One of the most fascinating lessons we've learned from working with journalists and scholars using the Internet Archive's TV News Archive is how powerful OCR search of television news' onscreen text has become. At the same time, expanding our current OCR'ing of four channels to the entire 327-channel Archive using SOTA video OCR would cost more than $69.6M. Sampling the entire archive at 1fps and OCRing using SOTA still imagery OCR would cost between $17M and $41.7M, depending on bulk usage discounts. Even using the Visual Explorer's 1/4fps images would cost between $4.2 and $10.5M depending on bulk discounts. Unfortunately, no current open source OCR tool we've tested, such as Tesseract, yields even mildly usable results on television news. Could we leverage our work the past two weeks on image montages to vastly reduce these OCR costs? The answer is yes: reducing the cost of processing a single video from $1.50 to just $0.0015 and 2.2s by using some creative optimizations and accepting a slightly reduced accuracy level.
The cost estimates above assume that we OCR each video frame as a single independent image. At the same time, Google's Cloud Vision API pricing is per image, charging the same for a 500×500 pixel image as for an 8500×8500 pixel image. The maximum native image resolution supported for OCR is 75M pixels, which works out to 8,660×8,660 pixels. Instead of submitting our frames as isolated images, what if we batched them into single-image montages and OCR'd them as a single unit? To optimize things even further, what if we apply change detection to dramatically reduce the total frame count by skipping over contiguous image sequences that don't change?
Let's start with this CNN broadcast. Other than commercial breaks, the majority of all 1/4fps Visual Explorer thumbnail frames contain chyron text. Let's apply ffmpeg's built-in scene detection filter to only return frames that represent at least a 20% change from the previous frame. We'll then use ImageMagick's mogrify to resize all of the selected frames to 200×200 pixels and then montage to generate a single contact sheet for them all. The resulting montage is just 2200×3059 pixels and 2.7MB – meaning we can submit the entire broadcast as a single request to the Vision API:
time ffmpeg -i ./CNNW_20240903_230000_Erin_Burnett_OutFront-%06d.jpg -vf "select='gt(scene,0.2)',showinfo" -vsync vfr ./OUTPUT/OUT-%06d.jpg time mogrify -resize 200 ./OUTPUT/* time montage ./OUTPUT/OUT-%06d.jpg[1-500] -tile 10x -geometry +10+10 -background black ./CNNW_20240903_230000_Erin_Burnett_OutFront.change02.montage.jpg;
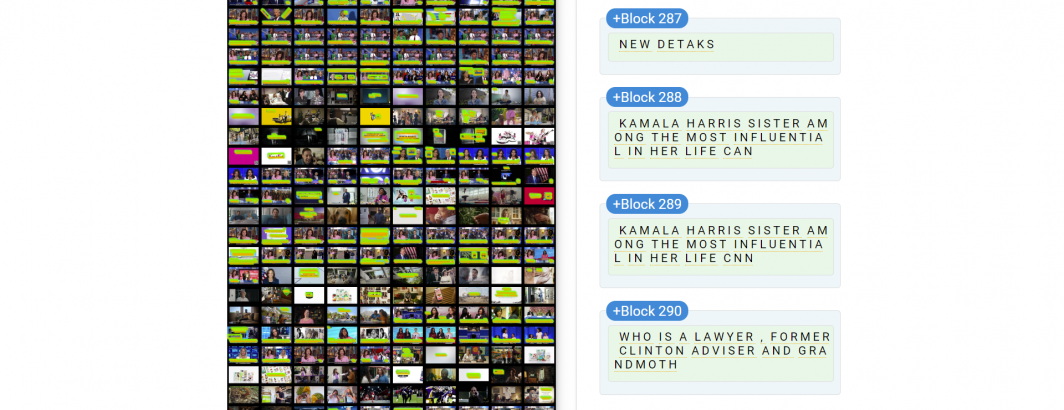
This reduces the total number of frames from 917 down to just 225: a 4x reduction in the total images we'll have to OCR. You can see the final image sequence below and compare it with the full broadcast. Note how in some cases the visuals of the frame are large identical, but the textual chyron has changed enough for the filter to pick it up:

Let's run this montage through Cloud Vision API's online demo site and we can see that it is successfully recognizing most of the text from the frames, even if the lower resolution is introducing significant OCR error: this means that even at this vastly reduced resolution, we are largely able to OCR the broadcast and get reasonable accuracy results, even if they are far worse than what the API is actually capable of.
Already, just from these results, we've reduced our cost from $1.50 for OCR'ing the 1/4fps Visual Explorer frames of the broadcast as individual frames, down to just $0.0015 for the entire broadcast. The OCR results are good enough to support most OCR use cases, though they miss the small subtitle chyron text and obviously have degraded overall accuracy. The entire broadcast took just 2.2seconds to process using this single montage.
Let's OCR it using Cloud Vision:
time gsutil -m -q cp "./IMAGE.jpg" gs://[YOURBUCKET]/
curl -s -H "Content-Type: application/json; charset=utf-8" -H "x-goog-user-project:[YOURPROJECTID]" -H "Authorization: Bearer $(gcloud auth print-access-token )" https://vision.googleapis.com/v1/images:annotate -d '{ "requests": [ { "image": { "source": { "gcsImageUri": "gs://[YOURBUCKET]/ IMAGE.jpg" } }, "features": [ {"type":"TEXT_DETECTION"} ] } ] }' | jq -r .responses[].fullTextAnnotation.text
This yields the following annotations. Note that to split the resulting text by frame we would use the X/Y offsets of each recognized word to associate it with its respective frame:
While there is often text outside of the chyron and some channels emphasize text throughout the frame (such as Chinese news coverage and business channels), for channels like CNN, just OCR'ing the chyron text might be a reasonable start that would allow journalists and scholars to answer many of their key questions.
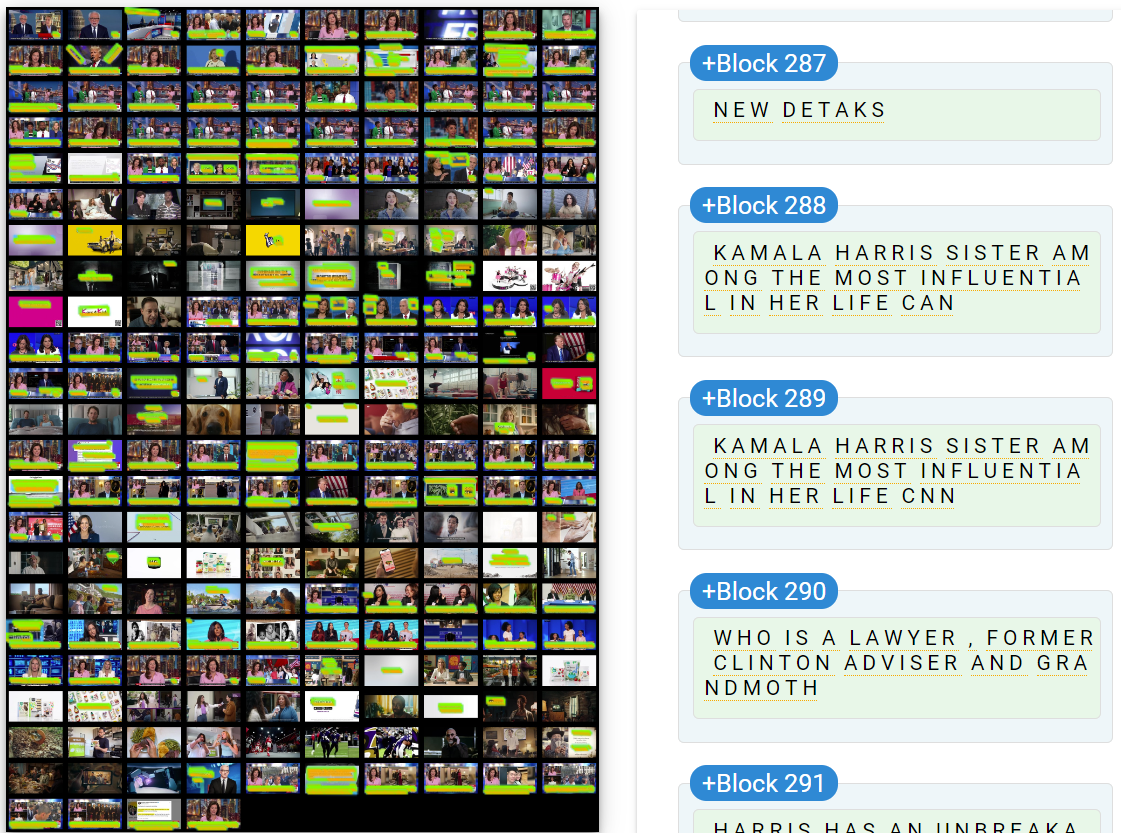
Let's modify our code above to crop each image to the bottom 30% of the image and perform scene detection and frame output on that. This slightly reduces the number of output frames from 225 to 222:
time ffmpeg -i ./CNNW_20240903_230000_Erin_Burnett_OutFront-%06d.jpg -vf "crop=in_w:in_h*0.3:0:in_h*0.7,select='gt(scene,0.2)" -vsync vfr ./OUTPUT/OUT-%06d.jpg time mogrify -resize 200 ./OUTPUT/* time montage ./OUTPUT/OUT-%06d.jpg[1-500] -tile 10x -geometry +10+10 -background black ./CNNW_20240903_230000_Erin_Burnett_OutFront.change02.montage.jpg;
This converts each frame to:


Resizing these into 200×200 pixel thumbnails and forming them into a single montage yields:

This yields the following Cloud Vision OCR annotations: