than traditional image resizing that results in blurry pixelated images. Finally, face restoration is a specialized process that identifies human faces within an image and applies a dedicated generative model to create a high-resolution face that would yield the degraded face in the image. For example, when analyzing a face in a blurry grainy cellphone image, a face restoration model will hallucinate a human face that, under the degradations and artifacts present in the image, would look the way the face in the image does. This is not a definitive face, since many faces could resolve to the face in the image, but typically results in a face highly similar to the one that actually appeared in the image.
To explore the ability of each tool to restore kinescopic television recordings, we'll extract three frames from this Colgate Comedy Hour footage of Abbott and Costello, while for a more modern example we'll use this 720×900 cellphone video with the trademark blurriness and soft grain of a micro-aperture lens.
DeOldify
First, let's look at simple colorization. While colorization has been computerized for several decades, DeOldify is an example of a more modern AI-powered colorization engine. Unlike traditional computer color conversion that often used color lookups tailored to each specific film manufacturer, model and year, AI colorization typically uses generalized GAN training that does not take into account information about the source film, which can impact its accuracy.
DeOldify offers two Colab implementations one for still images and one for video.
Let's start with this 1943 greyscale still image from the Library of Congress:

Here is the colorized version created using the image Colab:

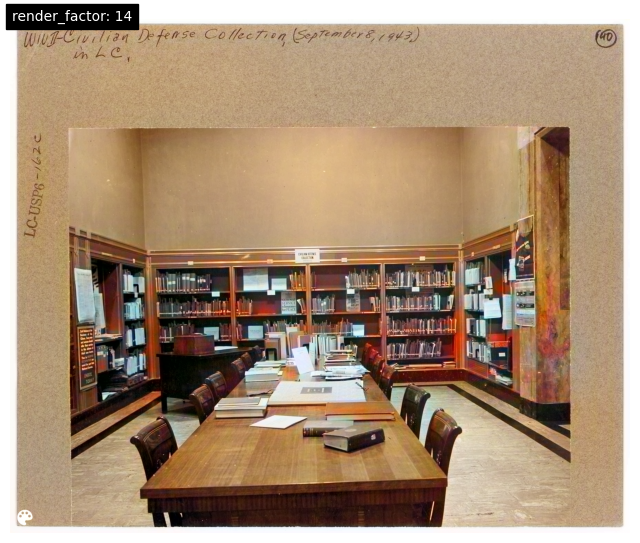
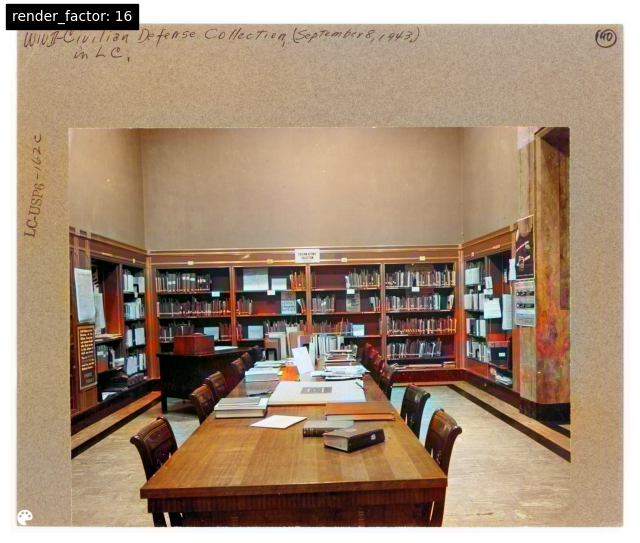
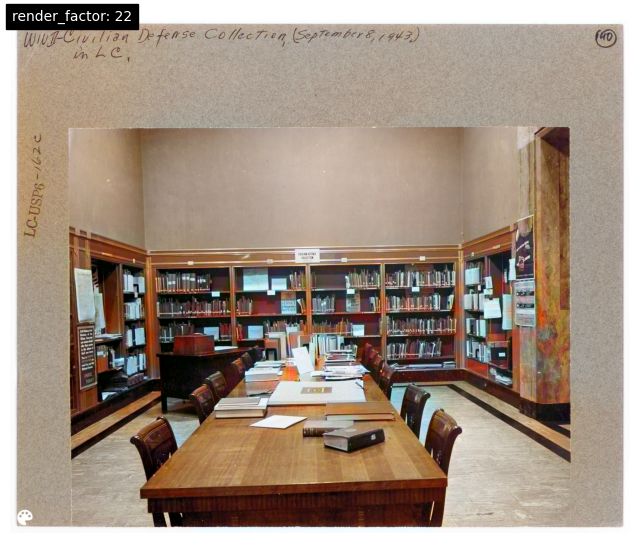
DeOldify's model offers a parameter called "render_factor" that controls the color saturation and has an outsized impact on the colorization appearance. Here is the same image under a few different parameters to show its impact:



What about a video? Using the video Colab here is a side-by-side of the original and colorized Abbott and Costello kinescope:

The kinescope's poor quality detracts substantially from the result, but nevertheless it showcases the tool's ability to perform full video colorization.
Microsoft Old Photo Restoration
Our video colorization example above suffers heavily from the extremely poor quality of the underlying kinescopic recording. Image restoration tools are designed to repair the kind of artifacts commonly found in old imagery.
Let's look at a dedicated historical image restoration toolkit called Old Photo Restoration from Microsoft, which conveniently offers a web-based demo site. The original source footage on YouTube is 320×240. Since Microsoft's tool offers only restoration, not upscaling, we'll simply resize YouTube's player window to 1622×1138 pixels and capture three screen captures of different scenes that stress the restoration process in different ways. Since Microsoft's tool supports face restoration, we'll include different facial orientations and exposures to test its ability to perform face reconstruction.
Here is our first frame. In the trademark look of kinescopes, it has extreme blurriness, smearing, dark haloing, high compression artifacts from the low-quality digitization and myriad other artifacts.

The restored version appears below. In this case, the restored image actually appears worse, with much higher artifacting on Costello's jacket:

Here is a second image. In this case, one face is directed forward and the other is at a manageable tilt, suggesting face recovery should be activated:

The final result is as poor as the first image. Face restoration was activated for Costello's face, but we can see it actually made the result far poorer:

Finally, the third source image was selected to yield sufficient source detail in the two faces to test face restoration under ideal circumstances:

While the rest of the image has the same increased artifacting, for the first time we can see positive results from the face restoration. Both faces have uncanny detail, including lateral canthal lines, subtle wrinkles on the forehead and visible separation between the iris, pupil and sclera. This offers the first glimpse of the power of face restoration, even for extremely degraded content such as kinescope recordings.

Here are the source and restored versions of the faces side-by-side to show the uncanny facial detail hallucinated by the model:

What about a more modern example? Here is a frame from a cellphone video with the trademark blurriness and soft grain of a modern smartphone's micro-aperture lens:

As with the Abbott and Costello footage, parts of the image actually appear worse, though the texture in the floor is enhanced, as is the Ukrainian trident on Zelenskyy's shirt. As with the third Abbott and Costello frame above, the faces here appear eerily enhanced:

Here are the source and restored faces side-by-side. The uncanny facial detailing is clearly visible:

The toolkit appears less useful for restoring overall fine image detail, but does a remarkable job at face restoration.
Video2X / Waifu2x
Video2x is an upscaling toolkit that offers waifu2x as one of its models. This is an end-to-end video-to-video upscaling tool that accepts as input an MP4 video file and outputs an upscaled version of the video.
Let's first test Waifu2x itself, which offers a still-image upscaling demo that exposes both style (artwork vs photograph) and noise reduction options. Comparing the source and upscaled/NR versions side-by-side, we see no obvious differences between them:

Let's try Video2x's video implementation. While there is a Colab implementation of Video2x, this short 1m19s video exceeded the base Colab execution limits even with its T4 GPU offering, so we installed Video2x on a GCE VM with a V100 and used the containerized version. Unfortunately, we ran into GPU errors with the most recent 5.0.0-beta6 version, so we reverted to the 5.0.0-beta4-cuda-patched container, which worked on our V100:
docker run --gpus all -it --rm -v $PWD:/host ghcr.io/k4yt3x/video2x:5.0.0-beta4-cuda-patched -i source.mp4 -o output.mp4 -p3 -l info upscale -h 720 -n3
Video2x upscales the entire video, but to compare the source and upscaled versions, we have extracted our same three frames and displayed them side-by-side below:



Unlike Microsoft's tool, Video2x does not offer face restoration, so the faces here are upscaled in the same manner as the rest of the frame. Comparing each of the three frames from source to upscaled versions, perhaps the greatest change is that the upscaled versions are hyper-smoothed to the point of almost appearing painterly. Costello's plaid jacket is transformed to horizonal prison stripes and both actors' faces are rendered almost plastic-like. The painterly effect is interframe-stable, but when viewed as a video yields the effect of a hyper-realistic animated short, rather than live-action footage. The MPEG compression of the source content is completely eliminated, but at the cost of being transformed to an artistic-like rendering.
Real-ESRGAN + GFPGAN
Finally, let's look at Real-ESRGAN, which, like the Microsoft tool, performs both upscaling and face restoration. For face restoration it uses GFPGAN, which also supports colorization, though that feature is not exposed in the pipeline used here. While there is a Colab implementation, here we used a V100 and followed the installation instructions:
git clone https://github.com/xinntao/Real-ESRGAN.git cd Real-ESRGAN pip3 install basicsr pip3 install facexlib pip3 install gfpgan pip3 install -r requirements.txt python3 setup.py develop time python3 ./inference_realesrgan.py -n RealESRGAN_x4plus -i input -o output --outscale 4 --face_enhance
Let's look at our first Abbott and Costello frame. We've zoomed into just their restored faces below. You can see from Costello's jacket and the information board on the left that the restoration process has actually severely degraded the image overall, but Costello's face and Abbott's ear and sideburn capture the power of the face restoration:

You can download the full-resolution frame (35MB).
{kind=link}
Here is a zoom of the restored faces from frame 2. The level of minute detail in the faces, from the positioning of individual hairs to fine wrinkles to teeth and skin surface texture are stunning, despite the strange artifacts around Costello's eyes from the algorithm misinterpreting the MPEG compression artifacts in the source image:

You can download the full-resolution frame (32MB).
{kind=link}
Perhaps the most stunning example of all is the third frame which looks eerily realistic, if slightly plastic, with a few strange artifacts:

You can download the full-resolution frame (37MB).
{kind=link}
Despite the stunning realism of these reconstructed faces, it is critical to remember that they are nothing more than the AI model's hallucination of a possible face that would reduce, under artifacting, to the face seen in the source image.
What about a more modern example? Here is a still frame from a Russian television news broadcast:
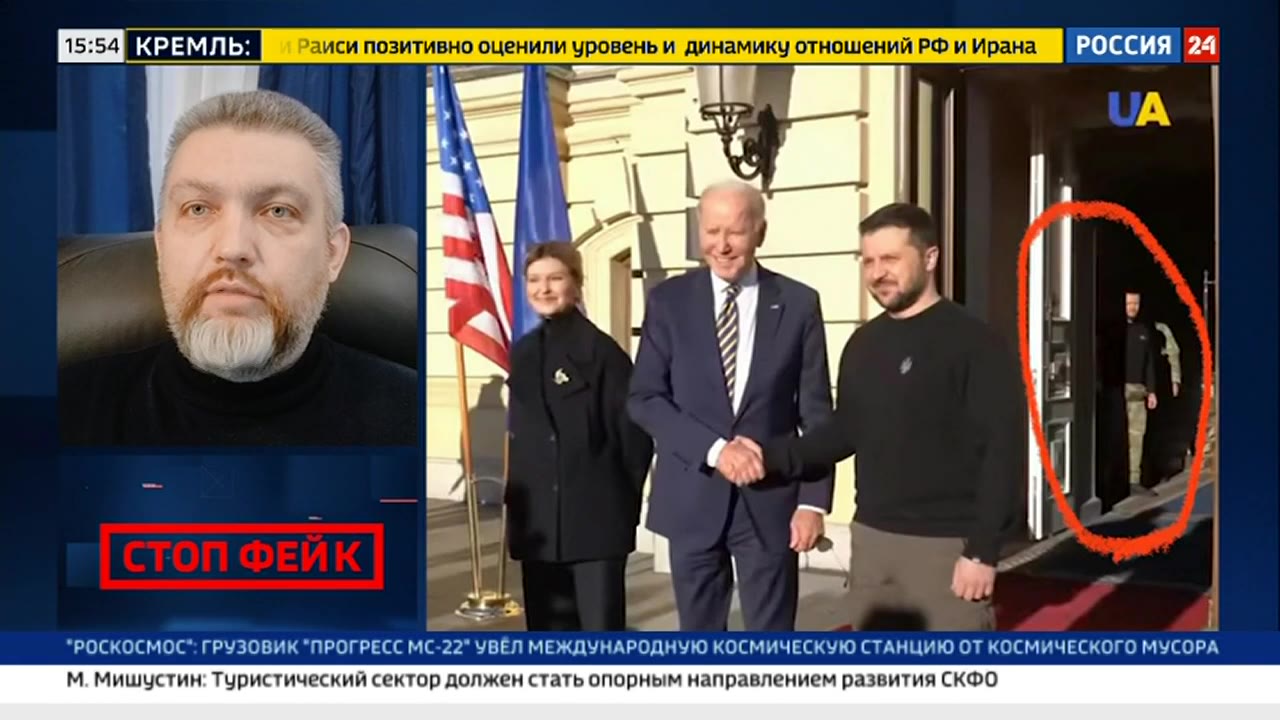
While entirely recognizable, Biden and Zelensky's faces are still highly blurred. Let's zoom into the faces in the restored version below. The faces look like high resolution portraits, with individual hairs visible on Zelenskyy's face. Despite the AI's generative nature, its inability to recognize the face in the background as a face means it did not attempt to construct it.

