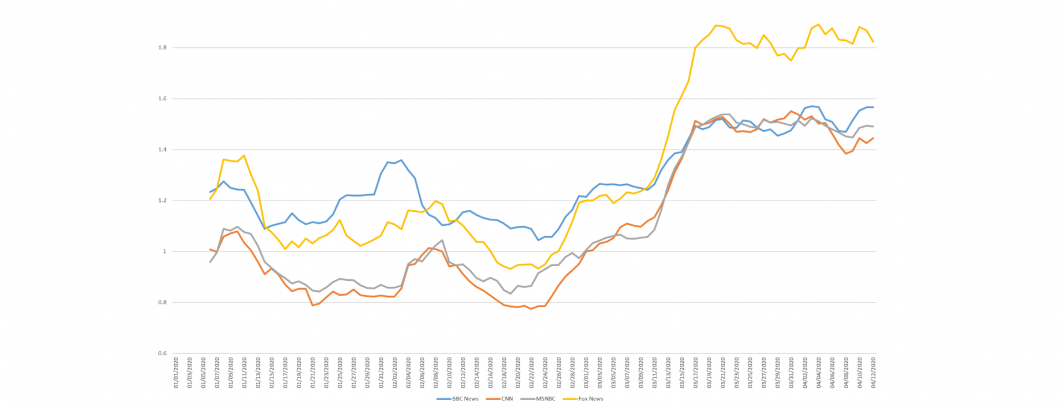
Has the election of Donald Trump or the Covid-19 pandemic changed the very pronouns that television news uses? Last year we showed how ingroup/outgroup language has measurably changed on television news. What about the more basic "us/we" versus "i/me"?
The timeline below shows a 6-month rolling average of the monthly density of "i" and "me" as a percentage of all words spoken on BBC News (2017-present) and CNN/MSNBC/Fox News (July 2009-present). Beginning in early 2012 the three US stations break apart, with MSNBC using the highest density of i/me , before reconverging in the aftermath of Trump's election and tightly