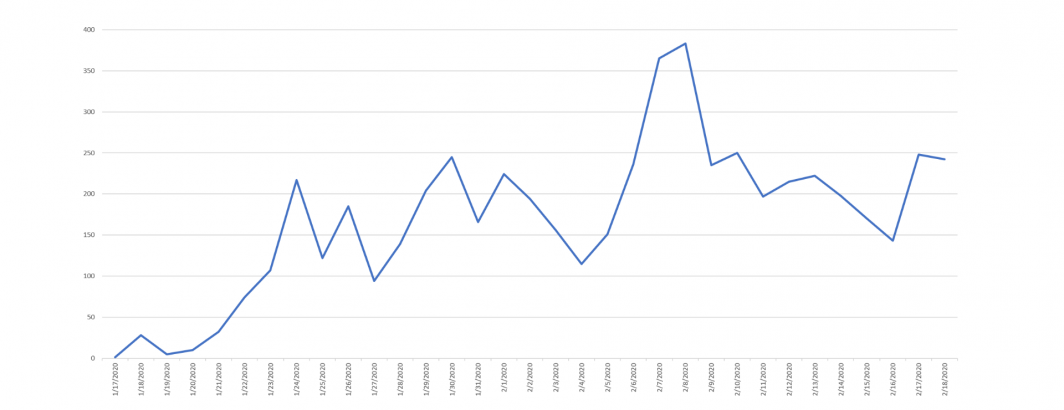
What has the Coronavirus outbreak looked like through the eyes of television news and how well has Google's Natural Language API picked up on mentions of it?
The timeline below shows a simple keyword search for "(coronavirus OR "corona virus")" using the Television Explorer:
A brief glimmer in 2012, followed by a larger burst in 2013 and then silence until the tremendous surge in mentions over the last two months.
Keyword searches of transcripts are useful, but they require apriori knowledge that a particular phrase is of interest and a compilation of the various words and phrases used to reference that entity.
