Could thumbnail contact sheets offer the possibility of non-consumptive visual assessment of television news, such as applying at-scale AI visual analysis and OCR to broadcasts? Let's take the 500 pixel contact sheet for the 1TV broadcast from April 26, 2022 3:30-4:01AM MSK that we created earlier. Skimming through the sheet we see that thumbnail #88 is a screen capture of an RIA Novosti online news article, offering an ideal test of how possible it might be to perform OCR recovery of at least full-screen text like this.
{kind=link}
Thankfully, FFMPEG makes it trivial to decompose one of our contact sheets into a sequence of individual image files using its "untile" filter.
First, we have to convert the JPEG thumbnail sheet into a PNG file. For unknown reasons FFMPEG will error if we attempt to untile the original JPEG image. Since these are large images, they will typically exceed the default limits of ImageMagick. Thus, you will need to edit ImageMagick's "policy.xml" file on your machine to allow it to open much larger images:
/etc/ImageMagick-6/policy.xml
And change the "width" and "height" lines to "100KP" or larger:
<policy domain="resource" name="width" value="100KP"/> <policy domain="resource" name="height" value="100KP"/>
And verify the changes were recorded:
identify -list resource
Now convert to a PNG image:
time convert ./1TV_20220426_003000-fps4-500.jpg ./1TV_20220426_003000-fps4-500.png
Now we can simply run FFMPEG in untiling mode:
mkdir FRAMES time ffmpeg -r 1 -i ./1TV_20220426_003000-fps4-500.png -vf "untile=6x120" "./FRAMES/1TV_20220426_003000-%6d.png"
Black frames aren't useful, so let's remove them by eliminating images that are less than 1K in size:
find ./FRAMES/ -name "*.png" -type 'f' -size -1000c -delete
Now take the 88th thumbnail from that directory ("1TV_20220426_003000-000088.png"):

Download that image to your computer and drag-drop it onto Google Cloud Vision's online demo page. You can see everything Cloud Vision sees about the image.
For example, this is the result of logo detection, showing it recognizing the RIA Novosti logo:

Similarly, OCR recognizes the onscreen text:
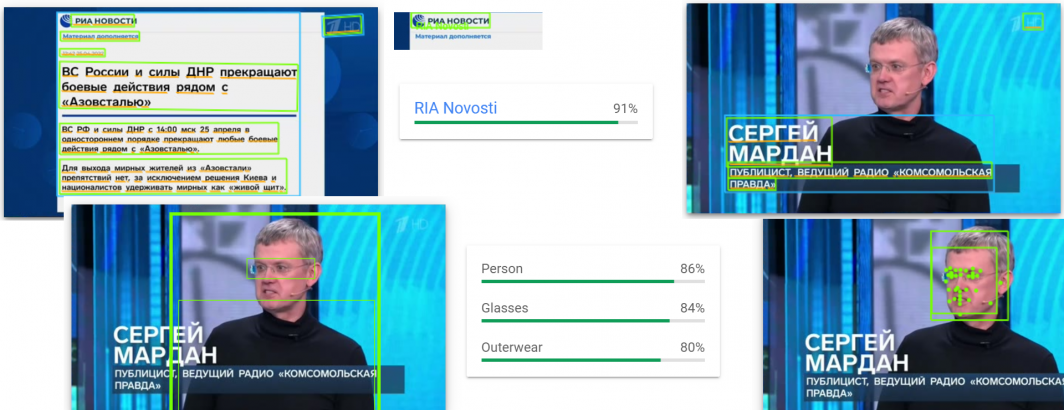
And extracts it as:
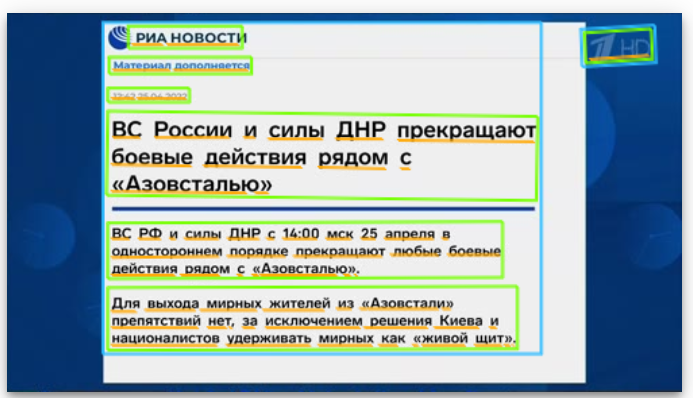
РИА НОВОСТИ Материал дополняется 12:42 25.04.2022 ВС России и силы ДНР прекращают боевые действия рядом с <<Азовсталью» ВС РФ и силы ДНР с 14:00 мск 25 апреля в од ностороннем порядке прекращают любые боевые действия рядом с <<Азовсталью». Для выхода мирных жителей из <<Азовстали>> препятствий нет, за исключением решения Киева и националисто в удерживать мирных как «живой щит». 7HD
There are noticeable typos in the text, but overall it extracted a reasonable facsimile of the text, which Google Translate translates as:
RIA NEWS The material is complemented 12:42 25.04.2022 Russian Armed Forces and DNR forces stop fighting near <<Azovstal" The Armed Forces of the Russian Federation and the forces of the DPR from 14:00 Moscow time on April 25 to one sideways stop any combat actions near "Azovstal". For the exit of civilians from <<Azovstal>> there are no obstacles, except for the decision of Kyiv and nationalist to hold the civilians as a "human shield". 7HD
What about a chyron example? Frame #158 contains a mixed chyron with a top two-level text container with a transparent background and a second two-level text block on a semi-transparent background:

Once again, we download it and run it through the Google Cloud Vision online demo.
It recognizes that there is a human face at 94% confidence, estimating it to have 1 degree roll, -2 degree tilt and -22 degree pan:
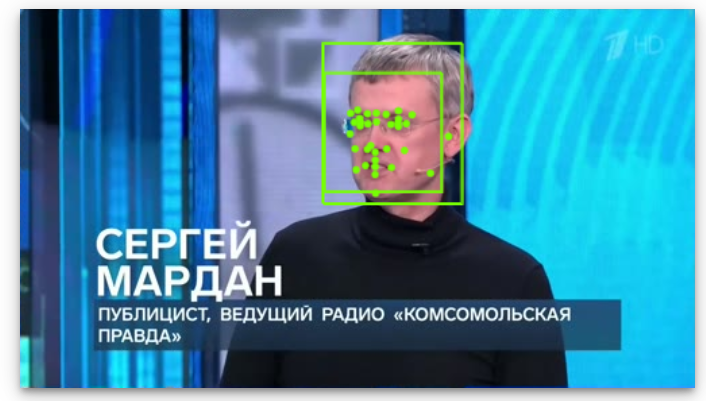
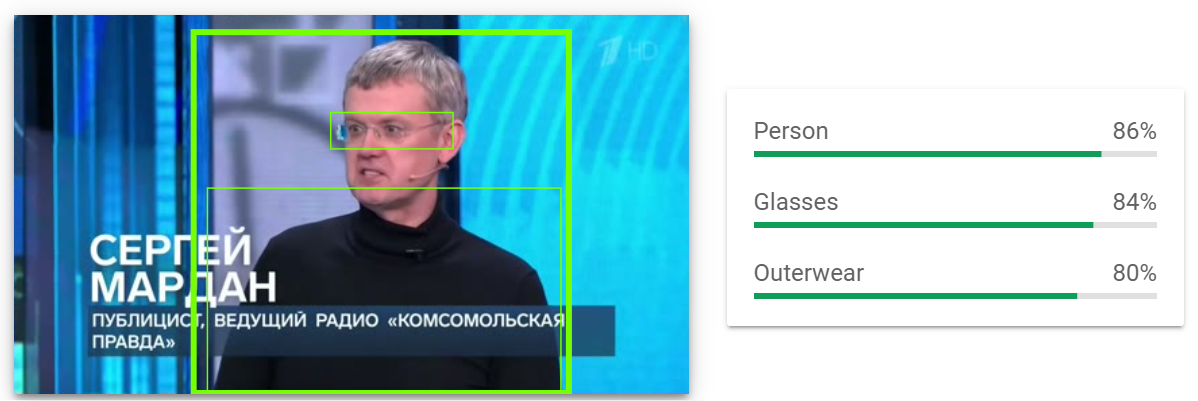
It recognizes that the image contains a person wearing glasses.
It recognizes the faint 1TV watermarked logo at top right.
![]()
It recognizes the onscreen text as well.
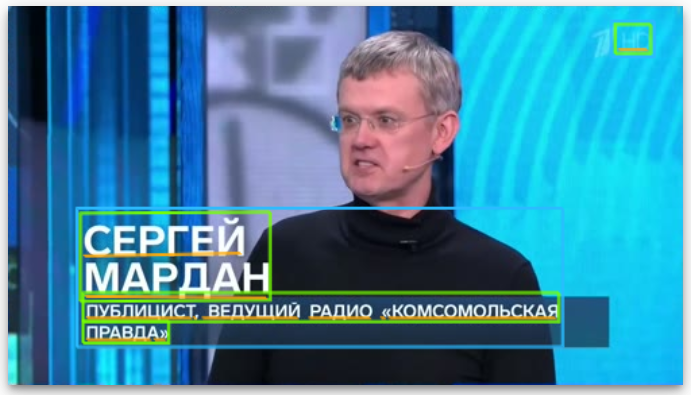
It extracts the text as:
СЕРГЕЙ МАРДАН ПУБЛИЦИСТ, ВЕДУЩИЙ РАДИО «КОМСОМОЛЬСКАЯ ПРАВДА>> HD
Which Google Translate translates as:
SERGEI MARDAN PUBLICIST, LEADING RADIO "KOMSOMOLSKAYA PRAVDA>> HD
Scanning for chyron text that appears while a person is visible onscreen could be one option to catalog onscreen interviewees.
Thus, from a simple non-consumptive thumbnail contact sheet, we can perform sufficiently advanced AI visual analysis and OCR text recovery!
While far less accurate than native video OCR and suffering from all of the compression artifacts of taking the original compressed MPEG video, converting to JPEG, then back to PNG, the end result is quite serviceable. Importantly, since it involves simple static image OCR, its computational demands are just a small fraction of full resolution video OCR, with a wide range of off-the-shelf OCR tools available compared with video.
A half-hour broadcast yields 1,800 seconds of airtime and since we sample it at one frame every 4 seconds, there are 450 resulting thumbnails. Using a state-of-the-art image OCR tool like Cloud Vision that charges $1.50 per 1,000 images, a half-hour broadcast using this workflow would cost just $0.75 cents versus $4.50 for native video OCR.