Embeddings have emerged in recent years as the go-to approach for semantic search. With the rise of Large Language Models (LLM's) and their limited inputs and attention, embedding-based semantic search has been repurposed as external memory for LLM's, increasingly placing them squarely in the center of an AI-driven future. One of the greatest challenges today is that there is no single universal embedding model that fits all languages, domains and use cases. Instead, a wealth of models exist, many fine-tuned for specific applications, making it difficult to decide which model to adopt for a given application. Indeed, a quick look at the MTEB Leaderboard illustrates the incredible fragmentation of the model landscape, with hard tradeoffs based on the specific use case. While embedding models can be swapped out at any time, doing so requires regenerating the database of resulting embeddings from scratch – an expensive proposition. GDELT itself, due to the vast and growing number of languages it supports (150+ currently and soon to be 400+), adopted a translation + embedding workflow in which we translate all content into English and then embed using the Universal Sentence Encoder (USE) English model, which found to produce the best massively-multilingual results at the time. Yet, for many use cases, the number of languages being considered is far smaller – often just a few core languages. The rise of embeddings as external memory for LLM's has also lead to the growing availability of foundational embedding models created by the LLM maintainers themselves and optimized for their use. What does it look like to run a few sample passages through the Universal Sentence Encoder Family, LaBSE & Vertex AI Embeddings for Text?
The Universal Sentence Encoder (USE) family is a widely-used collection of models for textual embedding. Here we will explore the English-only USEv4, the larger English-only USEv5-Large, the 16-language USEv3-Multilingual and the larger 16-language USEv3-Multilingual-Large models. The multilingual models support 16 languages (Arabic, Chinese-simplified, Chinese-traditional, English, French, German, Italian, Japanese, Korean, Dutch, Polish, Portuguese, Spanish, Thai, Turkish, Russian). We'll also compare with the 100-language LaBSEv2 model that is optimized for translation-pair scoring. Finally, we'll test with the Vertex AI Embeddings for Text API.
To make it easy to follow along and test on your own content, we'll build a quick Collab notebook. Just copy-paste the code below into a notebook and execute.
First we'll load the models themselves:
!pip3 install tensorflow_text>=2.0.0rc0
import tensorflow_hub as hub
import numpy as np
import tensorflow_text
embed_use = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
embed_use_large = hub.load("https://tfhub.dev/google/universal-sentence-encoder-large/5")
embed_use_multilingual = hub.load("https://tfhub.dev/google/universal-sentence-encoder-multilingual/3")
embed_use_multilingual_large = hub.load("https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3")
Then we'll create a set of sentences to use for comparison: a mixture of English, Chinese, Arabic and Burmese and some machine translations in a range of similarities:
sentences = [
"A major Texas hospital system has reported its first case of the lambda COVID-19 variant, as the state reels from the rampant delta variant Houston Methodist Hospital, which operates eight hospitals in its network, said the first lambda case was confirmed Monday Houston Methodist had a little over 100 COVID-19 patients across the hospital system last week. That number rose to 185 Monday, with a majority of those infected being unvaccinated, according to a statement released by the hospital Monday",
"得克萨斯州一家主要医院系统报告了第一例 lambda COVID-19 变种病例,因为该州从猖獗的三角洲变种中解脱出来 休斯顿卫理公会医院在其网络中运营着八家医院,并表示周一确认了第一例 lambda 病例 休斯顿卫理公会 上周整个医院系统有 100 多名 COVID-19 患者。 根据医院周一发布的一份声明,该数字周一上升至 185 人,其中大多数感染者未接种疫苗",
"أبلغ أحد أنظمة المستشفيات الكبرى في تكساس عن أول حالة إصابة بفيروس لامدا COVID-19 ، حيث قالت الولاية من مستشفى هيوستن ميثوديست المتغير المنتشر في دلتا ، والتي تشغل ثمانية مستشفيات في شبكتها ، إن أول حالة لامدا تأكدت يوم الاثنين من هيوستن ميثوديست. ما يزيد قليلاً عن 100 مريض COVID-19 عبر نظام المستشفى الأسبوع الماضي. وارتفع هذا العدد إلى 185 يوم الاثنين ، مع عدم تلقيح غالبية المصابين ، بحسب بيان صادر عن المستشفى يوم الاثنين.",
"ကြီးမားသောတက္ကဆက်ဆေးရုံစနစ်တစ်ခုသည် ၎င်း၏ကွန်ရက်ရှိဆေးရုံရှစ်ခုကိုလည်ပတ်နေသည့် lambda ရောဂါကို တနင်္လာနေ့တွင် Houston Methodist ဆေးရုံမှပြန်လည်စုစည်းထားသောကြောင့် ပြည်နယ်သည် lambda COVID-19 မျိုးကွဲ၏ပထမဆုံးဖြစ်ရပ်ကို အစီရင်ခံတင်ပြလိုက်ပါသည်။ ပြီးခဲ့သည့်အပတ်က ဆေးရုံစနစ်တွင် COVID-19 လူနာ ၁၀၀ ကျော် အနည်းငယ်ရှိသည်။ အဆိုပါ အရေအတွက်သည် တနင်္လာနေ့တွင် ၁၈၅ ဦးအထိ မြင့်တက်လာခဲ့ပြီး ရောဂါပိုးကူးစက်ခံရသူ အများစုမှာ ကာကွယ်ဆေးမထိုးရသေးကြောင်း တနင်္လာနေ့က ဆေးရုံမှ ထုတ်ပြန်သော ထုတ်ပြန်ချက်တစ်ခုအရ သိရသည်။",
"【#他撑伞蹲了很久让女孩知道世界很美好#】近日,湖南长沙,一女子因感情问题一时想不开,独自坐在楼顶哭泣。消防员赶赴,温柔蹲在女孩身旁安抚情绪,夜色沉沉,天空下起小雨,救援人员为其撑伞暖心守护,经过近一小时的劝导,将女孩平安带下15楼天台。ps:答应我们,好好爱自己,世间还有很多美好~#女孩感情受挫消防员撑伞守护# 中国消防的微博视频",
"【#He Held an Umbrella and Squatted for a Long Time to Let the Girl Know that the World is Beautiful#】Recently, in Changsha, Hunan province, a woman, overwhelmed by relationship problems, sat alone on the rooftop crying. Firefighters rushed to the scene, gently squatting beside the girl to comfort her. The night was dark, and drizzling rain started to fall from the sky. The rescue team held an umbrella to protect and warm her heart. After nearly an hour of persuasion, they safely brought the girl down from the 15th-floor rooftop. PS: Promise us, love yourself well, there is still much beauty in the world ~ #Girl's Emotions Distressed, Firefighters Holding an Umbrella and Guarding# Video footage from the Chinese Fire Brigade's Weibo account.",
"一堂童画课,用色彩传递温暖!送困境儿童 美育盒子 ,送自闭症儿童艺术疗愈课程。让我们与@延参法师 一堂童画课公益发起人,在这个充满爱与温暖的日子里,一起感受艺术的魅力,用童心绘制美好,为公益事业贡献一份力量!@一堂童画课 北京市行远公益基金会的微博视频",
"A children's painting class, conveying warmth through colors! Sending Art Education Boxes to children in difficult situations, and providing art therapy courses for children with autism. Let us, together with Master Yan Can, the initiator of the public welfare project A Children's Painting Class, experience the charm of art on this loving and warm day. Let's use childlike hearts to create beauty and contribute to the cause of public welfare! @A Children's Painting Class, a video on the official Weibo account of Beijing Xingyuan Public Welfare Foundation."
"Art can be a very powerful tool for children's therapy.",
"艺术可以成为儿童治疗的一个非常强大的工具。"
]
And finally we'll run them through the models:
#prevent NP from line-wrapping when printing the arrays below
np.set_printoptions(linewidth=500)
#USE
print("\nUSE")
%time results = embed_use(sentences)
simmatrix = np.inner(results, results)
print(simmatrix)
#USE-LARGE
print("\nUSE-LARGE")
%time results = embed_use_large(sentences)
simmatrix = np.inner(results, results)
print(simmatrix)
#USE-MULTILINGUAL
print("\nUSE-MULTILINGUAL")
%time results = embed_use_multilingual(sentences)
simmatrix = np.inner(results, results)
print(simmatrix)
#USE-MULTILINGUAL-LARGE
print("\nUSE-MULTILINGUAL-LARGE")
%time results = embed_use_multilingual_large(sentences)
simmatrix = np.inner(results, results)
print(simmatrix)
This results in the following output. For each model the total execution time is shown to compare model speed, from USE's 6ms to USE-Multilingual-Large at 1.2s that runs 200x slower. For each model there is a matrix that displays the pairwise similarity of each sentence. Each row represents one of the sentences above (in order) and the columns compare it to all of the other sentences. Thus, the first row represents the sentence "A major Texas hospital system…" and the first column compares it to itself ("9.99999881e-01" is effectively 0.9999999 showing maximal similarity) while the second column of the first row compares it to the second sentence ("得克萨斯州一家主要医院…") which is its machine translation into Chinese, the third column of the first row compares it to its Arabic machine translation and so on.
