How accurate is the open-source tesseract OCR package on television news and could it be used to recover a reasonable portion of the onscreen text of each second of a broadcast with serviceable accuracy despite the pathological conditions of wildly different font faces, styles and colors, background colors and textures and moving text?
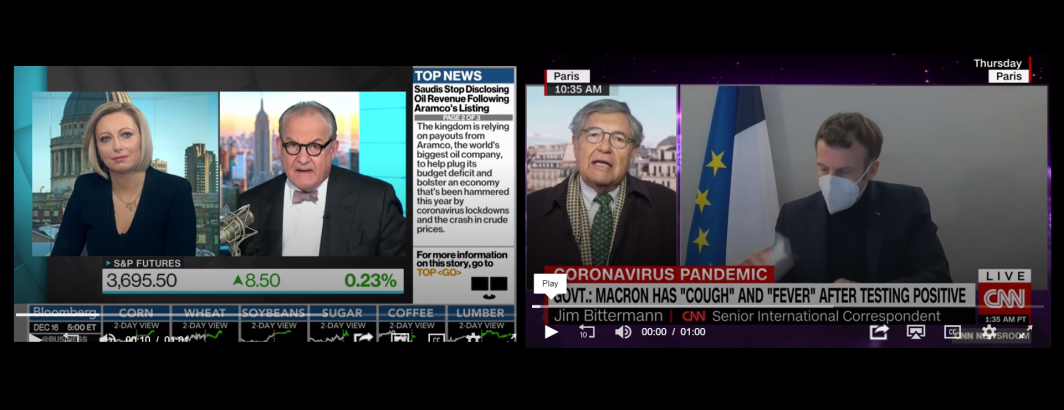
To test the idea of using tesseract to OCR television news, we examined two broadcasts. One represented the text-heavy realm of business news using the Dec. 16, 2020 5AM PST episode of Bloomberg Surveillance , which features heavy use of onscreen text, with text layouts on the right, bottom, lower third and sometimes scrolling text, combined with chyrons, tickers and sometimes whole-screen textual infographics. This represents a worst-case scenario for text recovery. The other broadcast is a run-of-the-mill cable news broadcast, the Dec. 18, 2020 1AM PST episode of CNN Newsroom Live, in which text is largely constrained to the chyron, period ticker and occasional full-screen infographic or list, but still poses a test for OCR with the various kinds of contrast between text and background, from white-on-red to black-on-gradient to white-on-black to white-on-purple and a number of other combinations over the course of the broadcast.
For both broadcasts we used tesseract 4.1.1 and unsurprisingly found that its LSTM model yielded the best results, but at a considerable cost of CPU power.
We first converted each MPEG4 into a sequence of PNG images, one per second of airtime. From experimentation we found that PNGs yielded the highest accuracy. Writing directly to SSD disk this took around 47s on a 64-core system, though ffmpeg is not able to use all cores in this pipeline.
time cat VIDEO.mp4 | ffmpeg -f mp4 -i pipe: -vf "fps=1" -start_number 0 "./FRAMES/F-%6d.png"
For CNN, we found that running tesseract directly on the output frames yielded the best results. Here all 64 cores were used and we found that running 30 frames at once yielded full CPU utilization without oversubscribing them. Running more than 30 parallel jobs yielded dramatic slowdowns on this particular system. The OCR process took around 1m43s to complete.
time find ./FRAMES/*.png | parallel -j 30 --eta 'tesseract {} {.}'
To see the results for any second of airtime, replace the 6-digit zero-padded second of airtime in the URLs below with any number from 000000 to 003661:
- http://data.gdeltproject.org/blog/2020-tesseract-tvnews-ocr/CNNW_20201218_090000_CNN_Newsroom_Live/F-XXXXXX.png
- http://data.gdeltproject.org/blog/2020-tesseract-tvnews-ocr/CNNW_20201218_090000_CNN_Newsroom_Live/F-XXXXXX.txt
You can browse to any portion of the broadcast using the Internet Archive's interface and use the given starttime offset as the airtime second in the URLs above.
For example, at start time 420 Mitch McConnel is seen onscreen with a chyron listing his name and title. You can view this as:
- http://data.gdeltproject.org/blog/2020-tesseract-tvnews-ocr/CNNW_20201218_090000_CNN_Newsroom_Live/F-000420.png
- http://data.gdeltproject.org/blog/2020-tesseract-tvnews-ocr/CNNW_20201218_090000_CNN_Newsroom_Live/F-000420.txt

