
YOLO (You Only Look Once) is a popular and widely-used open object detection toolkit that is both extremely fast and includes pretrained models for the COCO dataset, allowing out-of-the-box detection of around 80 common objects. What might it look like to apply YOLO's pretrained COCO model to a Russian TV news broadcast via the Visual Explorer's preview images to annotate the objects within?
To see how YOLO works, you can test out its online interactive demo, getting a sense of the kinds of objects it recognizes and what its output looks like. In this case, we are going to deploy it locally via PyTorch on a V100-equipped GCE VM to run at-scale over an entire broadcast. There are a range of pretrained models available of different sizes allowing you to trade off speed versus accuracy. In this case, we use the "XLarge" (YOLOv5x) model to maximize recognition accuracy to examine its best-effort potential on television news.
Installing and using YOLO with its pretrained COCO dataset model is fairly trivial. Using our previously configured quad-core V100 GCE VM, we adapted the YOLO getting started guide to the following workflow.
First, we install YOLO:
pip install -qr https://raw.githubusercontent.com/ultralytics/yolov5/master/requirements.txt
Then we select our sample television news broadcast – in this case a 2.5-hour episode of Russia 1's 60 Minutes from November 22nd and download its preview images:
wget https://storage.googleapis.com/data.gdeltproject.org/gdeltv3/iatv/visualexplorer/RUSSIA1_20221122_083000_60_minut.zip unzip RUSSIA1_20221122_083000_60_minut.zip
Now we create the Python script to run YOLO over the entire archive of JPEG images. Write the following file to "run_yolo.py":
import torch
import os
import sys
#load the model...
model = torch.hub.load('ultralytics/yolov5', 'yolov5x')
#run a directory of images...
directory = 'RUSSIA1_20221122_083000_60_minut'
for filename in os.listdir(directory):
f = os.path.join(directory, filename)
if os.path.isfile(f):
results = model(f)
f = open(f + '.labels', 'w'); print(results.pandas().xyxy[0], file=f); f.close();
results.save(save_dir='./annotimgs', exist_ok=True)
Then, run it (it automatically compiles a list of all images in the directory and runs over each in turn):
rm RUSSIA1_20221122_083000_60_minut/*.labels rm -rf annotimgs time python3 ./run_yolo.py