In contrast, the Television News Global Entity Graph 2.0 relies on Google's Natural Language API to automatically identify entities in the textual transcripts of television news broadcasts and, most importantly, to normalize them, linking all of the various name variants to a common entity.
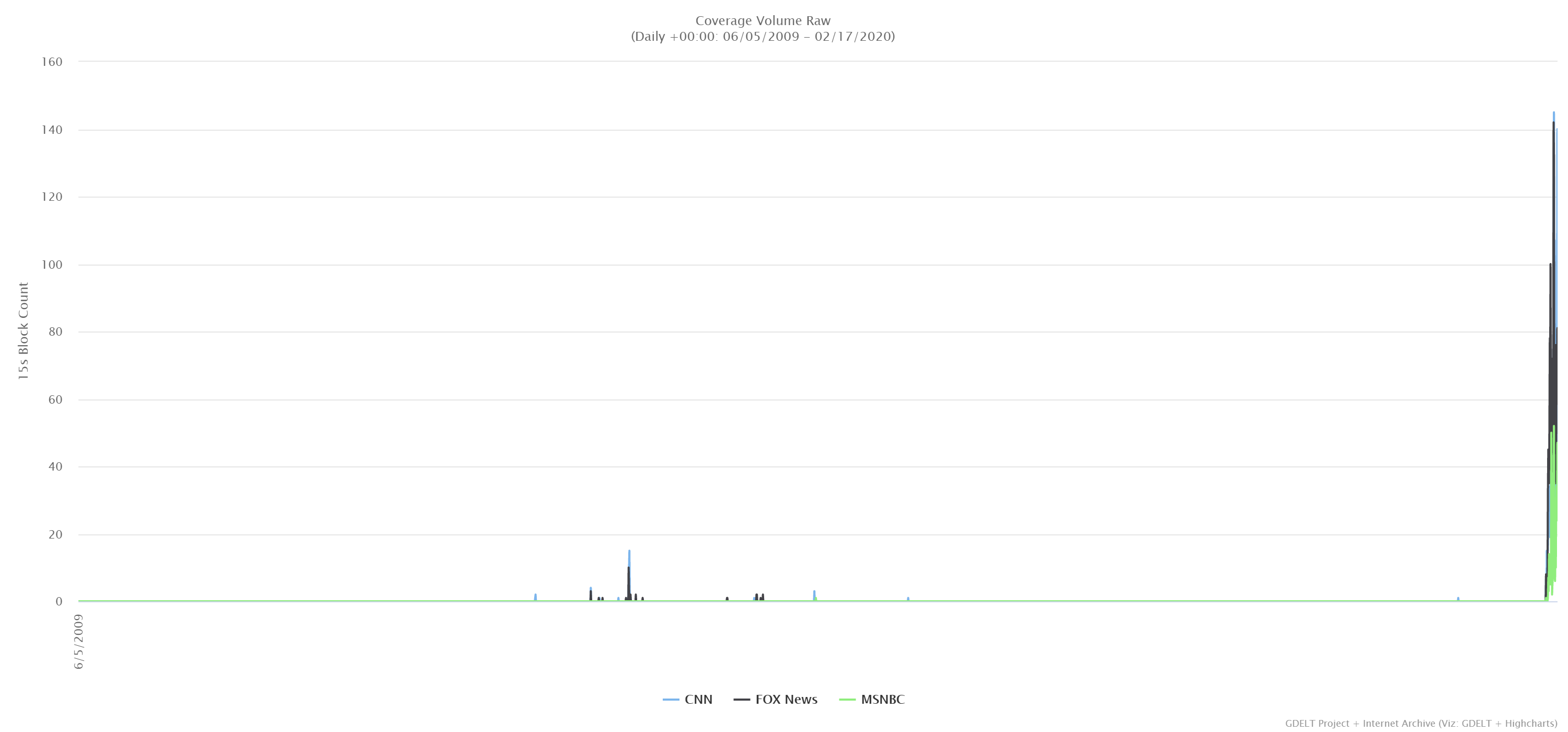
It turns out Google actually has an entity for "Coronavirus": MID code "/m/01cpyy". The timeline below shows its presence in the Television News Global Entity Graph 2.0 over the past decade:
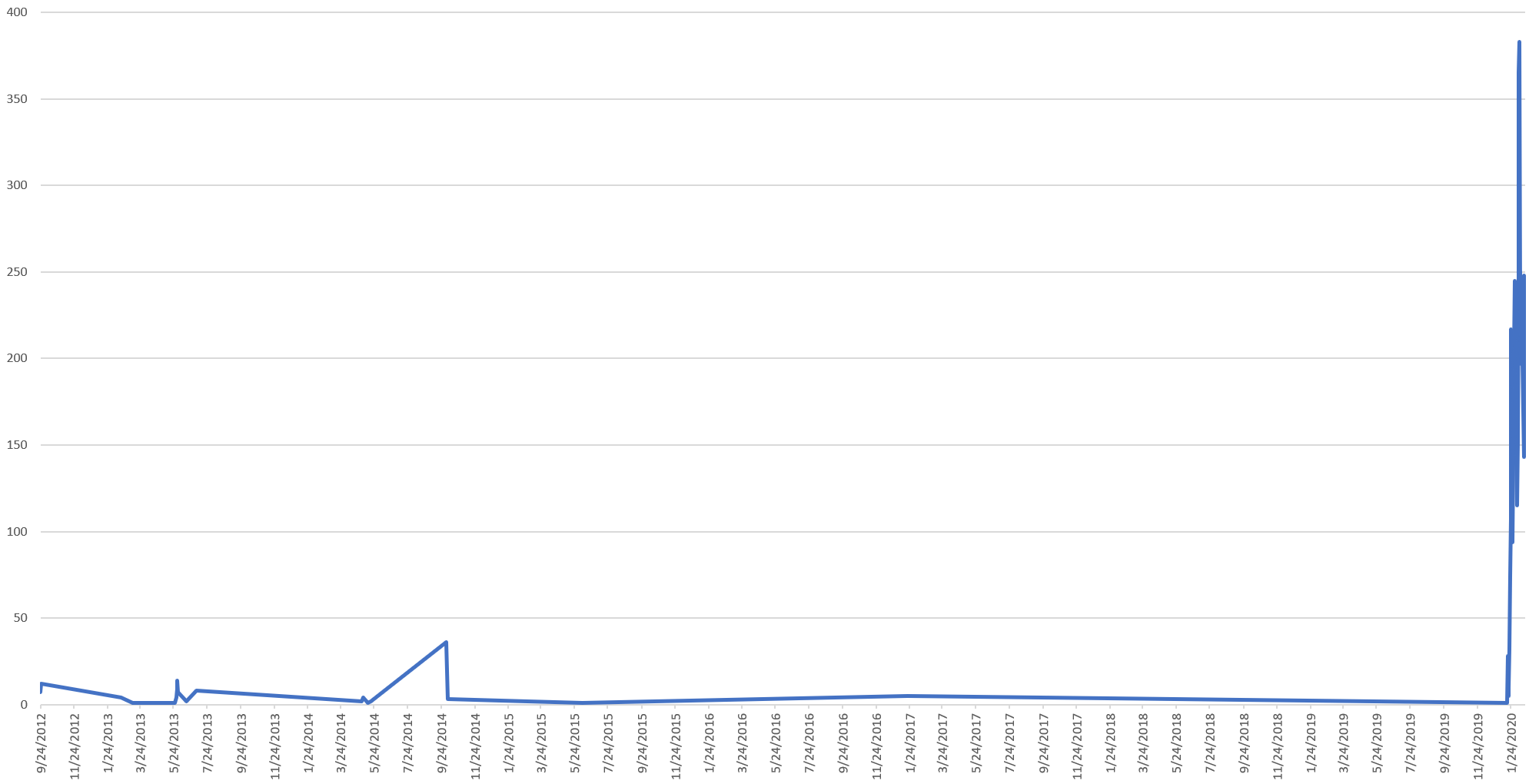
Here the 2012-2013 bursts visible in the TV Explorer can also be seen. The earliest mention is at 4:48PM PDT on September 24, 2012 on CNN's Erin Burnett Out Front about a Qatari man who contracted a mystery "corona virus."
The most recent mention prior to the current outbreak was on January 19, 2017. Since that date, there were no mentions identified by the Natural Language API until January 17, 2020, with mentions accelerating through the month as seen below:
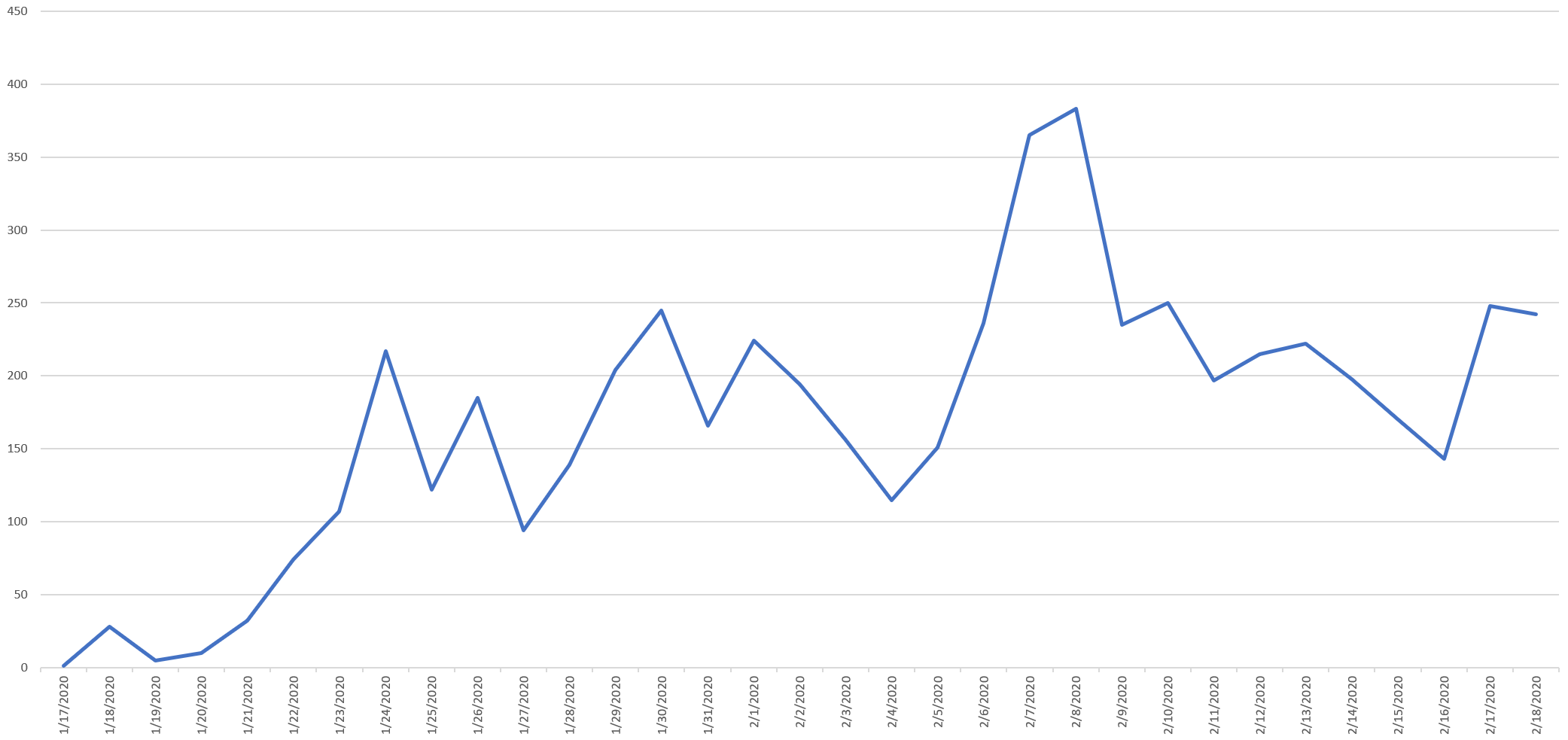
In this particular case, Google already had an entry in its master entity database for Coronaviruses due to their being a broad class of respiratory diseases, so there was no delay in a new entry needing to be learned.
TECHNICAL DETAILS
Constructing the TVGEG graphs above required just a single SQL query in BigQuery:
SELECT DATE(date) day, count(1) count FROM `gdelt-bq.gdeltv2.gegv2_iatv`, unnest(entities) entity where entity.mid='/m/01cpyy' group by day order by day asc