UPDATE (1/21/2020): The GEG neural sentiment scores are now integrated into the core GEG dataset instead of a separate dataset.
Last month as part of the Global Entity Graph (GEG) we released a dataset of neurally-derived document-level sentiment scores for 103 million worldwide English-language news articles published 2016-2019 as computed by Google's Cloud Natural Language API. How do these deep learning-powered sentiment scores compare with the classical bag-of-word sentiment scores computed by both the GDELT V2Tone engine in the GKG and some of the major positive/negative tone scores in the GKG's GCAM?
While the GEG neural sentiment dataset extends back to July 2016, changes in the composition of articles GDELT ran through the Cloud Natural Language API (it initially favored longer articles or articles with certain kinds of linguistic complexity versus the random sampling approach eventually adopted), this comparison is limited to the timeframe September 1, 2017 through the October 4, 2019 end of the dataset, which yields 69,443,572 total articles (67% of the total).
To compare the classical scores of the GKG with the neural GEG score, the two datasets were merged in BigQuery with a single join. Of the nearly 3,000 dimensions in the GCAM, six common positive/negative dictionaries were selected along with GDELT's native basic tone score:
- ANEW (Affective Norms for English Words). The all-genders Valence score was used. Affective norms for English words (ANEW): Stimuli, instruction manual and affective ratings. Technical report C-1, Gainesville, FL. The Center for Research in Psychophysiology, University of Florida.
- General Inquirer. Computed as "POSAFF – NEGAFF". This is the "General Inquirer V1.02 (IV-4 Harvard Psychosocial Dictionary / Namenwirth & Weber's Lasswell Dictionary)". Philip J. Stone, Robert F. Bales, Zvi Namenwirth, & Daniel M. Ogilvie (1962). 'The General Inquirer: A computer system for content analysis and retrieval based on the sentence as a unit of information'. Behavioral Science, 7(4), 484-498
- GDELT GKG V2Tone. This is GDELT's native basic tone score, designed to offer a general-purpose tone indicator.
- Lexicoder. Computed as "POSITIVE – NEGATIVE". Lori Young and Stuart Soroka. (2012). 'Affective News: The Automated Coding of Sentiment in Political Texts'. Political Communication 29: 205-231. Available at http://lexicoder.com/
- LIWC (Linguistic Inquiry and Word Count). Computed as "PositiveEmotion – NegativeEmotion". Pennebaker, J. W., Booth, R. J., & Francis, M. E. (2007). 'Linguistic Inquiry and Word Count: LIWC [Computer software]'. Austin, TX. Available at http://www.liwc.net/
- Opinion Observer. Computed as "Positive – Negative". Bing Liu, Minqing Hu and Junsheng Cheng. (2005). 'Opinion Observer: Analyzing and Comparing Opinions on the Web.' Proceedings of the 14th International World Wide Web conference (WWW-2005), May 10-14, 2005, Chiba, Japan.
- SentiWordNet 3.0. Computed as "Positive – Negative". Andrea Esuli Stefano Baccianella and Fabrizio Sebastiani. (2010). 'Sentiwordnet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining'. In LREC.
The document-level correlations across the 69 million articles ranged from 0.5 at the highest to 0.27 at the lowest. Much of the deviation seems to lie in subtle differences in the intensity of positivity or negativity assigned by each dictionary (classical dictionaries often assigned greater intensities of emotion).
Many use cases simply catalog articles into "positive" and "negative" bins. For GDELT's basic tone measure, just over 90% of the 69 million articles for which the Natural Language API assigned a tone score matched in terms of polarity between GDELT's classical tone and the GEG's neural tone (ie, both scores were positive or both were negative for a given article). Of the 10% of articles where the Natural Language API assigned a non-zero tone score and which yielded a polarity different from GDELT's classical score, the differences tended to be in more complex cases, such as an article about a rise in fatal car crashes discussing a new life-saving technology or recounting the devastation of Ebola while lauding new medicines.
Given the shear volume of the deluge digital deluge, a wide range of use cases are more concerned with aggregate daily tone rather than individual document-scores. For example, brand awareness, economic risk modeling, political conflict assessment and many other applications are based on temporally aggregated scores, frequently at the daily level, rather than on sorting each individual article into a tone bin.
Comparing the aggregate daily tone scores, the seven dictionaries range from a correlation of 0.82 to 0.24 (r=762).
