Russian television news loves Tucker Carlson, excerpting his show regularly. This makes understanding which clips from his show are aired on Russian media of enormous public interest in understanding the evolving focus of Russian domestic narratives around the war and the insights they can provide into its possible future trajectories. Identifying all of those excerpted clips today requires rapidly skimming a day's broadcasts using the Visual Explorer. Could we instead use facial detection and similarity scanning to index a Russian television news broadcast to identify all appearances of Tucker Carlson across a given broadcast without any human intervention?
Earlier today we showed how an off-the-shelf facial detection tool can be used to annotate a Russian television news broadcast by cataloging all of the places where there are visible human faces. That same tool, "facedetect", has an additional feature that allows a known face to be compared against all of the detected faces, with faces that are above a certain threshold of similarity flagged. In this case, rather than true facial recognition, which utilizes sophisticated facial landmark analysis, this is a more rudimentary image similarity assessment on the cropped facial regions. It also does not associate a face with an identity – it is simply an example of "find more like this" similarity matching like a reverse image search. Yet, despite its more basic approach, it offers the ability to scan a broadcast for a specific face and catalog where it appears with remarkable accuracy.
In the aftermath of the Nord Stream pipeline explosions two weeks ago, Russian media repeatedly played clips from a number of Western media outlets covering the story, including from Tucker Carlson's show. The September 28th 12:15PM broadcast of Информационный канал on Channel One is three hours long with myriad fast cuts (making it more difficult for a human to accurately skim) and includes several clips from Carlson's show, making it an ideal test of how well automated cataloging of his show might work.
While not required for facial matching, we are going to create an annotated animation of the broadcast via the Visual Explorer's 1/4fps preview ZIP file to confirm that facial detection is working reasonably for this broadcast:
apt-get -y install facedetect
apt-get -y install parallel
wget https://storage.googleapis.com/data.gdeltproject.org/gdeltv3/iatv/visualexplorer/1TV_20220928_091500_Informatsionnii_kanal.zip
unzip 1TV_20220928_091500_Informatsionnii_kanal.zip
cd 1TV_20220928_091500_Informatsionnii_kanal
mkdir ANNOT
find . -maxdepth 1 -name "*.jpg" | sort -V | parallel --eta 'facedetect -o ./ANNOT/{.}.annot.jpg -d {}'
cat $(find ./ANNOT/ -maxdepth 1 -name "*.jpg" | sort -V) | ffmpeg -framerate 2 -i - -vcodec libx264 -vf "pad=ceil(iw/2)*2:ceil(ih/2)*2" -y 1TV_20220928_091500_Informatsionnii_kanal.facedetect.mp4
The final annotated video can be seen below:
We can see that while not catching every face, the tool does a quite reasonable job of capturing the majority of faces in the broadcast.
How do we move beyond simply counting faces towards cataloging appearances of a known face?
First, we need an example Tucker Carlson image for the tool to scan the broadcast for. We simply perform a simple Google Images search for Tucker Carlson and select an image of him facing towards the screen in the typical style and lighting of his show. In this case, the fact that he appears for the duration of his broadcasts typically in a studio setting facing directly towards the camera makes this a much easier matching case than other public figures who may appear in a wider range of contexts.
You can see the selected sample image below:

Now, how do we scan an entire broadcast for appearances of his face? The facedetect tool makes this trivially easy, you simply use the "-q" option to tell it to perform a similarity match, pass it the image to be matched against via "-s" and optionally use "–search-threshold" to set the similarity threshold for matches and lastly, pass it the image to scan. The tool then extracts the primary face from the search image, extracts all faces from the image to be scanned, and then performs a similarity match of the search face against all of the faces in the scan image and returns with an exit code of 0 if a match was detected or 2 if no match was detected.
This means that checking whether Carlson appears in a given image is as simple as:
wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/2022-tve-facedetect-scan-tuckerface.png facedetect -q --search-threshold 40 -s ./2022-tve-facedetect-scan-tuckerface.png 1TV_20220928_091500_Informatsionnii_kanal-002350.jpg echo $? 2
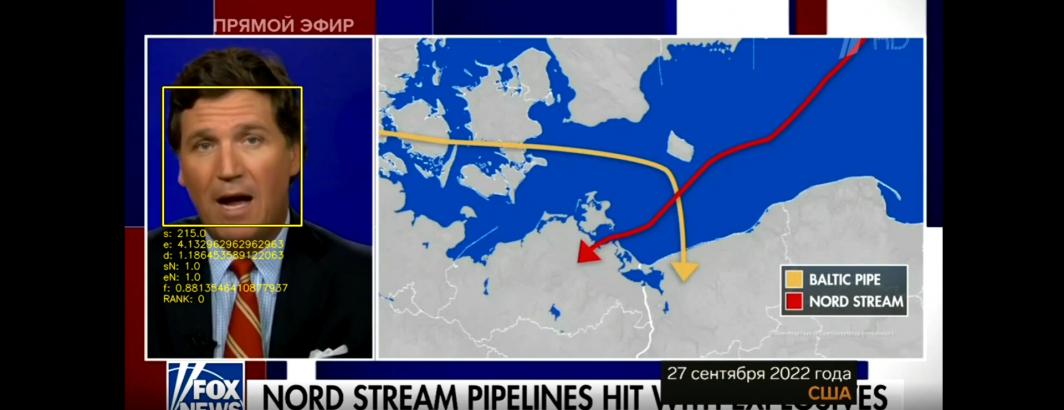
The exit code is 2, indicating that facedetect did not find a match. Indeed, Carlson does not appear in this image:
What about the frame that follows?
wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/2022-tve-facedetect-scan-tuckerface.png facedetect -q --search-threshold 40 -s ./2022-tve-facedetect-scan-tuckerface.png 1TV_20220928_091500_Informatsionnii_kanal-002351.jpg echo $? 0
This time the exit code is 0, indicating a match. Indeed, Carlson appears front and center in this frame:
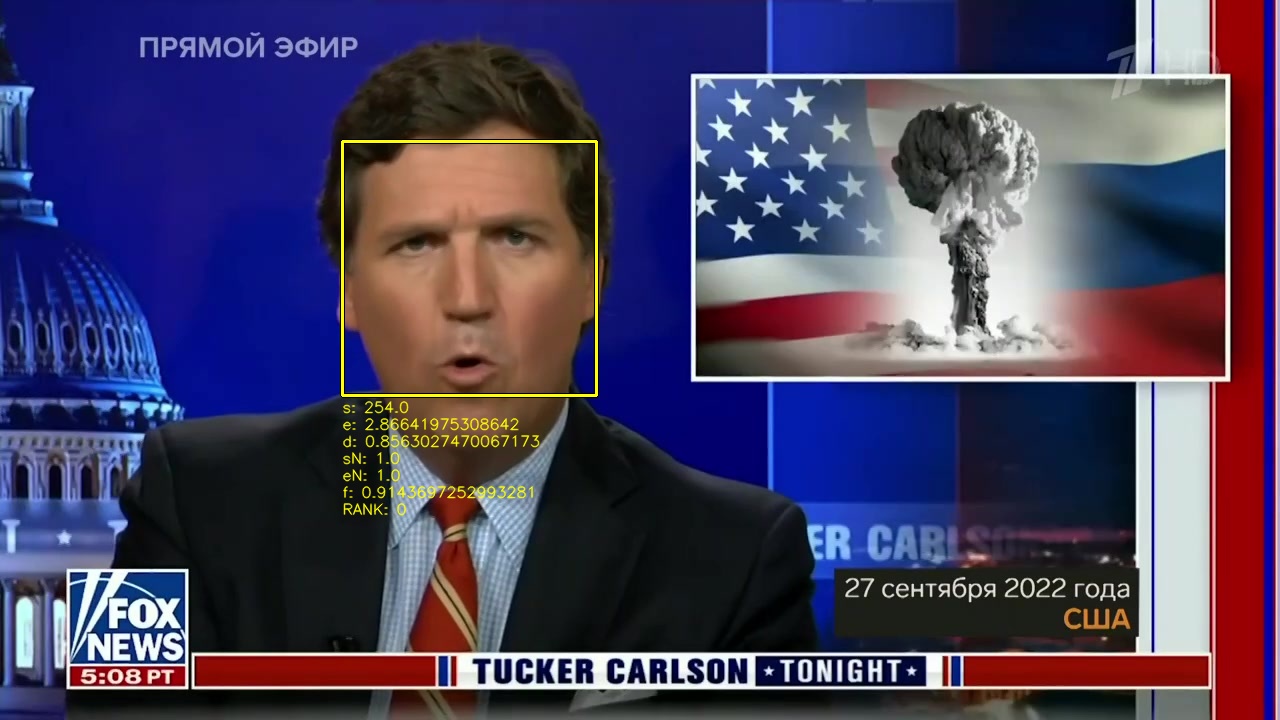
How do we scale this process up to an entire broadcast? We can simply use GNU parallel to run that command over all of the frames in the broadcast and write all matching frames to a file. Scanning a three-hour-long broadcast for Tucker Carlson took just 1m30s on a 64-core CPU-only VM, showing how efficient this system is!
rm MATCHING.TXT.tmp
time find . -maxdepth 1 -name "*.jpg" | parallel --eta 'facedetect -q --search-threshold 40 -s ./2022-tve-facedetect-scan-tuckerface.png {} && echo {} >> MATCHING.TXT.tmp'
sort MATCHING.TXT.tmp > MATCHING.TXT
This yields the following matching frames:
./1TV_20220928_091500_Informatsionnii_kanal-002332.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002337.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002338.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002340.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002341.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002343.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002351.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002353.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002354.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002357.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002358.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002359.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002360.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002361.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002385.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002386.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002390.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002391.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002409.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002416.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002417.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002418.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002419.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002422.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002423.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002426.jpg ./1TV_20220928_091500_Informatsionnii_kanal-002430.jpg
You can view these sequences below:
- 9/28/2022 2:50:24PM
- 9/28/2022 2:51:40PM
- 9/28/2022 2:53:56PM
- 9/28/2022 2:54:16PM
- 9/28/2022 2:55:32PM
- 9/28/2022 2:56:00PM
As you can see, facedetect does fail to identify a few frames in which Carlson makes a more extreme facial expression that deviates too far from the sample image, which would likely be correctly identified by a more advanced similarity metric, but nonetheless, this simple pipeline works exceptionally well!
In the end, we have demonstrated coupling an off-the-shelf face detection tool "facedetect" with the Visual Explorer, finding an image of Tucker Carlson from the web, then scanning an entire 3-hour broadcast for all clips featuring him in just under 1 minute 30 seconds on a CPU-only VM, with the tool correctly identifying all of the clips, even if it missed a few frames within each clip.