You can download the full-resolution frame (10MB).
{kind=link}
What about this frame from a different Russian broadcast that was then resized and recompressed?

Here is the restored version. While it missed the two faces in blue and the left and right-most faces, the ones in between are uncannily reconstructed. Note the hallucination of complete detailed iris patterns.

You can download the full-resolution frame (35MB).
{kind=link}
Finally, what about the cell phone video frame? Here is a zoom of the two faces in the original video:

Below is a zoom of the reconstructed faces. Note how in this case the painting on the wall has been completely reimagined as a rough dry textured image that looks nothing like the original, while the faces again have that uncanny realism:

Overall, the image upscaling provided by ESRGAN is less than ideal in these test examples, introducing far more damage and artifacting than was present in the original. In contrast, its facial reconstruction provided through GFPGAN is nothing short of breathtaking in its realism, down to detailed iris patterns. Given the eerie realism of these images, it is important to always remember that these represent generative AI hallucinations of one possible face that could yield the degraded artifact-impaired facial region in the original image. At the same time, as these images attest, the end result often precisely matches the real-life face of the individual, showing the immense power of these tools. In other words, facial restoration is akin to a computerized sketch artist that takes a grainy, blurry, blocky, pixelated image of a face and imagines what the original face might have looked like: the results frequently match the original face uncannily well, but one most always remember that in the end these images are nothing more than an AI sketch artist's hallucinated creation, not a forensic reconstruction, and may alter the original face in subtle ways due to skews in the underlying training data. While the recoveries here appear to be faithful reconstructions of the original faces, there are myriad ethical questions about generative face construction and further testing is required to see how the technology performs across a range of faces from across the world.
While GFPGAN currently only supports still images, not video, it does appear to be deterministic, with multiple runs on the same frame yielding the exact same results. Testing on nearby frames yielded highly similar results, suggesting inter-frame differences are minimal. This means that GFPGAN could be applied to videos by breaking them into a sequence of frames via ffmpeg, applying GFPGAN to each frame and then reconstructing – the stability of the face recovery means that the faces should appear reasonably consistent across frames to yield a reasonable stable video reconstruction.
Putting all of this together, we can see that face restoration represents an entirely new frontier in AI-powered image and video enhancement that has no parallel to past computer-assisted restoration work. Colorization yields strong results, though the inability to provide the model with out-of-band information about the known film stock reduces the ability to incorporate existing domain knowledge to improve accuracy. Image upscaling and damage correction appears weakest in the examples here. While such tools perform extremely well on traditional image recovery tasks (scratched/torn/damaged images or lower-resolution images), the tools appear to perform far more poorly on the specific tasks tested here, such as kinescopic and micro-aperture lens restoration. At the same time, the GAN nature of the underlying models means they could be readily adapted to these specific use cases through fine-tuning. In the end, the results here showcase the potential of AI-powered enhancing tools for historical multimedia archives.