With yesterday's massive new dataset containing the URLs and context snippets of 6.3 million English language online news articles about climate change 2015-2020, how might we use this dataset to support Q&A tasks, especially in the context of a voice-interacting digital assistant?
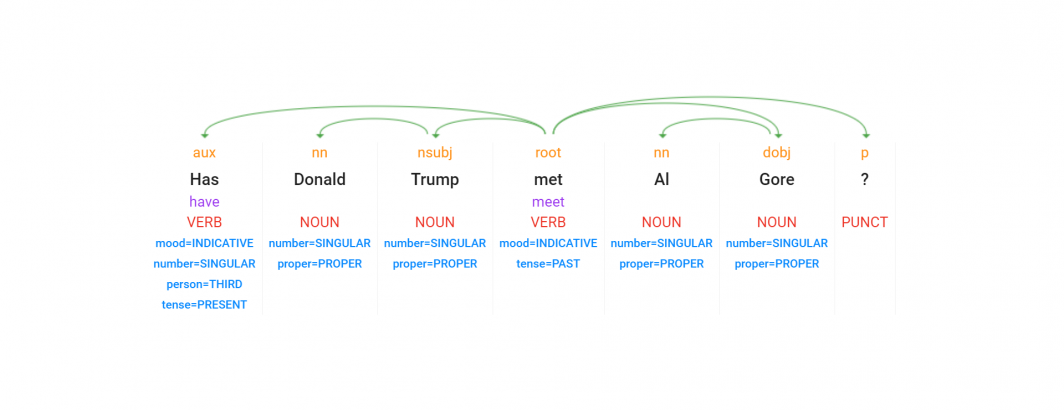
Imagine a user that wanted to know if Donald Trump and Al Gore had ever met. They might ask their smart assistant "Has Donald Trump met Al Gore?" Using Google's Cloud Natural Language API, that query is annotated as:
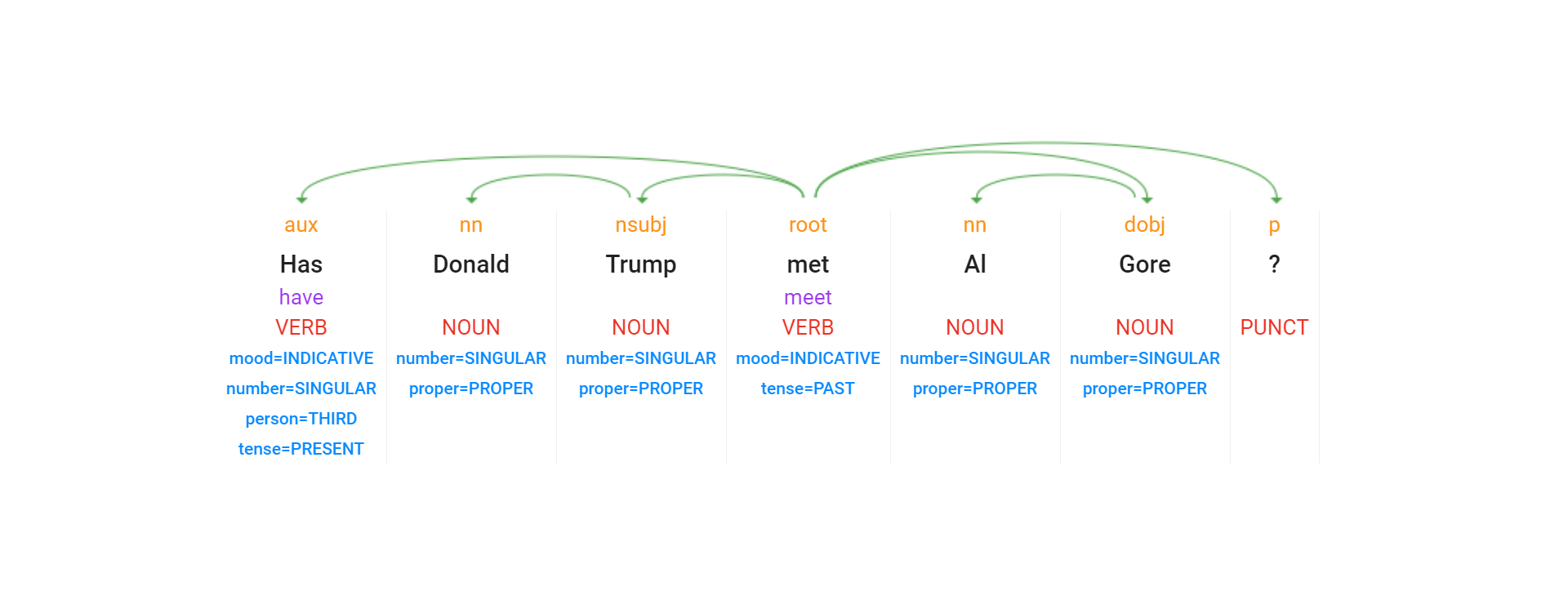
The API correctly identifies "Donald Trump" and "Al Gore" as the two entities in the sentence and connects them to their Wikipedia entries, which provide a range of alternative names commonly used to refer to them. In the case of Donald Trump, Wikipedia's redirect tables offer a wide range of commonly used referents, including "Trump." Using our Web NGrams dataset, we can see that the most commonly used of those name variants is simply "Trump."
The dependency parse above tells us that the verb at the center of the user's query is "met" with lemma of "meet", indicating that we should include both in our query.
Using "Al Gore", "Trump", "met" and "meet" as our search terms, we search the English Online News Climate Change Narratives dataset for all snippets containing all four words together in the same snippet, which places them both within 200 characters of a mention of climate change. In essence our query becomes:
select * from [CLIMATECHANGENARRATIVESDATASET] where Context like '%Trump%' and Context like '%Al Gore%' and (LOWER(Context) like '%met%' OR LOWER(Context) like '%meet%')
This query yields 1,791 results, including entries like "…U.S. President-elect Donald Trump on Monday met with former Vice President Al Gore, an environmental activist who has devoted years to fighting climate change, Gore told reporters. 'I had a lengthy and very productive session with the president-elect,' said Gore, who met earlier with Trump's daughter…"
In short, we can take a voice query from a user, annotate it with the Natural Language API, extract the entities and central verb, use them as search terms against the climate change dataset and return the most relevant match. Despite its immense simplicity, such a system would actually likely be able to answer a large fraction of casual and advanced user queries.