USE CPU times: user 6.31 ms, sys: 0 ns, total: 6.31 ms Wall time: 6.08 ms [[ 9.99999881e-01 1.35287523e-01 6.16897754e-02 2.82917291e-01 1.64749384e-01 -2.30342168e-02 6.09422699e-02 1.92656927e-02] [ 1.35287523e-01 1.00000012e+00 1.50608987e-01 5.92873752e-01 8.14152062e-02 9.18879211e-02 -4.55325469e-04 9.51746404e-02] [ 6.16897754e-02 1.50608987e-01 9.99999821e-01 3.74320239e-01 2.38140687e-01 1.20395079e-01 9.63330120e-02 -6.63705077e-03] [ 2.82917291e-01 5.92873752e-01 3.74320239e-01 9.99999881e-01 1.24105565e-01 1.08034983e-01 3.15705389e-02 7.55521134e-02] [ 1.64749384e-01 8.14152062e-02 2.38140687e-01 1.24105565e-01 9.99999762e-01 -5.42871058e-02 3.02406967e-01 6.13755211e-02] [-2.30342168e-02 9.18879211e-02 1.20395079e-01 1.08034983e-01 -5.42871058e-02 1.00000000e+00 7.06045181e-02 -5.75770903e-03] [ 6.09422699e-02 -4.55325469e-04 9.63330120e-02 3.15705389e-02 3.02406967e-01 7.06045181e-02 9.99999940e-01 3.12433131e-02] [ 1.92656927e-02 9.51746404e-02 -6.63705077e-03 7.55521134e-02 6.13755211e-02 -5.75770903e-03 3.12433131e-02 1.00000000e+00]] USE-LARGE CPU times: user 511 ms, sys: 13.9 ms, total: 525 ms Wall time: 304 ms [[ 0.9999999 0.2801901 0.02825017 0.4704876 0.05203238 -0.02493936 0.12363833 -0.08127209] [ 0.2801901 1.0000001 0.26236042 0.48804784 0.02746031 0.3363984 -0.03582555 0.05889798] [ 0.02825017 0.26236042 0.9999999 0.2664111 0.12225244 0.23801576 0.01799368 0.07812253] [ 0.4704876 0.48804784 0.2664111 1.0000002 0.14625126 0.33351815 0.10264659 0.07224818] [ 0.05203238 0.02746031 0.12225244 0.14625126 0.99999994 0.13055062 0.36411548 -0.04815773] [-0.02493936 0.3363984 0.23801576 0.33351815 0.13055062 0.99999976 0.06037879 0.1603686 ] [ 0.12363833 -0.03582555 0.01799368 0.10264659 0.36411548 0.06037879 1. -0.06609872] [-0.08127209 0.05889798 0.07812253 0.07224818 -0.04815773 0.1603686 -0.06609872 1.0000001 ]] USE-MULTILINGUAL CPU times: user 136 ms, sys: 1.73 ms, total: 138 ms Wall time: 77.9 ms [[ 1. 0.7992382 0.857008 0.23258644 0.11595267 -0.01415727 0.04852476 -0.02587 ] [ 0.7992382 1.0000001 0.70707417 0.23821741 0.09333451 0.05413792 0.05633176 -0.04936313] [ 0.857008 0.70707417 1. 0.22679895 0.1434581 -0.0095628 0.05424863 -0.04476827] [ 0.23258644 0.23821741 0.22679895 0.9999999 0.64873683 0.27872685 0.25528187 -0.01069948] [ 0.11595267 0.09333451 0.1434581 0.64873683 1. 0.2562064 0.29808474 -0.03728896] [-0.01415727 0.05413792 -0.0095628 0.27872685 0.2562064 1.0000001 0.75445706 0.3546956 ] [ 0.04852476 0.05633176 0.05424863 0.25528187 0.29808474 0.75445706 0.99999994 0.5032176 ] [-0.02587 -0.04936313 -0.04476827 -0.01069948 -0.03728896 0.3546956 0.5032176 1.0000002 ]] USE-MULTILINGUAL-LARGE CPU times: user 1.15 s, sys: 50.8 ms, total: 1.2 s Wall time: 663 ms [[0.9999999 0.81812036 0.70894873 0.3291394 0.08517189 0.04017881 0.06708076 0.02093088] [0.81812036 1. 0.7161075 0.30517748 0.07584821 0.05492438 0.04840576 0.04943869] [0.70894873 0.7161075 1. 0.17536551 0.07657022 0.06227682 0.05057137 0.01748174] [0.3291394 0.30517748 0.17536551 1. 0.4941615 0.1720014 0.23234278 0.06847077] [0.08517189 0.07584821 0.07657022 0.4941615 1.0000001 0.19092317 0.36365843 0.05748826] [0.04017881 0.05492438 0.06227682 0.1720014 0.19092317 0.9999999 0.72703046 0.39201975] [0.06708076 0.04840576 0.05057137 0.23234278 0.36365843 0.72703046 1. 0.40681934] [0.02093088 0.04943869 0.01748174 0.06847077 0.05748826 0.39201975 0.40681934 0.9999999 ]]
Readily clear is that the two English-only USE models, while generating embeddings for the other languages, create embeddings that are not semantically meaningful. In other words, they don't generate an error when given non-English text, but the resulting embeddings do not accurately reflect the meaning of the text and thus aren't useful for similarity scoring. This is exactly as expected. In contrast, the two multilingual models perform reasonably well at cross-language similarity scoring when the language is one of their supported languages. However, when given a language outside their list of supported languages (Burmese in this case), the results are not semantically meaningful – once again, as expected.
Interestingly, in this particular set of example sentences, the base multilingual model actually performs nearly as well as the large multilingual, but is 8.7x faster.
However, we can also see that the multilingual model to improperly score some sentences as being equally similar, with "A children's painting class, conveying warmth…" scored equally with its Chinese translation ("一堂童画课,用色彩传递温暖!送困境儿童 美…") and an unrelated English passage ("【#He Held an Umbrella and Squatted for a Long…"), while it is scored highly similar to a related English statement ("Art can be a very powerful tool for children's…"). In other words, the English statement and its exact Chinese machine translation are scored as fairly dissimilar, while a topically-similar text in the same language is scored as highly-similar. This reflects the fact that cross-language scoring is still typically siloed by language, despite the model's multilingual focus.
What about the 100-language LaBSEv2 model via its PyTorch port? This model is optimized for bilingual sentence pair scoring, so should skew towards scoring our translation pairs more highly than generalized semantic similarity scoring, but has the benefit of supporting a much larger range of languages.
First we'll install the necessary models:
!pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('sentence-transformers/LaBSE')
We'll create our sentence list:
sentences = [
"A major Texas hospital system has reported its first case of the lambda COVID-19 variant, as the state reels from the rampant delta variant Houston Methodist Hospital, which operates eight hospitals in its network, said the first lambda case was confirmed Monday Houston Methodist had a little over 100 COVID-19 patients across the hospital system last week. That number rose to 185 Monday, with a majority of those infected being unvaccinated, according to a statement released by the hospital Monday",
"得克萨斯州一家主要医院系统报告了第一例 lambda COVID-19 变种病例,因为该州从猖獗的三角洲变种中解脱出来 休斯顿卫理公会医院在其网络中运营着八家医院,并表示周一确认了第一例 lambda 病例 休斯顿卫理公会 上周整个医院系统有 100 多名 COVID-19 患者。 根据医院周一发布的一份声明,该数字周一上升至 185 人,其中大多数感染者未接种疫苗",
"أبلغ أحد أنظمة المستشفيات الكبرى في تكساس عن أول حالة إصابة بفيروس لامدا COVID-19 ، حيث قالت الولاية من مستشفى هيوستن ميثوديست المتغير المنتشر في دلتا ، والتي تشغل ثمانية مستشفيات في شبكتها ، إن أول حالة لامدا تأكدت يوم الاثنين من هيوستن ميثوديست. ما يزيد قليلاً عن 100 مريض COVID-19 عبر نظام المستشفى الأسبوع الماضي. وارتفع هذا العدد إلى 185 يوم الاثنين ، مع عدم تلقيح غالبية المصابين ، بحسب بيان صادر عن المستشفى يوم الاثنين.",
"ကြီးမားသောတက္ကဆက်ဆေးရုံစနစ်တစ်ခုသည် ၎င်း၏ကွန်ရက်ရှိဆေးရုံရှစ်ခုကိုလည်ပတ်နေသည့် lambda ရောဂါကို တနင်္လာနေ့တွင် Houston Methodist ဆေးရုံမှပြန်လည်စုစည်းထားသောကြောင့် ပြည်နယ်သည် lambda COVID-19 မျိုးကွဲ၏ပထမဆုံးဖြစ်ရပ်ကို အစီရင်ခံတင်ပြလိုက်ပါသည်။ ပြီးခဲ့သည့်အပတ်က ဆေးရုံစနစ်တွင် COVID-19 လူနာ ၁၀၀ ကျော် အနည်းငယ်ရှိသည်။ အဆိုပါ အရေအတွက်သည် တနင်္လာနေ့တွင် ၁၈၅ ဦးအထိ မြင့်တက်လာခဲ့ပြီး ရောဂါပိုးကူးစက်ခံရသူ အများစုမှာ ကာကွယ်ဆေးမထိုးရသေးကြောင်း တနင်္လာနေ့က ဆေးရုံမှ ထုတ်ပြန်သော ထုတ်ပြန်ချက်တစ်ခုအရ သိရသည်။",
"【#他撑伞蹲了很久让女孩知道世界很美好#】近日,湖南长沙,一女子因感情问题一时想不开,独自坐在楼顶哭泣。消防员赶赴,温柔蹲在女孩身旁安抚情绪,夜色沉沉,天空下起小雨,救援人员为其撑伞暖心守护,经过近一小时的劝导,将女孩平安带下15楼天台。ps:答应我们,好好爱自己,世间还有很多美好~#女孩感情受挫消防员撑伞守护# 中国消防的微博视频",
"【#He Held an Umbrella and Squatted for a Long Time to Let the Girl Know that the World is Beautiful#】Recently, in Changsha, Hunan province, a woman, overwhelmed by relationship problems, sat alone on the rooftop crying. Firefighters rushed to the scene, gently squatting beside the girl to comfort her. The night was dark, and drizzling rain started to fall from the sky. The rescue team held an umbrella to protect and warm her heart. After nearly an hour of persuasion, they safely brought the girl down from the 15th-floor rooftop. PS: Promise us, love yourself well, there is still much beauty in the world ~ #Girl's Emotions Distressed, Firefighters Holding an Umbrella and Guarding# Video footage from the Chinese Fire Brigade's Weibo account.",
"一堂童画课,用色彩传递温暖!送困境儿童 美育盒子 ,送自闭症儿童艺术疗愈课程。让我们与@延参法师 一堂童画课公益发起人,在这个充满爱与温暖的日子里,一起感受艺术的魅力,用童心绘制美好,为公益事业贡献一份力量!@一堂童画课 北京市行远公益基金会的微博视频",
"A children's painting class, conveying warmth through colors! Sending Art Education Boxes to children in difficult situations, and providing art therapy courses for children with autism. Let us, together with Master Yan Can, the initiator of the public welfare project A Children's Painting Class, experience the charm of art on this loving and warm day. Let's use childlike hearts to create beauty and contribute to the cause of public welfare! @A Children's Painting Class, a video on the official Weibo account of Beijing Xingyuan Public Welfare Foundation."
