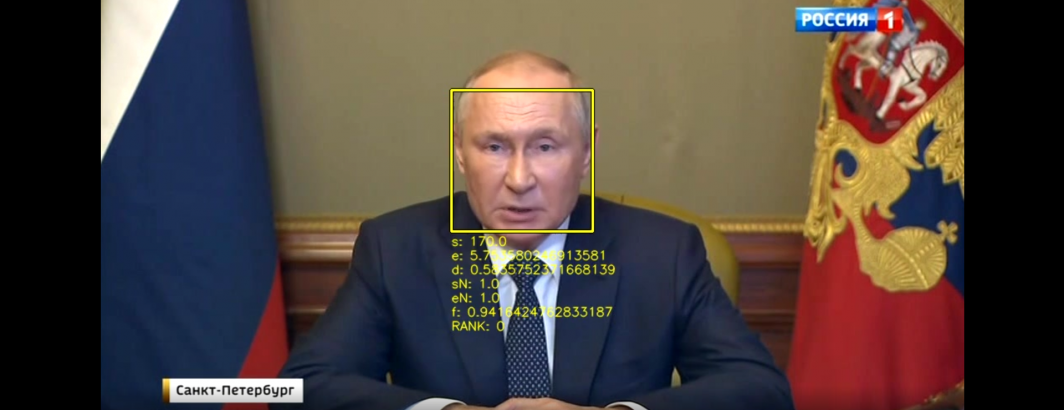
One of the most basic questions in visual storytelling is the degree to which narratives are told through people speaking to the camera. How often do people feature on television news in any form in a typical day? To explore this question, we selected an episode of Russia 1's 60 Minutes program from 8PM last night that is browsable through the Visual Explorer and ran it through an off-the-shelf face detection tool. Note that this is facial "detection" rather than "recognition": we are merely flagging that a human face appeared in an image and drawing a box around it, not attempting to identify who that person is.
Recall that the Visual Explorer works by extracting one frame every 4 seconds and making this available as a thumbnail grid and a downloadable ZIP file of the original full-resolution extracted frames used to make the thumbnails. You can click on the download icon at the top right of the Visual Explorer display for the broadcast to find the link to download this ZIP file. Download and unpack it:
wget https://storage.googleapis.com/data.gdeltproject.org/gdeltv3/iatv/visualexplorer/RUSSIA1_20221010_170000_Vesti_v_2000.zip unzip RUSSIA1_20221010_170000_Vesti_v_2000.zip cd RUSSIA1_20221010_170000_Vesti_v_2000 mkdir ANNOT
We are going to use the open and off-the-shelf "facedetect" tool for facial detection. While this is an older system and struggles with rotated or occluded faces, it is readily available on any Linux system, trivial to install, does not require GPU acceleration and can process an entire hour-long broadcast in just under 30 seconds with full image annotation and debugging enabled, making it ideal for exploratory analysis:
apt-get -y install facedetect apt-get -y install parallel
We can run it on a single frame, taking just 0.7 seconds (the "-o" option tells it to generate an annotated version of the frame with bounding boxes around the detected frames and the "-d" option tells it to add diagnostic statistics beneath each bounding box):
time facedetect -o RUSSIA1_20221010_170000_Vesti_v_2000-000001.annot.jpg -d RUSSIA1_20221010_170000_Vesti_v_2000-000001.jpg 448 144 177 177 270 94 158 158
The two output rows are the pixel dimensions of the bounding box around the two detected faces, which can be seen in the final annotated frame below:

Using GNU parallel we can trivially run this pipeline across the entire broadcast:
find . -maxdepth 1 -name "*.jpg" | sort -V | parallel --eta 'facedetect -o ./ANNOT/{.}.annot.jpg -d {}'
As you can see, running facedetect is trivial. We use "find" to bypass the shell's globbing limitations and GNU parallel to run facedetect over all of the frames in parallel across all available CPUs. Like above, we ask facedetect to output an annotated version of each frame that draws a box around each detected face and writes out a set of diagnostic information about each detected face.
That is literally all there is to it! The end result is a directory of annotated images.
To make it easier to understand how these annotations might be useful in understanding the visual narrative of a broadcast (as well as to better understand its limitations), we use ffmpeg to assemble these frames into a movie:
cat $(find ./ANNOT/ -maxdepth 1 -name "*.jpg" | sort -V) | ffmpeg -framerate 2 -i - -vcodec libx264 -vf "pad=ceil(iw/2)*2:ceil(ih/2)*2" -y RUSSIA1_20221010_170000_Vesti_v_2000.facedetect.mp4
You can see the final result below, taking just 35 seconds from downloading the ZIP file to viewing the final annotated MP4 file!