
Historically, evaluating how "visually similar" two videos are has done through measuring the overlap of their color (and occasionally texture) palettes. Two entirely unrelated images that use similar hues and, in more advanced applications, have large blobs of similar textures, will be treated as similar, even if their contents are utterly unrelated.
Sometimes this is the desired behavior, locating imagery with certain hues, especially in certain graphic design applications where the contents of an image may matter less than its color alignment with the rest of a scene.
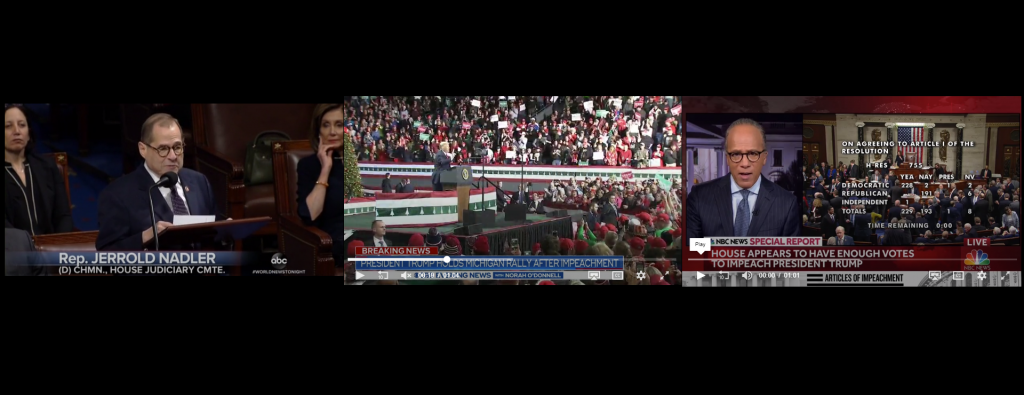
When it comes to content analysis research, "similarity" is measured not in color overlap but rather in terms of what a set of videos depict semantically. Two videos of Donald Trump, one a closeup showing just him and one a wide shot showing a raucous rally, convey very different levels of energy and imagery, even if they are both videos of the same event.
Take the evening of December 18th, 2019. ABC, CBS and NBC all spent the majority of their broadcasts on impeachment, but covered it using very different imagery, presenting very different visual takes on the events of the moment.
Annotating videos using Google's Cloud Video API allows us to understand videos at the semantic level. Instead of merely knowing what colors and textures are in a frame, we know that one video depicts a closeup of a person wearing a suit standing at a podium giving a speech, while the same moment in a different video depicts a large cheering crowd in an auditorium with a speaker in the center wearing a suit and standing behind a podium flanked by American flags and guarded by large numbers of police. Such semantic details make it possible to estimate that two videos might be different angles of the same event and more powerfully, to evaluate the semantic similarity of competing narratives over time and even to pick up errors in the original footage labeling.
We're incredibly excited to see what kinds of new research this massive new Visual Global Entity Graph 2.0 dataset makes possible.