"Art can be a very powerful tool for children's therapy.",
"艺术可以成为儿童治疗的一个非常强大的工具。",
]
And we'll run the model:
#compute the embeddings %time embeds = model.encode(sentences) #prevent NP from line-wrapping when printing the arrays below np.set_printoptions(linewidth=500) #compare them simmatrix = np.inner(embeds, embeds) print(simmatrix)
We can see that this is the most expensive model of all, totaling 6.4 seconds of inference time just for these 10 short sentences:
CPU times: user 6.4 s, sys: 0 ns, total: 6.4 s Wall time: 6.53 s [[1. 0.9405081 0.9275924 0.8841646 0.246873 0.2763008 0.17410922 0.2444013 0.12730592] [0.9405081 1.0000001 0.9076841 0.85752714 0.26318815 0.29913837 0.20596941 0.27494198 0.11301407] [0.9275924 0.9076841 0.9999999 0.9011461 0.23458755 0.27642542 0.17776132 0.26297644 0.19807708] [0.8841646 0.85752714 0.9011461 0.9999999 0.2509857 0.29914016 0.1656245 0.28355375 0.26415676] [0.246873 0.26318815 0.23458755 0.2509857 1. 0.9058601 0.4357208 0.48990172 0.14693527] [0.2763008 0.29913837 0.27642542 0.29914016 0.9058601 1.0000001 0.41394848 0.5543987 0.18645877] [0.17410922 0.20596941 0.17776132 0.1656245 0.4357208 0.41394848 1.0000004 0.8389604 0.30014998] [0.2444013 0.27494198 0.26297644 0.28355375 0.48990172 0.5543987 0.8389604 1.0000001 0.437561 ] [0.12730592 0.11301407 0.19807708 0.26415676 0.14693527 0.18645877 0.30014998 0.437561 1. ]]
As promised, however, Burmese is now supported. However, we can also see that, as with the USE family, it tends to improperly score some sentences as being highly similar, with "A children's painting class, conveying warmth…" scored equally with its Chinese translation ("一堂童画课,用色彩传递温暖!送困境儿童 美…") and an unrelated English passage ("【#He Held an Umbrella and Squatted for a Long…").
Finally, what about Google's new Vertex AI Embeddings for Text API? This is a hosted API wrapper around the "textembedding-gecko@001" foundational model. While the Vertex AI PaLM API family currently supports only English, let's test how gecko-001 specifically performs on our sentences.
You can explore the Vertex Embeddings API trivially via CURL (you'll have to have enabled the API in your GCP project and change the "[YOURPROJECTID]" below). Here we pipe the results through JQ to extract just the embedding itself:
apt-get -y install jq
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d '{ "instances": [ { "content": "Some sample text to embed"} ] }' \
"https://us-central1-aiplatform.googleapis.com/v1/projects/[YOURPROJECTID]/locations/us-central1/publishers/google/models/textembedding-gecko:predict" | jq .predictions[0].embeddings.values
Let's test this in a Colab notebook in the same fashion we've done for the other models. Since this is a hosted API on GCP, we'll set things up a bit differently. The Vertex Embeddings API has its own Python implementation library that makes it straightforward to incorporate into any Python script, but to make our demo here easier to reimplement in any language or shell script for experimentation, we'll simply wrap around the RESTful API using CURL. To enable "gcloud auth print-access-token" in our Colab notebook, we'll use Colab's authentication API. When you run this cell, you'll see the GCP authentication popup window asking you to authorize the Colab notebook to access your GCP credentials. Once again, you'll need to have already enabled Vertex API for your GCP project.
from google.colab import auth auth.authenticate_user() import numpy as np import json
And load our sentences:
sentences = [
"A major Texas hospital system has reported its first case of the lambda COVID-19 variant, as the state reels from the rampant delta variant Houston Methodist Hospital, which operates eight hospitals in its network, said the first lambda case was confirmed Monday Houston Methodist had a little over 100 COVID-19 patients across the hospital system last week. That number rose to 185 Monday, with a majority of those infected being unvaccinated, according to a statement released by the hospital Monday",
"得克萨斯州一家主要医院系统报告了第一例 lambda COVID-19 变种病例,因为该州从猖獗的三角洲变种中解脱出来 休斯顿卫理公会医院在其网络中运营着八家医院,并表示周一确认了第一例 lambda 病例 休斯顿卫理公会 上周整个医院系统有 100 多名 COVID-19 患者。 根据医院周一发布的一份声明,该数字周一上升至 185 人,其中大多数感染者未接种疫苗",
"أبلغ أحد أنظمة المستشفيات الكبرى في تكساس عن أول حالة إصابة بفيروس لامدا COVID-19 ، حيث قالت الولاية من مستشفى هيوستن ميثوديست المتغير المنتشر في دلتا ، والتي تشغل ثمانية مستشفيات في شبكتها ، إن أول حالة لامدا تأكدت يوم الاثنين من هيوستن ميثوديست. ما يزيد قليلاً عن 100 مريض COVID-19 عبر نظام المستشفى الأسبوع الماضي. وارتفع هذا العدد إلى 185 يوم الاثنين ، مع عدم تلقيح غالبية المصابين ، بحسب بيان صادر عن المستشفى يوم الاثنين.",
"ကြီးမားသောတက္ကဆက်ဆေးရုံစနစ်တစ်ခုသည် ၎င်း၏ကွန်ရက်ရှိဆေးရုံရှစ်ခုကိုလည်ပတ်နေသည့် lambda ရောဂါကို တနင်္လာနေ့တွင် Houston Methodist ဆေးရုံမှပြန်လည်စုစည်းထားသောကြောင့် ပြည်နယ်သည် lambda COVID-19 မျိုးကွဲ၏ပထမဆုံးဖြစ်ရပ်ကို အစီရင်ခံတင်ပြလိုက်ပါသည်။ ပြီးခဲ့သည့်အပတ်က ဆေးရုံစနစ်တွင် COVID-19 လူနာ ၁၀၀ ကျော် အနည်းငယ်ရှိသည်။ အဆိုပါ အရေအတွက်သည် တနင်္လာနေ့တွင် ၁၈၅ ဦးအထိ မြင့်တက်လာခဲ့ပြီး ရောဂါပိုးကူးစက်ခံရသူ အများစုမှာ ကာကွယ်ဆေးမထိုးရသေးကြောင်း တနင်္လာနေ့က ဆေးရုံမှ ထုတ်ပြန်သော ထုတ်ပြန်ချက်တစ်ခုအရ သိရသည်။",
"【#他撑伞蹲了很久让女孩知道世界很美好#】近日,湖南长沙,一女子因感情问题一时想不开,独自坐在楼顶哭泣。消防员赶赴,温柔蹲在女孩身旁安抚情绪,夜色沉沉,天空下起小雨,救援人员为其撑伞暖心守护,经过近一小时的劝导,将女孩平安带下15楼天台。ps:答应我们,好好爱自己,世间还有很多美好~#女孩感情受挫消防员撑伞守护# 中国消防的微博视频",
"【#He Held an Umbrella and Squatted for a Long Time to Let the Girl Know that the World is Beautiful#】Recently, in Changsha, Hunan province, a woman, overwhelmed by relationship problems, sat alone on the rooftop crying. Firefighters rushed to the scene, gently squatting beside the girl to comfort her. The night was dark, and drizzling rain started to fall from the sky. The rescue team held an umbrella to protect and warm her heart. After nearly an hour of persuasion, they safely brought the girl down from the 15th-floor rooftop. PS: Promise us, love yourself well, there is still much beauty in the world ~ #Girl's Emotions Distressed, Firefighters Holding an Umbrella and Guarding# Video footage from the Chinese Fire Brigade's Weibo account.",
"一堂童画课,用色彩传递温暖!送困境儿童 美育盒子 ,送自闭症儿童艺术疗愈课程。让我们与@延参法师 一堂童画课公益发起人,在这个充满爱与温暖的日子里,一起感受艺术的魅力,用童心绘制美好,为公益事业贡献一份力量!@一堂童画课 北京市行远公益基金会的微博视频",
"A children's painting class, conveying warmth through colors! Sending Art Education Boxes to children in difficult situations, and providing art therapy courses for children with autism. Let us, together with Master Yan Can, the initiator of the public welfare project A Children's Painting Class, experience the charm of art on this loving and warm day. Let's use childlike hearts to create beauty and contribute to the cause of public welfare! @A Children's Painting Class, a video on the official Weibo account of Beijing Xingyuan Public Welfare Foundation."
"Art can be a very powerful tool for children's therapy.",
"艺术可以成为儿童治疗的一个非常强大的工具。",
]
Then we'll loop over the sentences, submitting each to the API via CURL, then reading the results in and comparing them as before:
#compute the embeddings
embeds = []
for i in range(len(sentences)):
!rm cmd.json
!rm results.json
print("Embedding: ", sentences[i])
data = {"instances": [ {"content": sentences[i]} ]}
with open("cmd.json", "w") as file: json.dump(data, file)
cmd = 'curl -s -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json; charset=utf-8" -d @cmd.json "https://us-central1-aiplatform.googleapis.com/v1/projects/[YOURPROJECTID]/locations/us-central1/publishers/google/models/textembedding-gecko:predict" > results.json'
!{cmd}
with open('results.json', 'r') as f: data = json.load(f)
print(data)
embeds.append(np.array(data['predictions'][0]['embeddings']['values']))
#prevent NP from line-wrapping when printing the arrays below
np.set_printoptions(linewidth=500)
#compare them
simmatrix = np.inner(embeds, embeds)
print(simmatrix)
The final results:
array([[0.99999639, 0.75403089, 0.70781558, 0.84557946, 0.56751408, 0.5815553 , 0.51876257, 0.56680003, 0.5870215 ],
[0.75403089, 0.99999719, 0.88302315, 0.80451682, 0.66224435, 0.57870722, 0.61908054, 0.58978685, 0.62672988],
[0.70781558, 0.88302315, 0.99998457, 0.72829008, 0.68110709, 0.58630535, 0.63151544, 0.58216433, 0.62582492],
[0.84557946, 0.80451682, 0.72829008, 0.99999463, 0.62038087, 0.57855157, 0.64729217, 0.58224791, 0.63639022],
[0.56751408, 0.66224435, 0.68110709, 0.62038087, 0.99999595, 0.60274483, 0.76304865, 0.59012055, 0.72215898],
[0.5815553 , 0.57870722, 0.58630535, 0.57855157, 0.60274483, 0.99999624, 0.56453708, 0.66506404, 0.62457632],
[0.51876257, 0.61908054, 0.63151544, 0.64729217, 0.76304865, 0.56453708, 0.99999786, 0.57872791, 0.75460535],
[0.56680003, 0.58978685, 0.58216433, 0.58224791, 0.59012055, 0.66506404, 0.57872791, 0.9999968 , 0.57894322],
[0.5870215 , 0.62672988, 0.62582492, 0.63639022, 0.72215898, 0.62457632, 0.75460535, 0.57894322, 0.99999986]])
As expected given its English-only focus, the API performs poorly at cross-language similarity scoring, though unlike the USE English models there are some glimmers of capability.
Comparing English
Since several of the models only support English text, we'll next test on a set of English-language sentences, testing the models' ability to tease out semantic similarity purely within English text. Let's replace our sentences array with the following and repeat the code above to run each model. The first four sentences are Covid-related, while the second four relate to Russia-Europe/US tensions, so we should see a natural divide in the scores and within each of the two topical focuses as well, given their gradation of topical alignment.
sentences = [
"A major Texas hospital system has reported its first case of the lambda COVID-19 variant, as the state reels from the rampant delta variant Houston Methodist Hospital, which operates eight hospitals in its network, said the first lambda case was confirmed Monday Houston Methodist had a little over 100 COVID-19 patients across the hospital system last week. That number rose to 185 Monday, with a majority of those infected being unvaccinated, according to a statement released by the hospital Monday",
"When asked which poses a greater risk to their health, more unvaccinated Americans say the COVID-19 vaccines than say the virus itself, according to a new Yahoo News/YouGov poll — a view that contradicts all available science and data and underscores the challenges that the United States will continue to face as it struggles to stop a growing pandemic of the unvaccinated driven by the hyper-contagious Delta variant. Over the last 18 months, COVID-19 has killed more than 4.1 million people worldwide, including more than 600,000 in the U.S. At the same time, more than 2 billion people worldwide — and more than 186 million Americans — have been at least partially vaccinated against the virus falling ill, getting hospitalized and dying",
"With Covid cases receding and the pandemic officially declared over in many places, life is returning to a new normal.",
"What does the future hold for disease outbreaks?",
"In the midst of tense negotiations with Berlin over a controversial Russia-to-Germany pipeline, the Biden administration is asking a friendly country to stay quiet about its vociferous opposition. And Ukraine is not happy. At the same time, administration officials have quietly urged their Ukrainian counterparts to withhold criticism of a forthcoming agreement with Germany involving the pipeline, according to four people with knowledge of the conversations",
"The U.S. and Germany have reached an agreement allowing the completion of a controversial Russian natural-gas pipeline, according to officials from Berlin and Washington, who expect to announce the deal as soon as Wednesday, bringing an end to years of tension between the two allies The Biden administration will effectively waive Washington’s longstanding opposition to the pipeline, Nord Stream 2, a change in the U.S. stance, ending years of speculation over the fate of the project, which has come to dominate European energy-sector forecasts. Germany under the agreement will agree to assist Ukraine in energy-related projects and diplomacy",
"The White House has become one of the most important backers of Ukraine, providing it funding, weaponry and training.",
"Germany is feeling the effects of the invasion in terms of inflated energy costs."
]
For the USE models, we get:
USE CPU times: user 13.2 ms, sys: 0 ns, total: 13.2 ms Wall time: 10.1 ms [[ 0.99999964 0.3191557 0.1761786 0.06206886 0.11217481 0.13683844 0.02497536 0.01804943] [ 0.3191557 0.9999999 0.3079703 0.28048292 0.19834138 0.2102676 0.00740741 -0.02804848] [ 0.1761786 0.3079703 1. 0.24616265 0.05911933 0.02764775 -0.01875691 0.06231951] [ 0.06206886 0.28048292 0.24616265 1. -0.01017474 0.04519864 -0.07422045 0.04549293] [ 0.11217481 0.19834138 0.05911933 -0.01017474 1. 0.7209815 0.22458138 0.23814848] [ 0.13683844 0.2102676 0.02764775 0.04519864 0.7209815 1. 0.2700295 0.27210674] [ 0.02497536 0.00740741 -0.01875691 -0.07422045 0.22458138 0.2700295 0.99999976 0.18657517] [ 0.01804943 -0.02804848 0.06231951 0.04549293 0.23814848 0.27210674 0.18657517 0.99999994]] USE-LARGE CPU times: user 741 ms, sys: 23.8 ms, total: 765 ms Wall time: 447 ms [[ 9.9999982e-01 4.8642230e-01 2.0852447e-01 2.1276197e-01 8.2670129e-04 3.4839898e-02 4.1454444e-03 2.4966812e-02] [ 4.8642230e-01 1.0000000e+00 2.0480886e-01 3.0387467e-01 1.2318223e-01 1.3239186e-01 9.9974796e-02 2.1050088e-02] [ 2.0852447e-01 2.0480886e-01 9.9999994e-01 2.2720008e-01 4.1212678e-02 3.3281725e-02 2.8075019e-02 -1.4381811e-02] [ 2.1276197e-01 3.0387467e-01 2.2720008e-01 9.9999982e-01 -3.3906180e-02 5.8363091e-02 2.5596652e-02 2.0925827e-02] [ 8.2670129e-04 1.2318223e-01 4.1212678e-02 -3.3906180e-02 9.9999994e-01 8.0045491e-01 2.5281179e-01 2.5787145e-01] [ 3.4839898e-02 1.3239186e-01 3.3281725e-02 5.8363091e-02 8.0045491e-01 9.9999964e-01 2.8857833e-01 2.3334759e-01] [ 4.1454444e-03 9.9974796e-02 2.8075019e-02 2.5596652e-02 2.5281179e-01 2.8857833e-01 9.9999988e-01 6.4825766e-02] [ 2.4966812e-02 2.1050088e-02 -1.4381811e-02 2.0925827e-02 2.5787145e-01 2.3334759e-01 6.4825766e-02 9.9999952e-01]] USE-MULTILINGUAL CPU times: user 119 ms, sys: 2.67 ms, total: 121 ms Wall time: 74.2 ms [[ 1. 0.46617627 0.17139897 0.11178276 0.06444243 0.07206462 -0.00612519 0.00647608] [ 0.46617627 0.9999998 0.19017996 0.23200473 0.13259813 0.16596146 0.06286105 0.10257111] [ 0.17139897 0.19017996 1.0000002 0.1023149 0.02172088 -0.01388931 0.06439219 0.0073823 ] [ 0.11178276 0.23200473 0.1023149 1. -0.06106196 0.09310114 -0.03428502 0.08085603] [ 0.06444243 0.13259813 0.02172088 -0.06106196 0.9999997 0.6099272 0.1664798 0.30971113] [ 0.07206462 0.16596146 -0.01388931 0.09310114 0.6099272 0.9999999 0.12448695 0.41006932] [-0.00612519 0.06286105 0.06439219 -0.03428502 0.1664798 0.12448695 1. 0.12312685] [ 0.00647608 0.10257111 0.0073823 0.08085603 0.30971113 0.41006932 0.12312685 0.99999964]] USE-MULTILINGUAL-LARGE CPU times: user 1.06 s, sys: 9.5 ms, total: 1.07 s Wall time: 594 ms [[ 1.00000000e+00 6.03558421e-01 1.60854027e-01 2.33527735e-01 5.21566756e-02 7.21187443e-02 -5.42238168e-03 -2.10813805e-02] [ 6.03558421e-01 9.99999642e-01 1.38200670e-01 3.44128817e-01 9.28068310e-02 1.63030505e-01 1.40117435e-02 7.83557072e-04] [ 1.60854027e-01 1.38200670e-01 9.99999881e-01 7.56767467e-02 -1.67442095e-02 -7.16786385e-02 -1.22165028e-02 -5.66062666e-02] [ 2.33527735e-01 3.44128817e-01 7.56767467e-02 9.99999642e-01 8.07220340e-02 1.19751662e-01 -1.88719854e-02 9.45629403e-02] [ 5.21566756e-02 9.28068310e-02 -1.67442095e-02 8.07220340e-02 9.99999940e-01 7.60300040e-01 2.49561742e-01 2.16649354e-01] [ 7.21187443e-02 1.63030505e-01 -7.16786385e-02 1.19751662e-01 7.60300040e-01 9.99999642e-01 2.08412215e-01 3.25464189e-01] [-5.42238168e-03 1.40117435e-02 -1.22165028e-02 -1.88719854e-02 2.49561742e-01 2.08412215e-01 1.00000012e+00 5.04850261e-02] [-2.10813805e-02 7.83557072e-04 -5.66062666e-02 9.45629403e-02 2.16649354e-01 3.25464189e-01 5.04850261e-02 9.99999642e-01]]
And for LaBSE:
CPU times: user 8.37 s, sys: 176 ms, total: 8.54 s Wall time: 11.7 s [[1. 0.57421076 0.34065226 0.16414356 0.22075436 0.2793573 0.01160148 0.0802893 ] [0.57421076 0.9999999 0.30633876 0.28348556 0.27467766 0.39089608 0.05584354 0.11225564] [0.34065226 0.30633876 0.99999976 0.23068674 0.08986091 0.12886982 0.05010479 0.13240156] [0.16414356 0.28348556 0.23068674 1.0000002 0.05592237 0.13137099 0.09381138 0.18888909] [0.22075436 0.27467766 0.08986091 0.05592237 1. 0.7027599 0.06644913 0.14700775] [0.2793573 0.39089608 0.12886982 0.13137099 0.7027599 1. 0.06815526 0.20499358] [0.01160148 0.05584354 0.05010479 0.09381138 0.06644913 0.06815526 1.0000001 0.14871709] [0.0802893 0.11225564 0.13240156 0.18888909 0.14700775 0.20499358 0.14871709 1. ]]
And for Vertex Embeddings:
[[0.99999639 0.70451069 0.64270889 0.59246741 0.59100159 0.61792996 0.56669665 0.51542982] [0.70451069 0.99999484 0.66621967 0.58955919 0.61934633 0.64772142 0.5697951 0.51846324] [0.64270889 0.66621967 0.99999875 0.57274274 0.52454585 0.60844185 0.45549533 0.50970171] [0.59246741 0.58955919 0.57274274 0.99999956 0.49716405 0.52788605 0.44937107 0.48551571] [0.59100159 0.61934633 0.52454585 0.49716405 0.99999648 0.8543619 0.65951606 0.59093366] [0.61792996 0.64772142 0.60844185 0.52788605 0.8543619 0.99999664 0.64045207 0.62069932] [0.56669665 0.5697951 0.45549533 0.44937107 0.65951606 0.64045207 0.99999885 0.49518657] [0.51542982 0.51846324 0.50970171 0.48551571 0.59093366 0.62069932 0.49518657 0.99999918]]
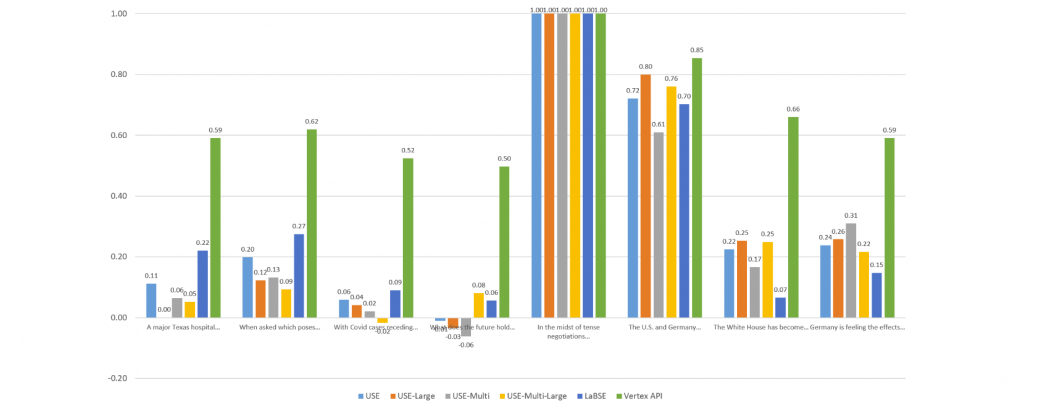
Visualizing The English Similarities
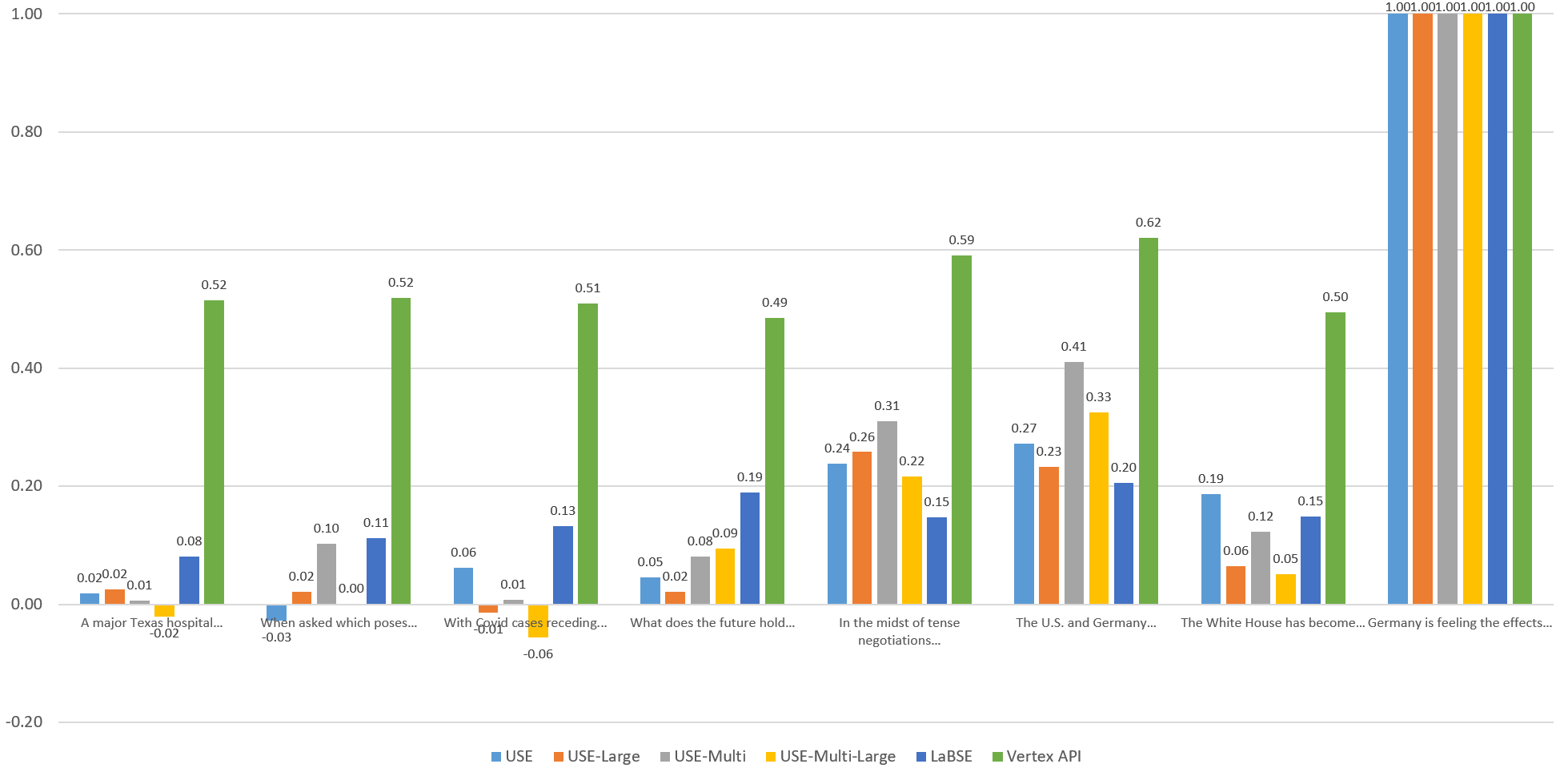
To compare the models visually, let's graph the computed similarity of each sentence against the others through the eyes of each model. Each of the graphs below compares the given sentence against itself and the other 7 sentences through the eyes of each embedding model. Overall, Vertex scores fall within an extremely narrow band, with both highly similar and entirely unrelated sentences all falling within a fairly tight band. The other models exhibit stronger stratification, but no single model yields "ideal" results, with each more sensitive to specific aspects of the language.
Sentence 1
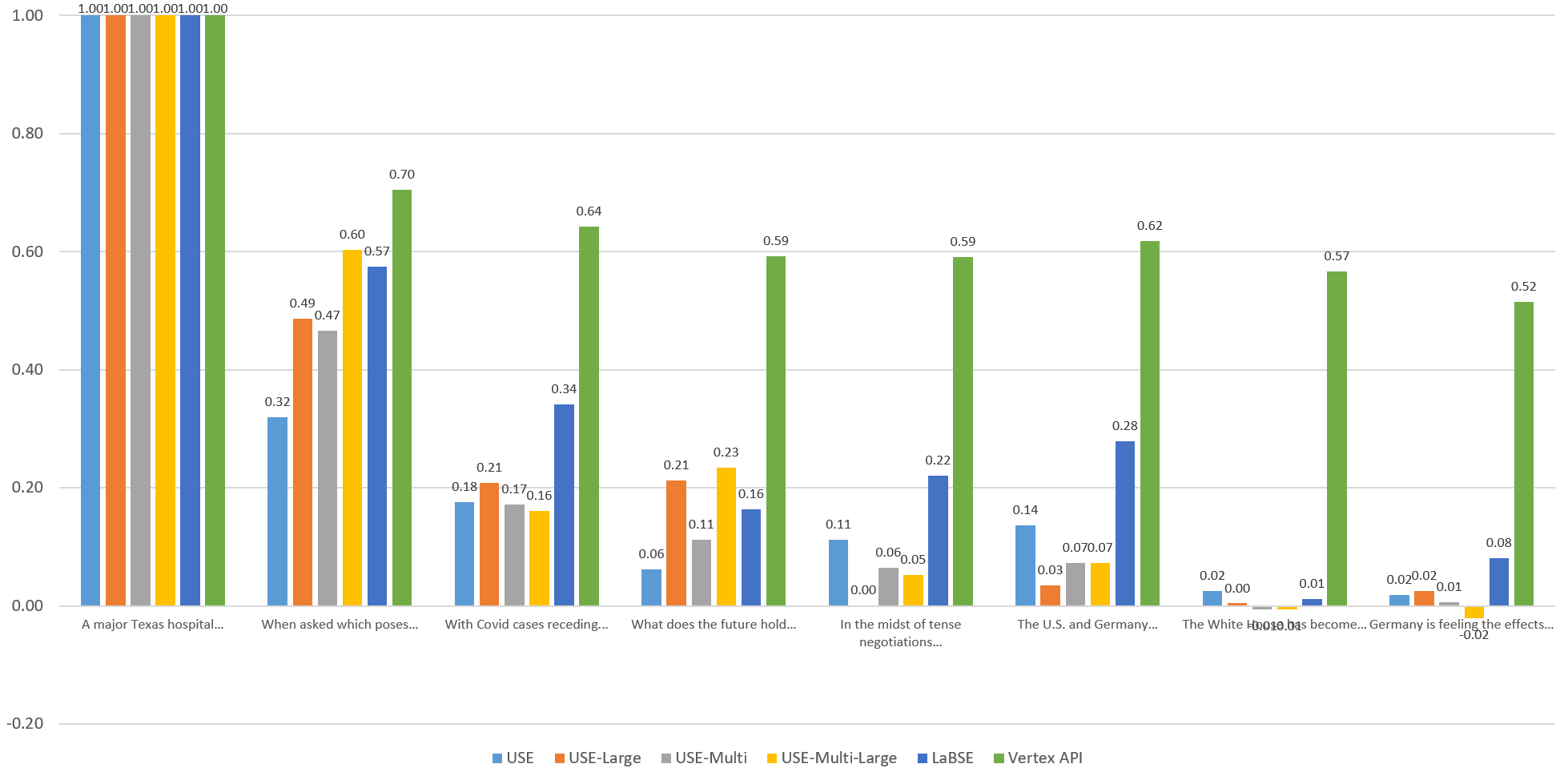
Sentence 2
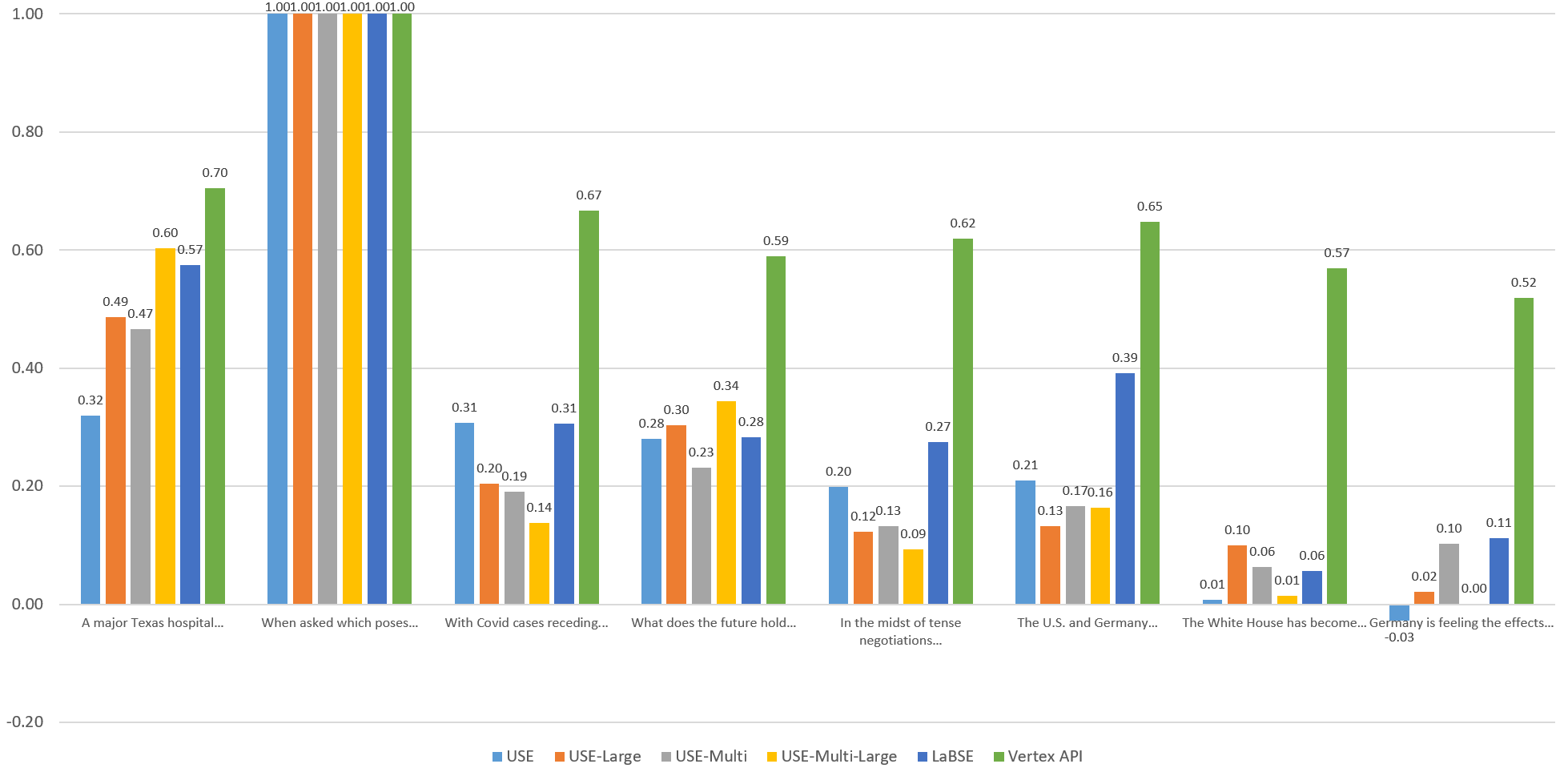
Sentence 3
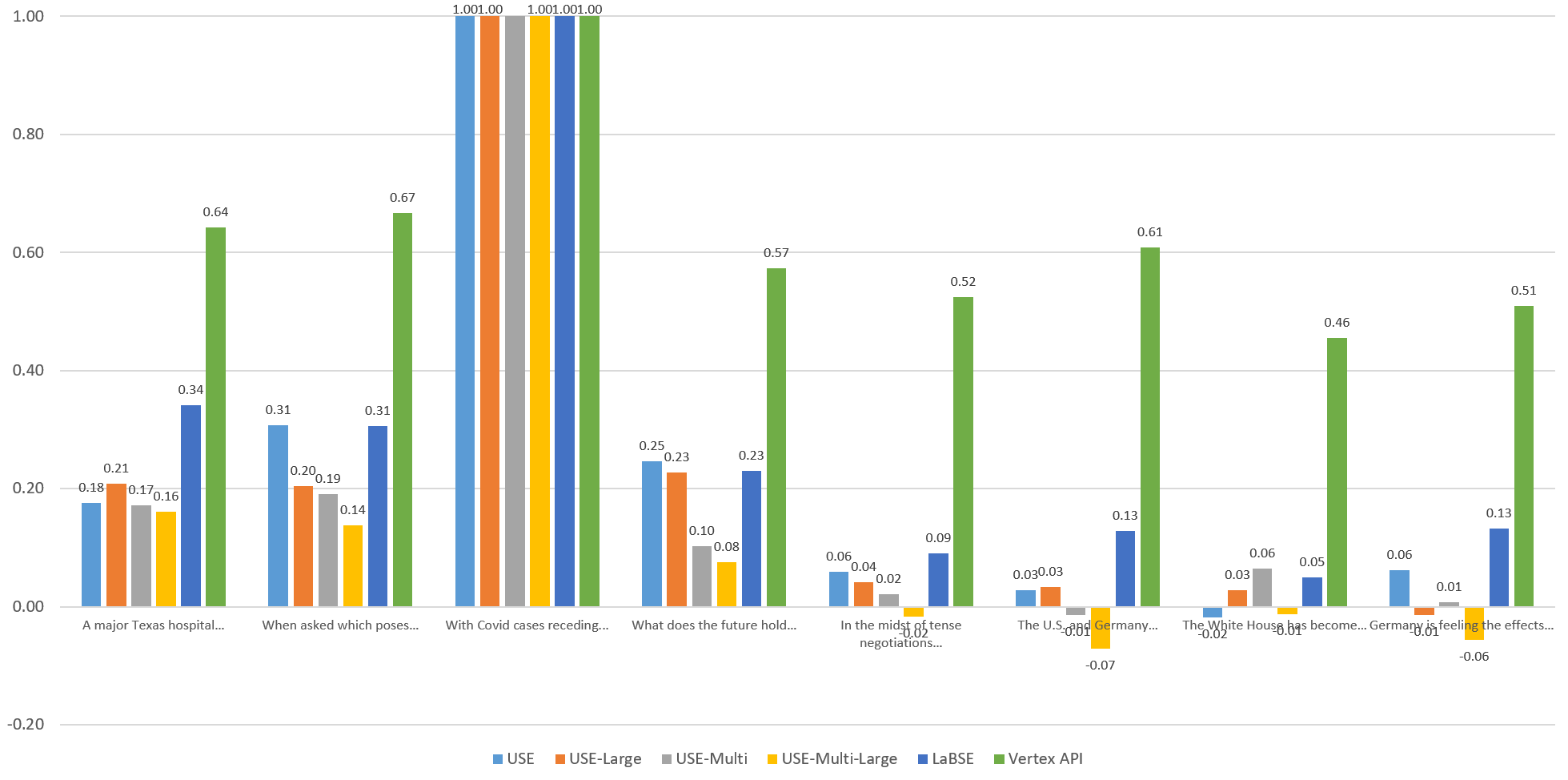
Sentence 4
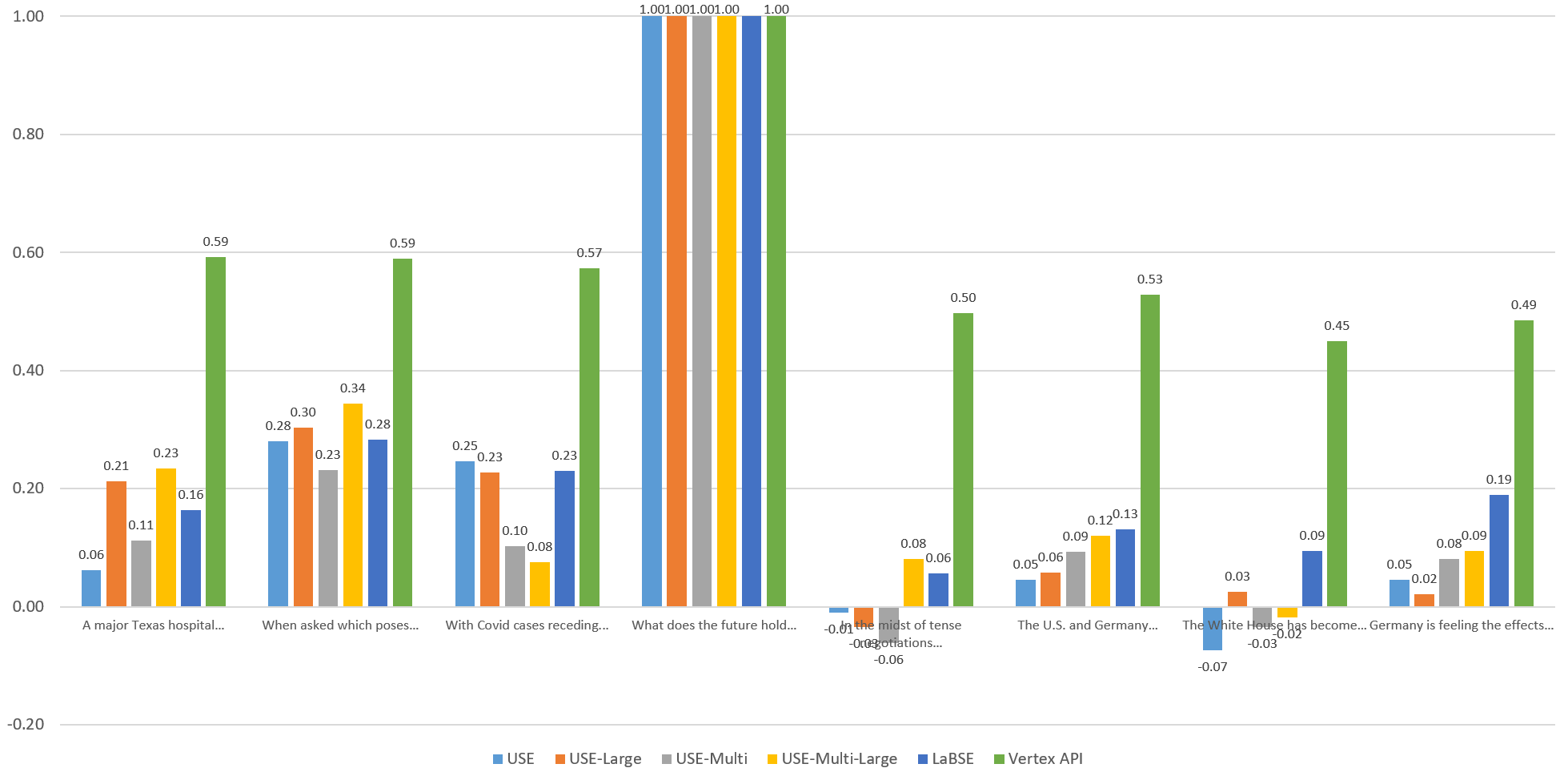
Sentence 5
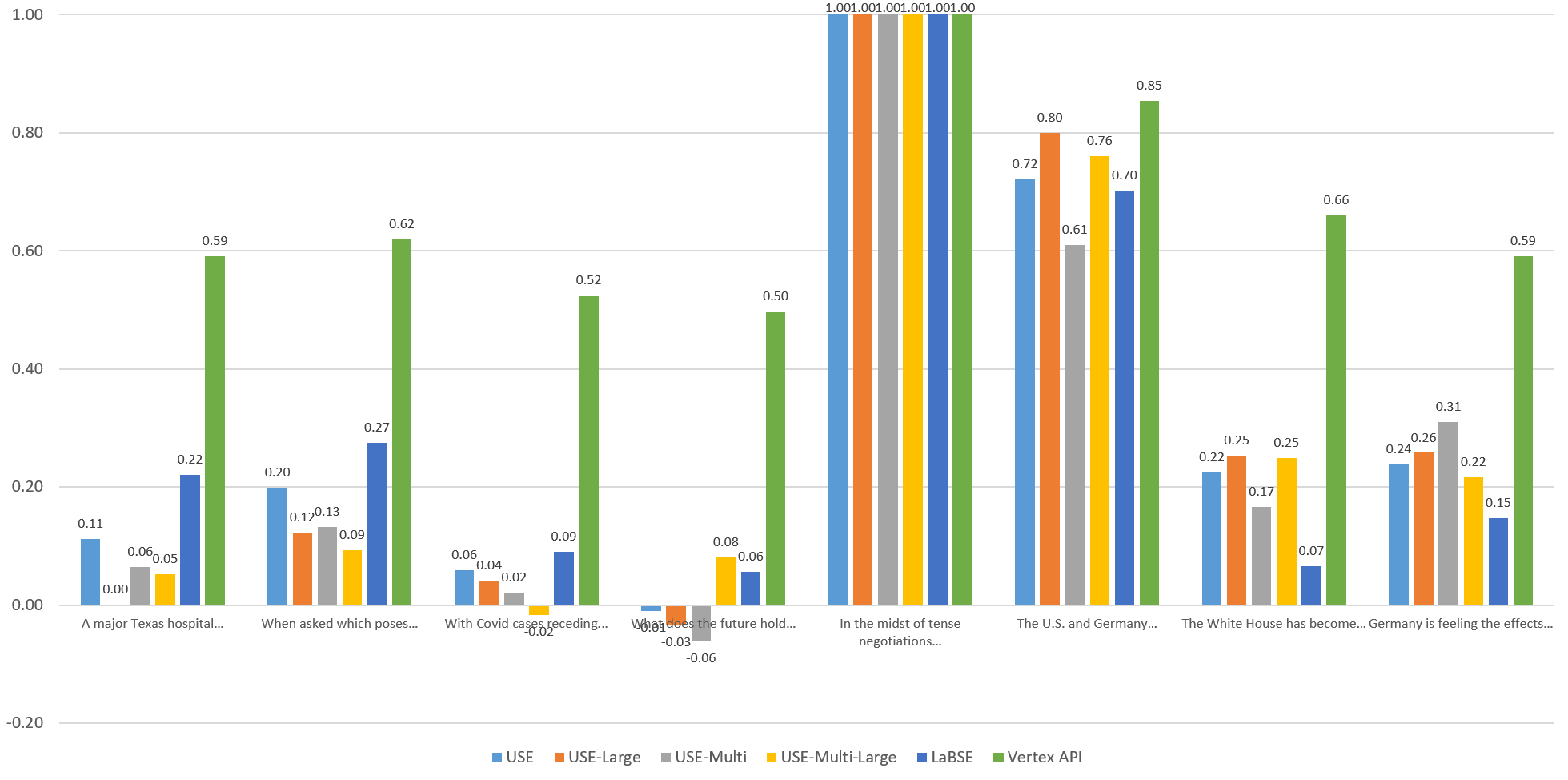
Sentence 6
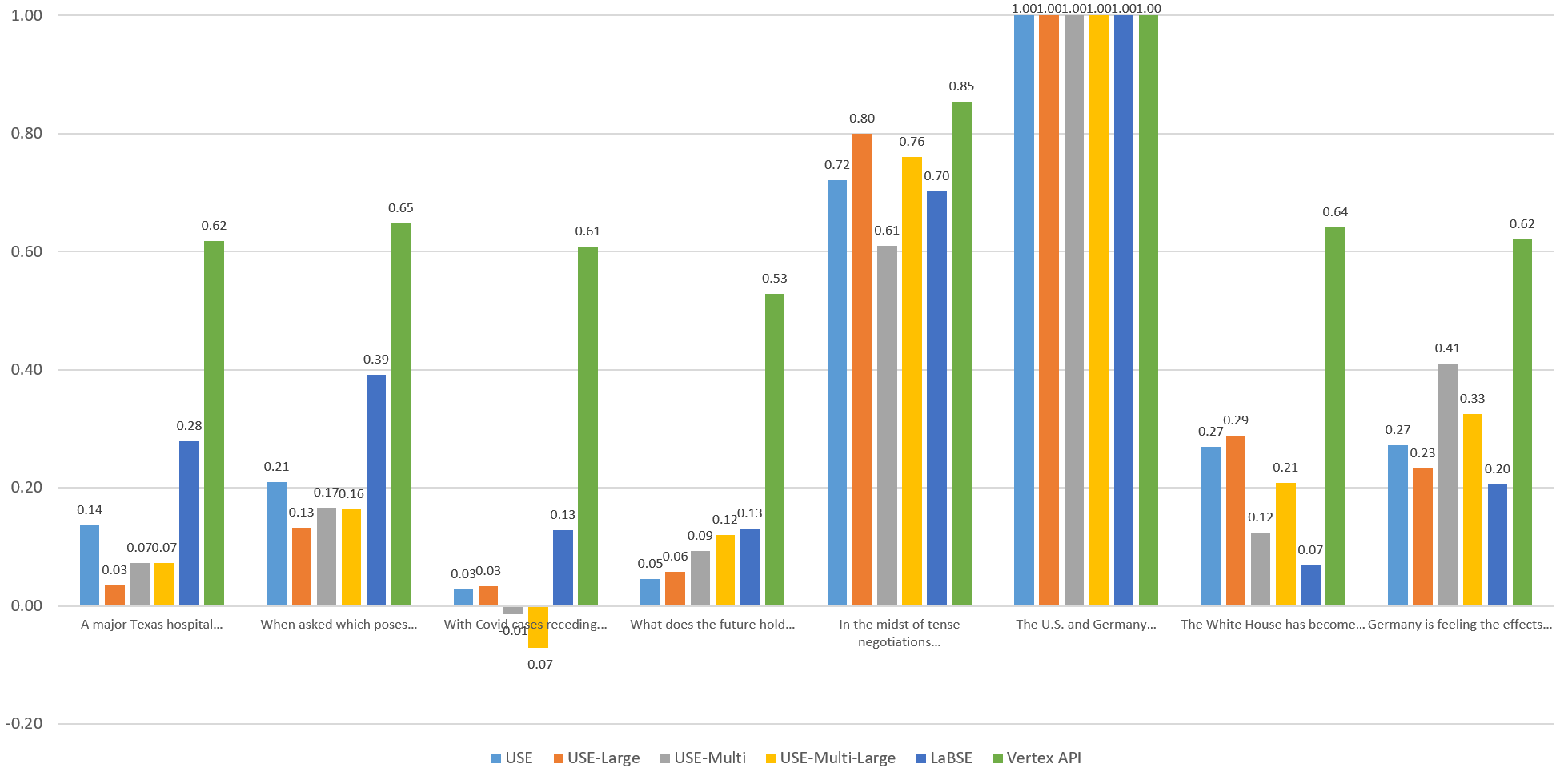
Sentence 7
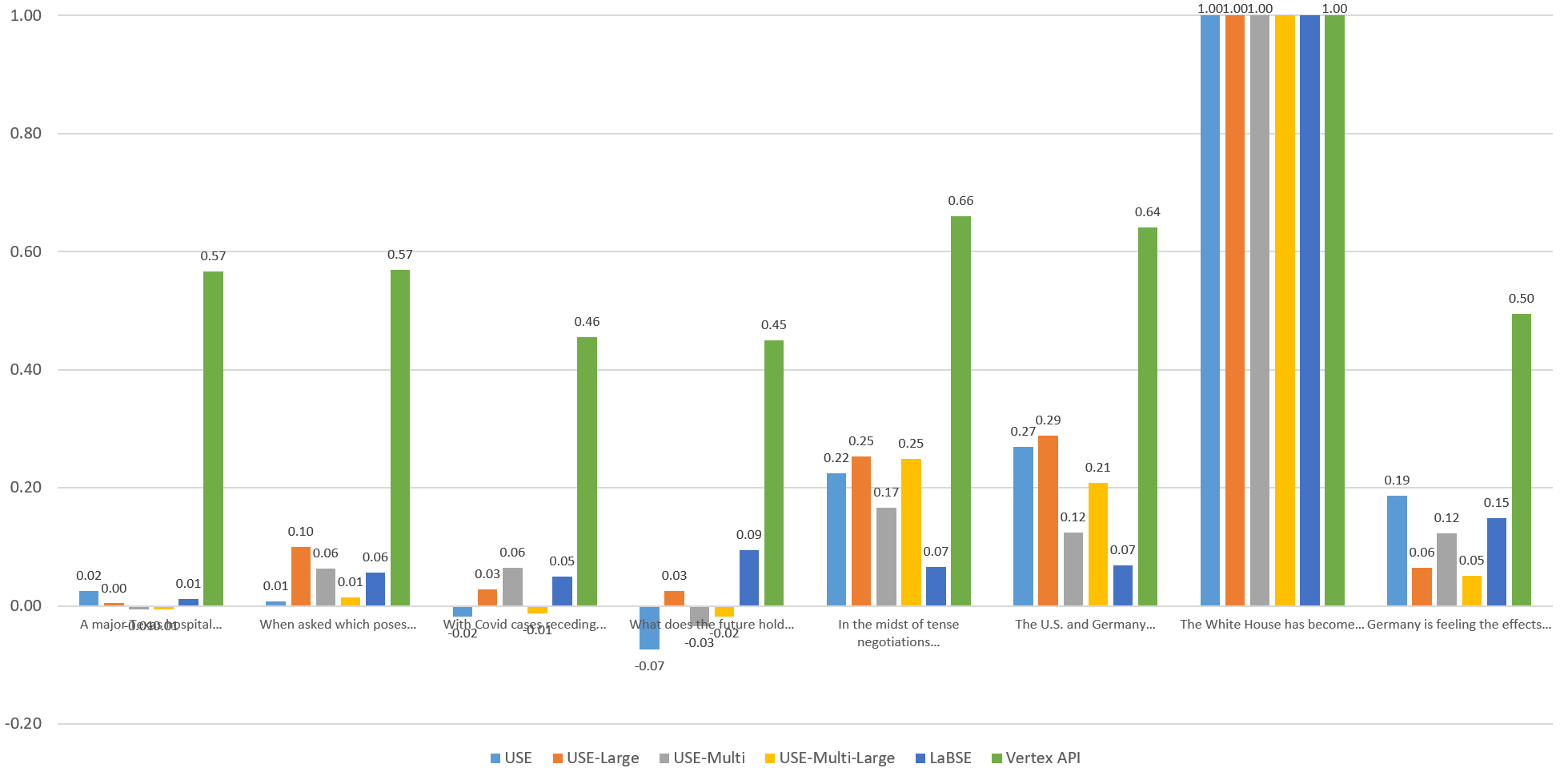
Sentence 8
PCA Visualization
We can also collapse the high-dimensionality embeddings down to three dimensions using PCA, allowing us to trivially visualize them as a scatterplot. To visualize any of the embedding results above, just add this cell to your Colab notebook:
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
embeds_pca = pca.fit_transform(embeds)
#print(embeds_pca.tolist())
import plotly.graph_objs as go
import numpy as np
trace = go.Scatter3d(
x=embeds_pca[:, 0],
y=embeds_pca[:, 1],
z=embeds_pca[:, 2],
mode='markers',
marker=dict(
size=5,
color=np.arange(len(embeds_pca)),