aligning by the end of his first year in office. BBC is around half a percent below its US counterparts and has been remarkably stable in its usage.
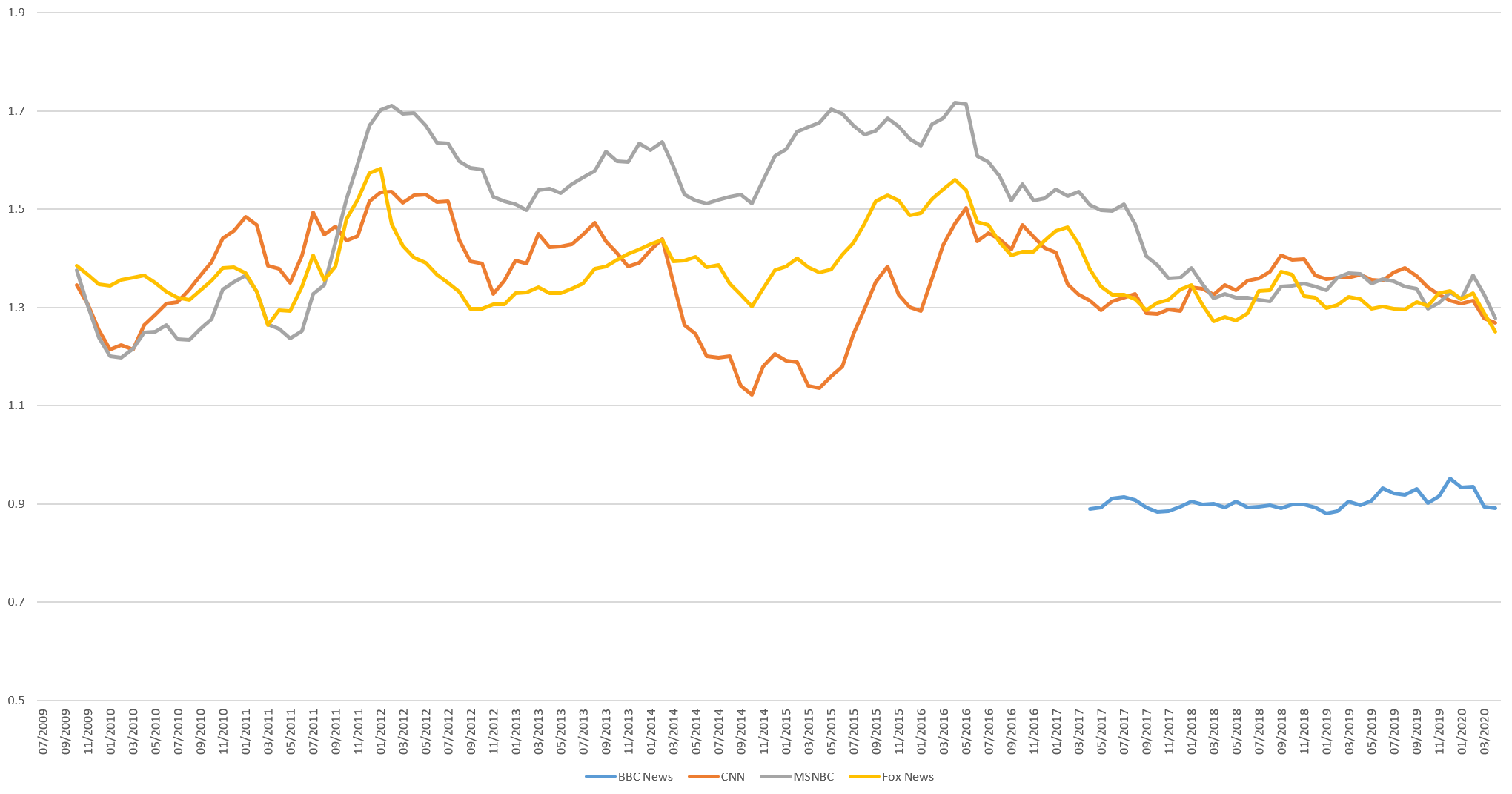
In contrast, CNN and MSNBC have been largely in lockstep in their use of "us" and "we" over the past decade, while Fox News has always been about a tenth of a percent higher. Since the election of Donald Trump, Fox has dramatically increased its usage of us/we to the levels BBC typically uses.
All four stations sharply increase their usage of us/we language in the Covid-19 era.

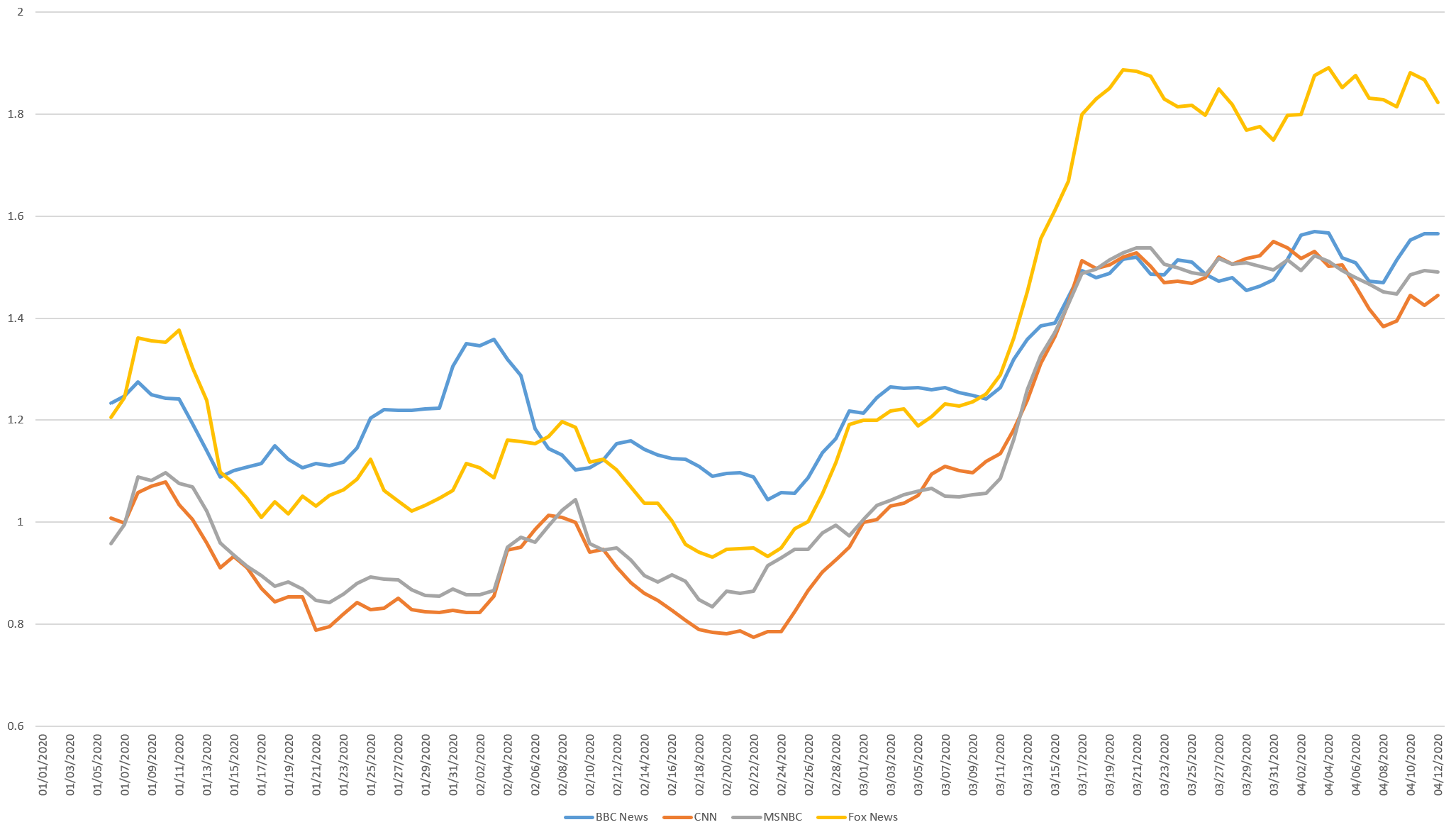