The OCR misses the white-on-red "US Stimulus Package" text, but correctly captures the chyron, though with some extraneous text on the end of each line.
CONGRESSIONAL LEADERS STRUGGLE TO PASS AID DEAL ï¬__ Mitch McConnell | U.S. Senate Majority Leader T
What about this text-heavy frame?

Here the OCR captures the chyron but misses the chyron from the embedded Fox News clip.
SOME STATES WILL GET SMALLER VACCINE SHIPMENTS “ Brian Morgenstern = White House Deputy Communications DireCtor = s.0s amer
What about this bulleted list?

Other than the spurious characters at the start of each line and the "$900" becoming "5900", the OCR is pretty accurate.
= Price tag could be close to 5900 billion = Money for vaccine distribution and schools u Jobless benefits of $300 per week = $330 billion for small business loans ® $600 stimulus checks per individual under a certain income threshold LIVE
What about a more complicated example taken from the text-saturated world of business television news using a Bloomberg broadcast? Here we ran the broadcast under both the legacy tesseract 3 and tesseract 4.1.1. neural LSTM to compare their respective accuracies. This broadcast took much longer than the CNN broadcast, totaling 14m55s on the same 64 core system.
Here we found that using the extracted frames as-is yielded much poorer accuracy than resizing them up to 150% of their original size using a Gaussian filter to blur them slightly, which seems to dramatically improve tesseract's accuracy. Thus, the final workflow is:
time find ./FRAMES/*.png | parallel --eta 'convert -filter Gaussian -resize 150% {} {.}.jumbo.png'
time find ./FRAMES/*.jumbo.png | parallel -j 30 'tesseract {} {.}'
You can see the difference between the original and resized images below.
Here is the original frame:

And here is the resized frame:

You can see how the Gaussian filter has made the text far more blurrier, which appears to improve tesseract's accuracy.
Here is the output of the tesseract 4.1.1 LSTM engine on the resized frame above:
Oil Revermf_ Following — Saudi Arabia has stopped disclosing projectedrevenue from oil following the listing of Aramco, as. doing so could give clues about the state energy giant's dividend plans. loomberg I I CORN WHEAT OVBEAN SUGAR COFFEE LUMBER 427 | _@Business 1+3.00 071% +5. 00 083% LR 25 044% X 08 56% s 95 076% ~1300 1 60%
The bold title atop the right hand text is largely missing (though its middle line survives) and two of the words were merged together, but there is a reasonable recovery of the text.
Here the 3.0 legacy non-neural model on the resized frame actually yields better results:
TOP NEWS Saudis Stop Disclosing Oil Revenue Following Aramco's Listing —:.'_r’ iI-Ii— Saudi Arabia has stopped disclosing projected revenue from oil following the listing of Aramco, as doing so could give clues about the state energy giant's dividend plans. ' $&P FUTURES 3,695.50 A 8.50 0.23% CORN 427.75 —+3.00 0.71% “”11: 604.75 1194.00 14.29 125.60 +6.00 0.83% +5.25 0.44% +0.08 0.56% +0.95 0.76% +13.001.60°o
And here is the 3.0 legacy non-neural model on the original non-resized frame, showing noticeably less accurate results:
Oil Revers ‘Following — Saudi Arabia has stopped disclosing projected revenue from oil following the listing of Aramco, as doing so could give clues about the state energy giant's dividend plans. loomberg Ph Le | @BUSINESS — | oe ee ose es aa a 427. | @BUSINESS —1+3.00 ean rh ee ion coe oe re cath a on c's EG en eS 0 ton
Here's another example frame, with text on the right, an infographic in the center, a chyron and statistics in the footer:

Tesseract 3 legacy on the original frame offers this transcription:
Stralwisls Ave Watching for From me Fed's Decision INTRADAV Snaieglsls are walllng 10 see 11 me central bank Imks the Mscl EMERGING mKEIsmnsx 1,260.04 A 9.83 0.79% 'mureo'asset 7 D1Ilchases1olneasltres M501 EM wmsucv oi employment and milauon 01 even takes ache" to alter the pace av composmon at band buym lo! Insunce by mt g debt Dulchases |ol<m§ev 1,717.52 A 3.51 0.20% 1,123.49 THE ASCE OF THE PACIFIC RIM Bloomberg 2 YR 5 YR 10 YR 30 YR 0 3M LIBOR Dams 5:15Er 0 37 0 2 67 80 6 0 288 _ausmzss —+D. 60b5 51.7% 2.83% +1.57!) 1.73% #2.†30% v1.26b- 1.59% +0.00% 4.33% ma1unnes1o suppon the economy,
Tesseract 3 legacy on the resized frame yieldsthis:
TOP NEWS What Market Strategists Are Watching for From the INTRADAY Fed's Decision —.L' 1 x- .s — Str01egistsar0' h 4, , ‘ wantlnsgo 854's: kt fh 1,260.04 A 9.83 0.79% I .131" .. . e . purchases to measures . " 01 enjploymenland 1,717.52 A 3.51 0.20% lgfli‘s'ig‘ï¬: 1V: glter 2 thepacesr 1b d com 05: Ion 1,123.49 buyigg. for inStanzg i bytilting debt purchases to longer maturitiesto support the economy. 1 THE ASCENT OF THE PACIFIC RIM Bloomberg _—___m 0.12 0.37 0.92 1 67 80.16 0.2288 +0.60bo 5.17% +1.03b 2.83% +1.57b 1.73% +2.14b 1.30% +1.be 1.59% +0.0095 4.33%
In contrast, tesseract 4.1.1 LSTM yields a cleaner transcription, though still filled with errors:
What Market Strategists Are Watching for From the Fed's Decision E— Strategists are waiting to see if the central bank links the LT [MSCI EMERGING MARKETS INDEX] 1,260.04 A 9.83 0.79% futwreofasset purchases to measures [MSCI EM CURRENCY| of employmentand inflation, or even takesactionto alter the pace or composition of bond buying, forinstance by tilting debt purchases tolonger 1,717.52 A 3.51 0.20% 1,123.49 THE ASCENT OF THE PACIFIC RIM Bloomberg Z YR 5YR 10 YR 30 YR [ 3M LIBOR DEC16 516 ET 0.37 [X7] 67 80.16 0.2288 [ @BUsiNESs —+0.60bp 5. ‘I7% 2.83%1+1.57bp 1.73% |+2.14 30% |+1.26bp 1.59% | +0.0095 4.33% maturities to support the economy.
It is clear that even with tesseract the 4.1.1. LSTM model, the image preprocessing pipeline has an outsized role on the resulting accuracy. It is also clear that if there are large differences in the font, size, color and style of the onscreen text blocks, tesseract appears to do well on larger more common text arrangements such as standard black-on-white typeface, while bolded text and more unusual color combinations cause issues. This suggests one possible source of considerable improvement would be to block the image into individual text regions in which within each bounding box the text is uniform and apply separate preprocessing filters to each region individually and use tesseract to process each separately. That would likely make it possible to work around many of these challenges.
In the end, with further experimentation to tune the preprocessing pipeline, tesseract could yield a reasonable transcription of at least a portion of the onscreen text, especially the chyrons on traditional cable news programming like CNN and the larger text blocks on text-heavy business channels.