colorscale='Viridis',
opacity=0.8
),
text=sentences
)
layout = go.Layout(
title='PCA Plot',
scene=dict(
xaxis=dict(title=''),
yaxis=dict(title=''),
zaxis=dict(title=''),
)
)
fig = go.Figure(data=[trace], layout=layout)
fig.update_layout(hovermode='closest', hoverlabel=dict(bgcolor="white", font_size=12))
fig.show( width=800, height=800)
This will yield an interactive visualization that you can zoom/pan and mouse over each point to see the text of the sentence it represents. The image below is a static screen capture of the interactive version:
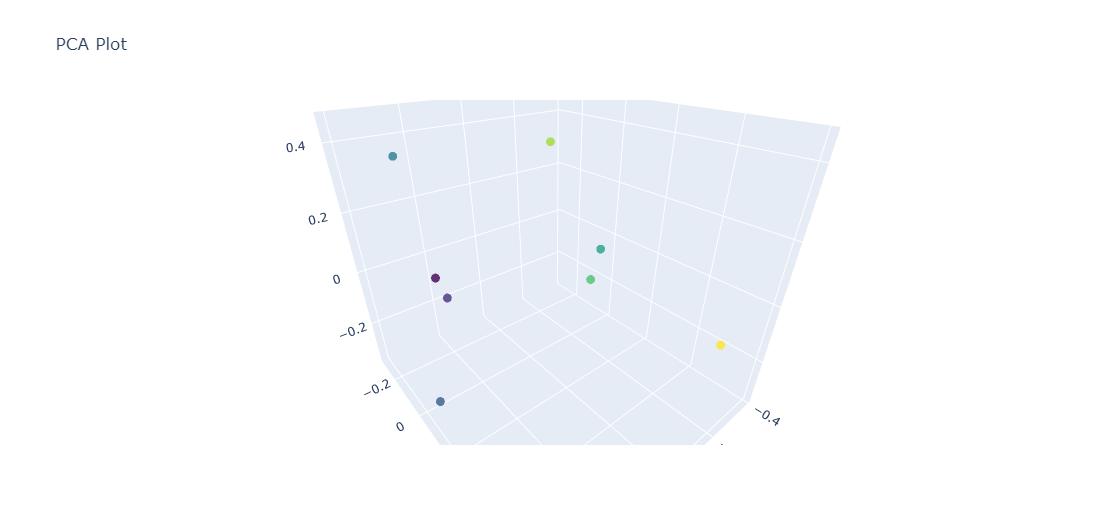
This is an easy way to visualize how different embedding models cluster the results.
Conclusions
Looking across these results, there are several key findings that mirror our earlier results from 2021:
- Language Limitations. While models will happily generate embedding vectors for any textual input, content in languages outside their officially supported list will typically yield semantically irrelevant embeddings that cannot be used for similarity scoring. This is the expected behavior, but reinforces the need to either find models capable of supporting every single required language for a given use case or to first translate all content into a single unified language such as English and using a monolingual embedding.
- Language Affinity. Even when limiting inputs to languages officially supported by an embedding model, the outputs will still yield similarity scores that reflect to some degree language affinity, with content in the same language or in languages that cooccur more frequently on the web having higher similarity scores, even if the specific passages in question are less similar. In other words, multilingual models are unable to fully overcome linguistic differences, though the impact of this on the downstream task depends on the specifics of the given use case.
- Multilingual Capabilities. With the caveat of language affinity, true multilingual models like USE-Multi do achieve reasonable results when looking across languages, meaning that applications that can limit their inputs to the supported languages can achieve reasonable results in cross-language retrieval tasks.
- Larger Is Not Better. The size of the underlying model does not appear to be highly correlated with its performance, at least within the scope of these two example sets. Larger models did not uniformly result in more accurate similarity scores, while smaller models sometimes outperformed them. Our previous work has shown that larger more complex models also tend to be more brittle, with higher sensitivity to the grammatical and linguistic error incurred by machine translation and speech recognition pipelines, making simpler models often a better fit for those specific use cases.
- Task Dependency. Models that are optimized for specific tasks may not perform as well on others. For example, LaBSE was designed for bitext retrieval to support translation ranking tasks, meaning that while it supports 109 languages, the similarity scores it generates can sometimes deviate from expectation due to its closer adherence to bilingual similarity rather than general gist topical similarity.
- Newer Is Not Better. The USE family of models are now half a decade old, but perform extremely well on these benchmarks. In internal testing, they continue to outperform many newer embedding models, including 2023-vintage models in many of our similarity and clustering tasks.
