The massive new 101-billion-token Web Part of Speech dataset annotated by Google's Cloud Natural Language API released yesterday offers unprecedented insights into the evolution and usage of language globally over the past third of a decade.
Given that the entire dataset is available in BigQuery, asking language-scale questions is as simple as a single line of SQL.
How many distinct case-insensitive tokens and lemmas are there in the English portion of the dataset?
SELECT count(distinct LOWER(token)), count(distinct LOWER(lemma)) FROM `gdelt-bq.gdeltv2.web_pos` where lang='en'
The answer is 53,437,014 distinct tokens and 52,906,365 distinct lemma.
How many of those lemma are different from the their token? In other words, how often does lemmatization change the word?
SELECT LOWER(token), LOWER(lemma), count(1) count FROM `gdelt-bq.gdeltv2.web_pos` where lang='en' and token!=lemma group by LOWER(token), LOWER(lemma) order by count desc
In all, 2,007,675 total distinct tokens are different from their lemma. This is a surprisingly large number suggesting that many of these may be misspellings and rare words. What if we limit to just those token-lemma pairs seen in at least 11 pairings (this can be a grammatical context or a 15 minute interval)?
SELECT LOWER(token), LOWER(lemma), count(1) count FROM `gdelt-bq.gdeltv2.web_pos` where lang='en' and token!=lemma group by LOWER(token), LOWER(lemma) having count>10 order by count desc
This reduces the total count to 240,020 distinct tokens with lemmas different from the original token.
What is the part of speech breakdown of the dataset? How many more nouns do we see compared to verbs?
select posTag, sum(count) count FROM `gdelt-bq.gdeltv2.web_pos` where lang='en' group by posTag order by count desc
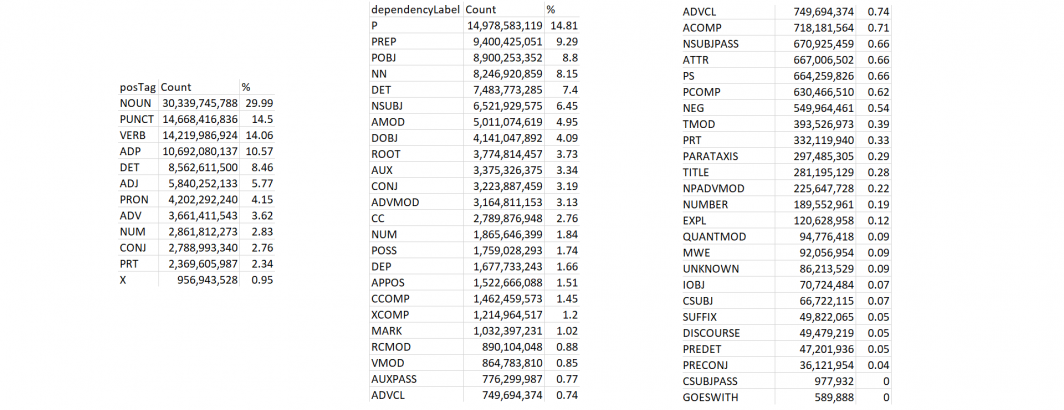
This yields the table below (see the Cloud Natural Language API documentation for definitions):
| posTag | Count | % |
| NOUN | 30,339,745,788 | 29.99 |
| PUNCT | 14,668,416,836 | 14.5 |
| VERB | 14,219,986,924 | 14.06 |
| ADP | 10,692,080,137 | 10.57 |
| DET | 8,562,611,500 | 8.46 |
| ADJ | 5,840,252,133 | 5.77 |
| PRON | 4,202,292,240 | 4.15 |
| ADV | 3,661,411,543 | 3.62 |
| NUM | 2,861,812,273 | 2.83 |
| CONJ | 2,788,993,340 | 2.76 |
| PRT | 2,369,605,987 | 2.34 |
| X | 956,943,528 | 0.95 |
Interestingly, despite its ubiquity, punctuation accounts for just 14.5% of the total token volume, a little more than verbs, while nouns account for almost 30%. The label "X" refers to "Other: foreign words, typos, abbreviations" meaning that 99.05% of words in the dataset have an assigned linguistic role.
What about their dependency roles? Once again, a single SQL query is all that's required.
select dependencyLabel, sum(count) count FROM `gdelt-bq.gdeltv2.web_pos` where lang='en' group by dependencyLabel order by count desc
This yields the table below (see the Cloud Natural Language API documentation for definitions):
| dependencyLabel | Count | % |
| P | 14,978,583,119 | 14.81 |
| PREP | 9,400,425,051 | 9.29 |
| POBJ | 8,900,253,352 | 8.8 |
| NN | 8,246,920,859 | 8.15 |
| DET | 7,483,773,285 | 7.4 |
| NSUBJ | 6,521,929,575 | 6.45 |
| AMOD | 5,011,074,619 | 4.95 |
| DOBJ | 4,141,047,892 | 4.09 |
| ROOT | 3,774,814,457 | 3.73 |
| AUX | 3,375,326,375 | 3.34 |
| CONJ | 3,223,887,459 | 3.19 |
| ADVMOD | 3,164,811,153 | 3.13 |
| CC | 2,789,876,948 | 2.76 |
| NUM | 1,865,646,399 | 1.84 |
| POSS | 1,759,028,293 | 1.74 |
| DEP | 1,677,733,243 | 1.66 |
| APPOS | 1,522,666,088 | 1.51 |
| CCOMP | 1,462,459,573 | 1.45 |
| XCOMP | 1,214,964,517 | 1.2 |
| MARK | 1,032,397,231 | 1.02 |
| RCMOD | 890,104,048 | 0.88 |
| VMOD | 864,783,810 | 0.85 |
| AUXPASS | 776,299,987 | 0.77 |
| ADVCL | 749,694,374 | 0.74 |
| ACOMP | 718,181,564 | 0.71 |
| NSUBJPASS | 670,925,459 | 0.66 |
| ATTR | 667,006,502 | 0.66 |
| PS | 664,259,826 | 0.66 |
| PCOMP | 630,466,510 | 0.62 |
| NEG | 549,964,461 | 0.54 |
| TMOD | 393,526,973 | 0.39 |
| PRT | 332,119,940 | 0.33 |
| PARATAXIS | 297,485,305 | 0.29 |
| TITLE | 281,195,129 | 0.28 |
| NPADVMOD | 225,647,728 | 0.22 |
| NUMBER | 189,552,961 | 0.19 |
| EXPL | 120,628,958 | 0.12 |
| QUANTMOD | 94,776,418 | 0.09 |
| MWE | 92,056,954 | 0.09 |
| UNKNOWN | 86,213,529 | 0.09 |
| IOBJ | 70,724,484 | 0.07 |
| CSUBJ | 66,722,115 | 0.07 |
| SUFFIX | 49,822,065 | 0.05 |
| DISCOURSE | 49,479,219 | 0.05 |
| PREDET | 47,201,936 | 0.05 |
| PRECONJ | 36,121,954 | 0.04 |
| CSUBJPASS | 977,932 | 0 |
| GOESWITH | 589,888 | 0 |
| REPARANDUM | 2,676 | 0 |
| PARTMOD | 26 | 0 |
| VOCATIVE | 10 | 0 |
BigQuery's immense scalability makes it a perfect lens through which to understand the macro-scale patterns of our world through Google's AI offerings like Cloud Natural Language API.