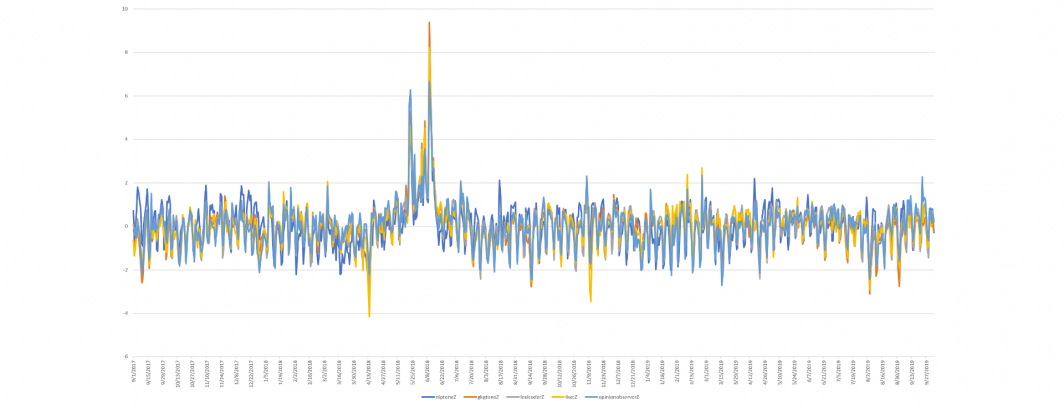
The barchart below shows both the daily and document-level correlations by dictionary.

The timeline below compares the Cloud Natural Language API's scores against the GKG, Lexicoder, LIWC and Opinion Observer dictionaries, illustrating that that these correlations have been constant over the entire three-year comparison period, suggesting they are relatively stable. A closer look at the timeline suggests that much of the difference between the dictionaries lies not in their positive/negative categorization (polarity) but rather the intensity of emotion each assigns.
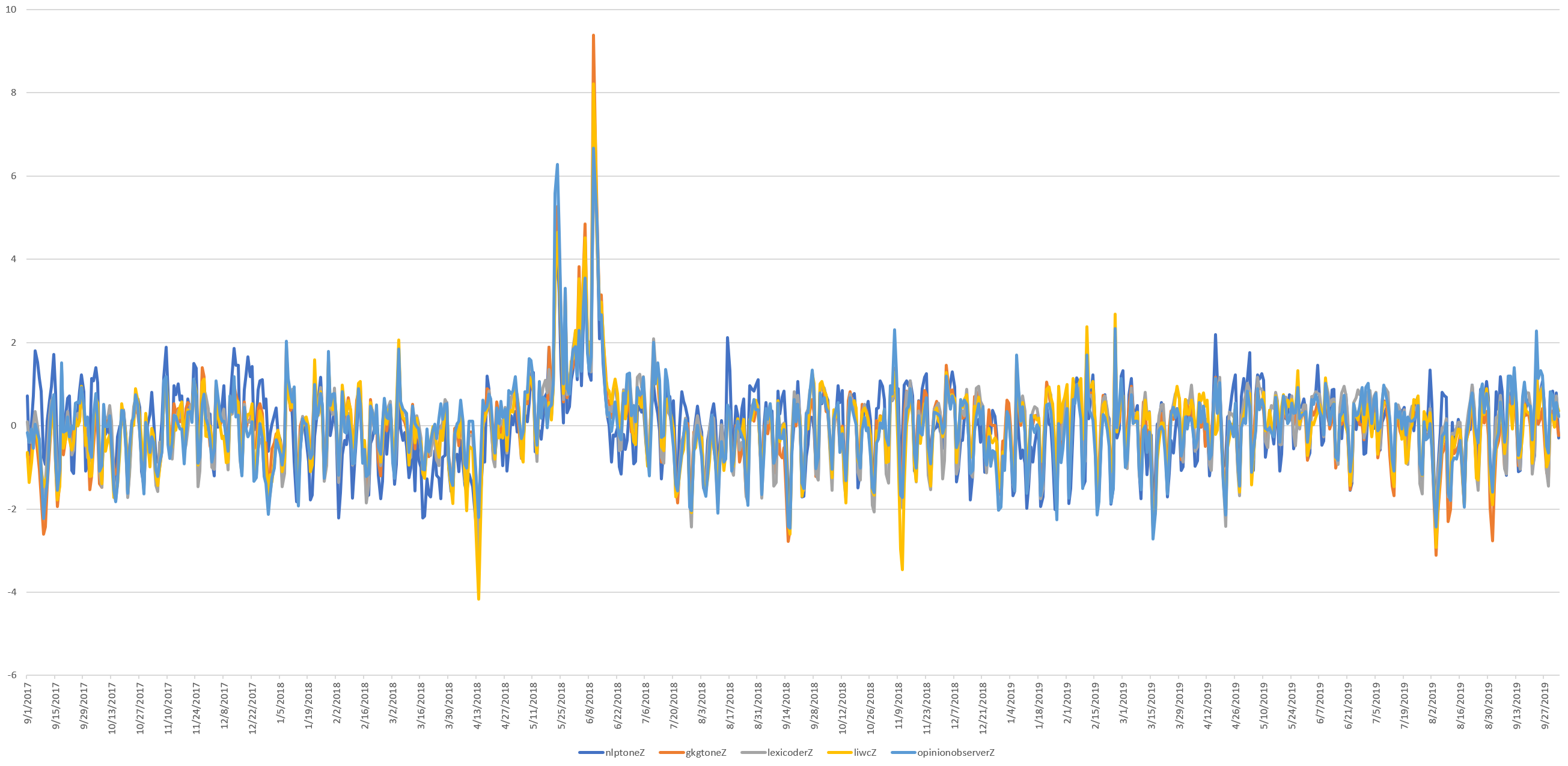
Putting this all together, at the document level, for articles for which the Cloud Natural Language API assigns a non-zero tone, there is a 90% agreement of polarity with the GKG's classical tone score. A document-level score correlation of r=0.5 (n=69,443,572) reflects the larger emotional range over which classical approaches score. At the more common daily aggregation level, correlations of as high as r=0.82 (n=762) is observed, with much of the underlying difference due to slight differences in assigned intensity, while overall macro trends are nearly identical.
TECHNICAL DETAILS
Merging the GKG and GEG sentiment scores took only a single SQL query.
SELECT a.date date, a.url url, a.lang lang, a.polarity nlppolarity, a.magnitude nlpmagnitude, a.score nlpscore, b.V2Tone gkgtone, b.GCAM gkggcam FROM
( select * FROM `gdelt-bq.gdeltv2.geg_gcnlapisent`) a
LEFT JOIN (
( SELECT DocumentIdentifier url, V2Tone, GCAM FROM `gdelt-bq.gdeltv2.gkg_partitioned`)
) b
USING (url)
The resulting 1TB output was saved into a temporary table where the following query was used to construct the spreadsheet used in the analyses above.
SELECT FORMAT_TIMESTAMP( "%m/%d/%E4Y", DATE) day, AVG(nlppolarity * nlpmagnitude) nlptone, AVG(CAST(REGEXP_REPLACE(gkgtone, r',.*', "") AS FLOAT64)) gkgtone, AVG(CAST(REGEXP_EXTRACT(gkggcam, r'v19.1:([-\d\.]+)') AS FLOAT64)) anew, AVG( (CAST(REGEXP_EXTRACT(gkggcam, r'c2.131:([-\d\.]+)') AS FLOAT64) - CAST(REGEXP_EXTRACT(gkggcam, r'c2.107:([-\d\.]+)') AS FLOAT64) ) / CAST(REGEXP_EXTRACT(gkggcam, r'wc:([-\d\.]+)') AS FLOAT64) ) generalinquirer, AVG( (CAST(REGEXP_EXTRACT(gkggcam, r'c3.2:([-\d\.]+)') AS FLOAT64) - CAST(REGEXP_EXTRACT(gkggcam, r'c3.1:([-\d\.]+)') AS FLOAT64) ) / CAST(REGEXP_EXTRACT(gkggcam, r'wc:([-\d\.]+)') AS FLOAT64) ) lexicoder, AVG( (CAST(REGEXP_EXTRACT(gkggcam, r'c5.35:([-\d\.]+)') AS FLOAT64) - CAST(REGEXP_EXTRACT(gkggcam, r'c5.34:([-\d\.]+)') AS FLOAT64) ) / CAST(REGEXP_EXTRACT(gkggcam, r'wc:([-\d\.]+)') AS FLOAT64) ) liwc, AVG( (CAST(REGEXP_EXTRACT(gkggcam, r'c7.2:([-\d\.]+)') AS FLOAT64) - CAST(REGEXP_EXTRACT(gkggcam, r'c7.1:([-\d\.]+)') AS FLOAT64) ) / CAST(REGEXP_EXTRACT(gkggcam, r'wc:([-\d\.]+)') AS FLOAT64) ) opinionobserver, AVG( (CAST(REGEXP_EXTRACT(gkggcam, r'v10.1:([-\d\.]+)') AS FLOAT64) - CAST(REGEXP_EXTRACT(gkggcam, r'v10.2:([-\d\.]+)') AS FLOAT64) ) ) sentiwordnet3 FROM `TEMPORARYTABLE` group by day order by day
We hope this analysis offers you useful insights as you explore how to incorporate sentiment into your own projects.