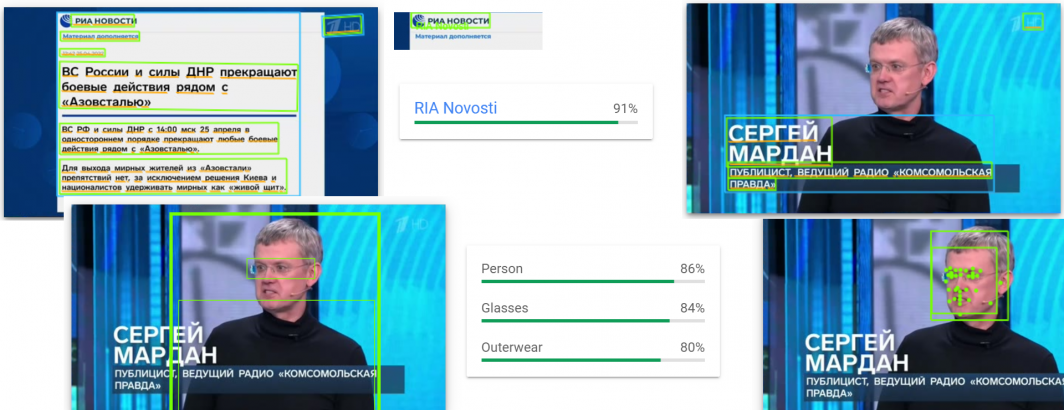
Today we are excited to unveil Visual Explorer Lenses: a powerful new metaphor for engaging with and understanding video that uses the Visual Explorer as a canvas onto which AI-powered and traditional metadata, analytic and interface layers can be applied to "see" video, especially television news, in entirely new ways. In this way, the Visual Explorer will increasingly become the central interface and repository for all of our experiments and datasets around understanding video.
Some lenses, such as our automated transcription and translation of select channels, have been integrated into the native Visual Explorer interface. Others, like our Visual Global Entity Graph 2.0, OCR experiments and massive new face detection dataset are downloadable annotation layers, designed to be analyzed offline. As native in-browser capabilities continue to rapidly evolve, ranging from OCR and reverse image search and translation and the Web Speech API to deployable custom models like Tensorflow.js and MediaPipe to the wave of forthcoming and emergent capabilities, we are also exploring how best to integrate those as additional lenses through which to see video archives through the Visual Explorer, allowing for rapid at-scale iteration. We are also rapidly scaling up our experiments with Large Language Models (LLMs) as we explore how best to both leverage their multimodal capabilities and mitigate their unique challenges.
Our ultimate goal with Visual Explorer Lenses is to use the Visual Explorer as a foundational canvas onto which any kind of precomputed and realtime metadata or analysis can be layered to provide different ways of understanding the underlying video. At their most basic, Lenses could be spoken word and OCR transcripts, evolving through visual annotations and ultimately through guided and automated AI-assisted summarization and analysis. Ultimately, we envision Lenses as a centralization of everything we are doing with video – all of those myriad annotations, datasets, analytic tools and experiments becoming available through the Visual Explorer interface. Accessing a television news broadcast today automatically displays available transcripts and translations for that broadcast. In the future, everything across the GDELT ecosystem and perhaps from external ecosystems will be available in the Visual Explorer interface as a sort of singular centralized universal interface for video.
While many Lenses will offer self-contained introspective examinations of the underlying video, some will focus on connecting video to the external world, from knowledgebase and external dataset connectivity to web-scale multimodal analysis, to help enrich and contextualize television news coverage.
Stay tuned for an exciting announcement coming this week in collaboration with the Internet Archive's TV News Archive and the multi-party Media-Data Research Consortium that provides a first glimpse at the idea of connecting television news to the digital world as a way of contextualizing coverage to create a more informed electorate in the support of democracy itself.