Looking at the daily i/me breakdown (6-day rolling average) for 2020, usage on US stations begins decreasing around March 7th and stabilizes at its new reduced usage by March 15th. BBC shows reduced usage slightly earlier and a rebound since the start of the month.
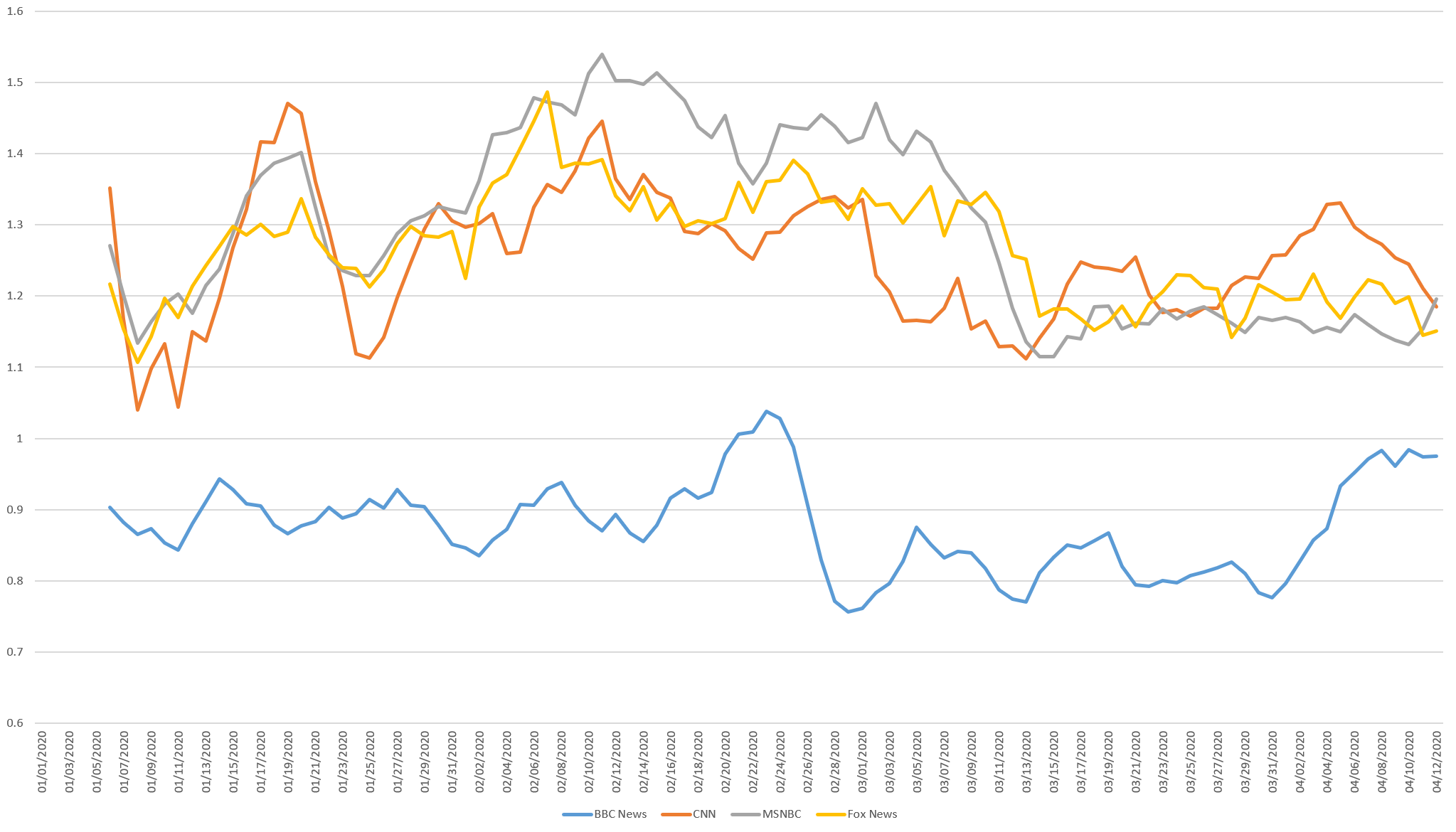
The timeline below shows the same results for us/we. Starting around Feb. 25th all four stations start steadily increasing their use of us/we, with sharp increases beginning on March 11/12 to a new stable peak since March 17th. Here BBC started the year using us/we much higher than all but Fox News, but since March 17th has used it at the same rate as its US brethren, while Fox News stands alone in its much higher usage.
TECHNICAL DETAILS
For those interested in drilling into the graphs above in more detail, the underlying Excel spreadsheet is available for download.
Running the underlying analyses yourself in BigQuery requires just a single SQL query. Here is the monthly analysis:
SELECT DATE, SUM(COUNT) TOTWORDS, SUM(GROUP1COUNT) TOTGROUP1WORDS, SUM(GROUP1COUNT) / SUM(COUNT) * 100 perc_GROUP1side, SUM(GROUP2COUNT) TOTGROUP2WORDS, SUM(GROUP2COUNT) / SUM(COUNT) * 100 perc_GROUP2side FROM ( SELECT SUBSTR(CAST(DATE AS STRING), 0, 6) DATE, WORD, 0 COUNT, COUNT GROUP1COUNT, 0 GROUP2COUNT FROM `gdelt-bq.gdeltv2.iatv_1grams` WHERE STATION='MSNBC' and WORD in ( SELECT * FROM UNNEST (["i", "me"]) AS WORD ) UNION ALL SELECT SUBSTR(CAST(DATE AS STRING), 0, 6) DATE, WORD, 0 COUNT, 0 GROUP1COUNT, COUNT GROUP2COUNT FROM `gdelt-bq.gdeltv2.iatv_1grams` WHERE STATION='MSNBC' and WORD in ( SELECT * FROM UNNEST (["we", "us"]) AS WORD ) UNION ALL SELECT SUBSTR(CAST(DATE AS STRING), 0, 6) DATE, WORD, COUNT, 0 GROUP1COUNT, 0 GROUP2COUNT FROM `gdelt-bq.gdeltv2.iatv_1grams` WHERE STATION='MSNBC' ) group by DATE order by DATE asc
And the daily version:
SELECT DATE, SUM(COUNT) TOTWORDS, SUM(GROUP1COUNT) TOTGROUP1WORDS, SUM(GROUP1COUNT) / SUM(COUNT) * 100 perc_GROUP1side, SUM(GROUP2COUNT) TOTGROUP2WORDS, SUM(GROUP2COUNT) / SUM(COUNT) * 100 perc_GROUP2side FROM ( SELECT SUBSTR(CAST(DATE AS STRING), 0, 8) DATE, WORD, 0 COUNT, COUNT GROUP1COUNT, 0 GROUP2COUNT FROM `gdelt-bq.gdeltv2.iatv_1grams` WHERE STATION='MSNBC' and WORD in ( SELECT * FROM UNNEST (["i", "me"]) AS WORD ) UNION ALL SELECT SUBSTR(CAST(DATE AS STRING), 0, 8) DATE, WORD, 0 COUNT, 0 GROUP1COUNT, COUNT GROUP2COUNT FROM `gdelt-bq.gdeltv2.iatv_1grams` WHERE STATION='MSNBC' and WORD in ( SELECT * FROM UNNEST (["we", "us"]) AS WORD ) UNION ALL SELECT SUBSTR(CAST(DATE AS STRING), 0, 8) DATE, WORD, COUNT, 0 GROUP1COUNT, 0 GROUP2COUNT FROM `gdelt-bq.gdeltv2.iatv_1grams` WHERE STATION='MSNBC' ) where CAST(DATE AS NUMERIC) >=20200101 group by DATE order by DATE asc
We're excited to see what you can do with similar kinds of linguistic analyses!