In a showcase of just how fast YOLO really is, in just 1 minute and 26 seconds it will annotate all 2,263 1280×720 resolution JPEG images. The script above generates two output files for each image. The first is a ".labels" file that it writes into the "RUSSIA1_20221122_083000_60_minut" directory, one per image, that contains all of the detected objects for that image.
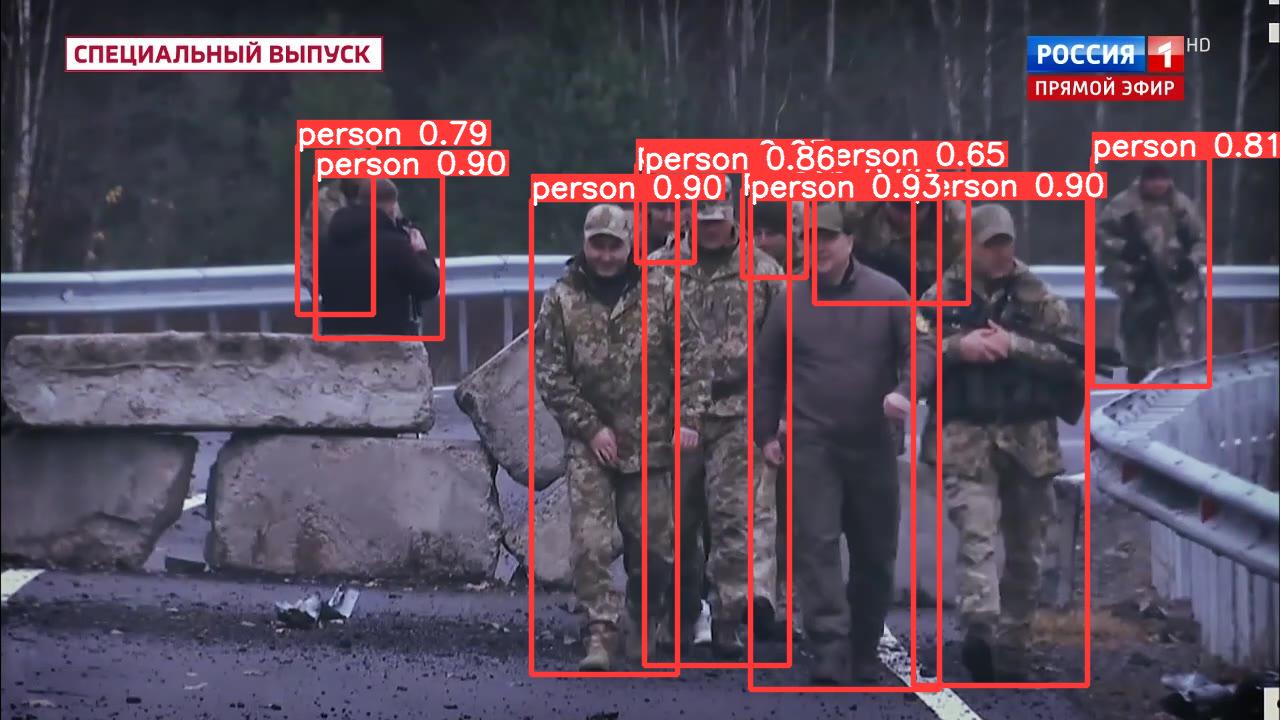
For example, here is the result for Image 40:
xmin ymin xmax ymax confidence class name 0 750.592896 198.272049 939.004395 689.970642 0.929380 0 person 1 315.821930 175.479156 442.040070 338.385834 0.903817 0 person 2 913.203369 197.499496 1087.062500 685.871582 0.901423 0 person 3 531.713989 199.771072 677.992920 674.334717 0.898821 0 person 4 644.288269 170.378128 789.142395 665.808350 0.860875 0 person 5 1092.211914 157.527222 1209.782959 386.266602 0.812353 0 person 6 297.701782 145.674606 373.318604 314.888916 0.785615 0 person 7 814.781494 166.868179 968.300049 303.343445 0.648810 0 person 8 636.518066 164.872223 694.937866 262.893677 0.632154 0 person 9 742.844604 189.568970 806.783325 277.085022 0.601667 0 person
The script also creates a subdirectory called "annotimgs" where it writes an annotated version of the image with all of the detected objects drawn with bounding boxes, the object name and detection confidence. This is the annotated version of Image 40:
You can download the complete set of detected labels and annotated images for all 2,264 images:
To make it easier to see how YOLO+COCO annotated this broadcast, we converted the annotated image sequence into a movie:
time cat $(find ./annotimgs/ -maxdepth 1 -name "*.jpg" | sort -V) | ffmpeg -framerate 2 -i - -vcodec libx264 -vf "pad=ceil(iw/2)*2:ceil(ih/2)*2" -y RUSSIA1_20221122_083000_60_minut.yolov5x.mp4
You can see the final results below:
The largest limitation is that the COCO dataset contains just 80 labels, meaning that while it is able to annotate common objects like people, ties, cups of coffee, etc, it has poor representation of wartime imagery and low overlap with a lot of the visual narratives prevalent on Russian television news. Nevertheless, this demonstration showcases the power of applying tools like YOLO to television news using the Visual Explorer preview images and that even a relatively limited object dataset like COCO can still yield quite interesting findings. Most importantly, YOLO is relatively easy to train to identify new kinds of objects, meaning custom models tailored specifically for television news could be readily trained and applied using this same pipeline!