- Application Specific Benchmarks. There is a vast and growing landscape of benchmarks across myriad embedding tasks. Yet, as we have found internally, these benchmarks, even those in the same domain, language and use case (such as clustering English-language news articles from US-only outlets), can yield results far afield from what we ourselves observe on our real-world production workloads. Thus, it is critical to perform your own application-specific benchmarking to see which model works the best for your specific application.
- No Universal Model. As attested by both the results above and the myriad benchmarking leaderboards, no single embedding model produces results superior to all others in all use cases. In fact, model selection today is as much art as science, often with many models performing roughly equally, where characteristics like execution time and resource requirements playing a differentiating role.
- Execution Speed & Resource Requirements. As the examples on this page demonstrate, models can differ by hundreds or even thousands of times execution time, ranging from just a few milliseconds for an entire batch of text to tens of seconds. Offline-only batch applications (such as daily news clustering) may be able to accept multi-second execution times, but applications that must respond to user input require sub-second responsiveness. The amount of resources required to run a model effectively can also play a crucial role, with some models so efficient that it can be difficult to saturate them on a single-core VM, while others can require multiple latest-generation GPUs, vastly increasing both their runtime cost and their brittleness.
- Input Length. Many models have absolute hard limits on the maximum input length they accept, with some having extremely limited input lengths. This means text must be artificially chunked for processing, with the chunking mechanism becoming a limiting factor. Other models can effectively and efficiently handle unlimited-length text, generating document-level embeddings that reflect their overall mix of topics.
- Output Length. Models output a range of vector sizes, from as small as 128-dimension vectors to 10,000+ dimensions. The larger the output, the more differentiating the vector becomes, which can help with semantic retrieval, but harm similarity-based clustering. Most importantly, larger vectors can incur substantial storage and retrieval costs, dramatically slowing an application's querytime performance.
- Post Relevancy Filtering. The most effective production applications typically use embedding similarity scores as a form of rough semantic search, then perform more targeted relevancy filtering using topical, entity, sentiment or other traditional targeted reranking and relevancy filtering. Even LLM-based summarization pipelines typically perform an additional filtering step. Such post-filtering can impact the specific embedding model selected or even combinations of models that weight different factors for different kinds of queries.
In the end, applications will typically need to perform their own benchmarking of models based on their specific mix of languages, execution speed, task, content and overall use case, but even older models can achieve strong results for many applications.