GDELT today monitors global news coverage in more than 150 languages, with GDELT 3.0 to expand that number to nearly 400, spanning coverage from every corner of the globe in realtime, creating a planetary-scale realtime digital mirror and observatory of global human society. GDELT's realtime firehoses capture the pulse of the planet, transforming the planetary firehose of the digital world into a single massive realtime global graph of daily life on Planet Earth. From mapping global conflict and modeling global narratives to providing the data behind one of the earliest alerts of the COVID-19 pandemic, from disaster response to countering wildlife crime, epidemic early warning to food security, estimating realtime global risk to mapping the global flow of ideas and narratives, GDELT powers an ever-growing portion of the global risk analysis and forecasting landscape globally.
Yet, one of the greatest challenges in processing GDELT's planetary-scale data is its sheer scale and scope: within its realtime feeds lie everything from 24/7 updates on events and narratives across the planet to the earliest glimmers of tomorrow's biggest stories. Not even the largest teams of human analysts can examine even a fraction of GDELT's daily monitoring, meaning even the largest organizations are today only able to scratch the surface of what is possible with GDELT.
Over the years we have explored myriad approaches to cataloging GDELT's vast insights, from early grammar-based approaches to statistical, hybrid and neural models, from partitioning, parsing and distillation to more advanced architectures like Transformers. The emergence and maturation of Large Language Models (LLMs) over the past few years has fundamentally altered the state of the possible when it comes to using GDELT to understand global risk. We have been closely tracking the capabilities of these models and their unique strengths in the kinds of flexible and robust guided distillation and codification needed for news cataloging and Q&A, as well as their current limitations.
With the public availability of ChatGPT last year and the forthcoming availability of Bard and other models, LLMs have reached a developmental state where they are now widely accessible and becoming increasingly standardized in capability, with their distillation and generative abilities increasingly paired in ways that allow more robust codification, such as the compilation of tabular extractive summaries of freeform text across languages and writing styles.
We see several key areas of growth for LLMs paired with GDELT:
- Summarization. LLMs are uniquely suited for summarization tasks, such as distilling a lengthy news article into a concise and clinical abstract.
- Across-Coverage At-Scale Distillation Of Stories. An especially powerful application of LLMs comes from distilling breaking stories with high news attention. Such stories may yield thousands or even hundreds of thousands of stories in rapid succession – the overwhelming majority of which simply convey the same information repackaged in different language or contextualization. LLMs offer the unique opportunity to "look across" large volumes of coverage, discard repeated information and convey just new information or a concise summary of results. For example, with a major natural disaster, hundreds of thousands of articles may report on realtime donations of support. The majority of these articles are repeating the same basic set of countries and aid organization support, whereas an LLM could compile a realtime list of new announcements not previously reported.
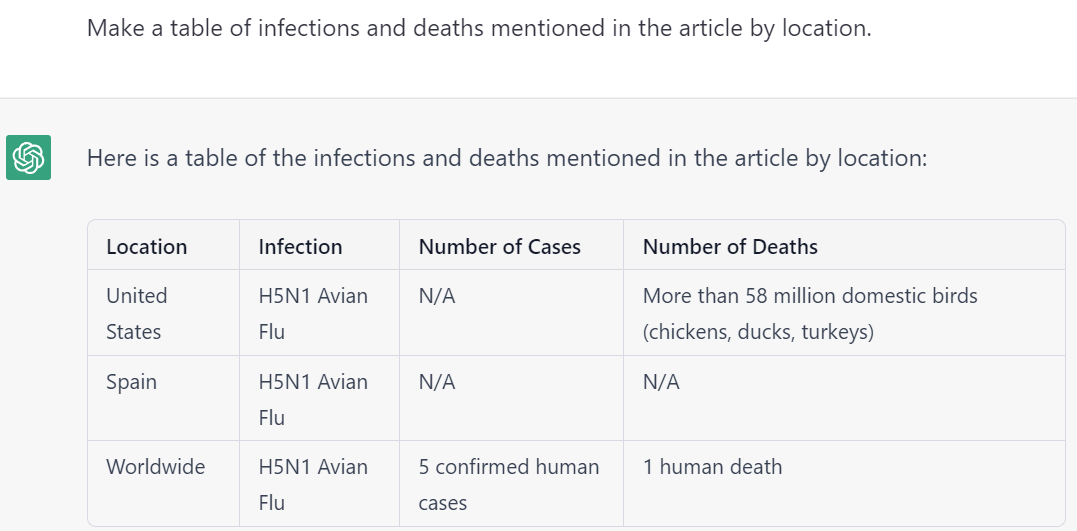
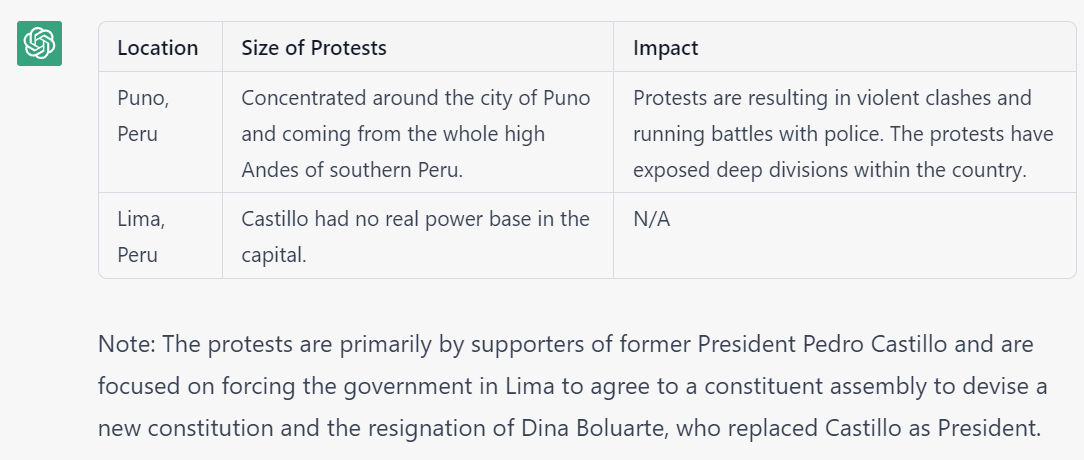
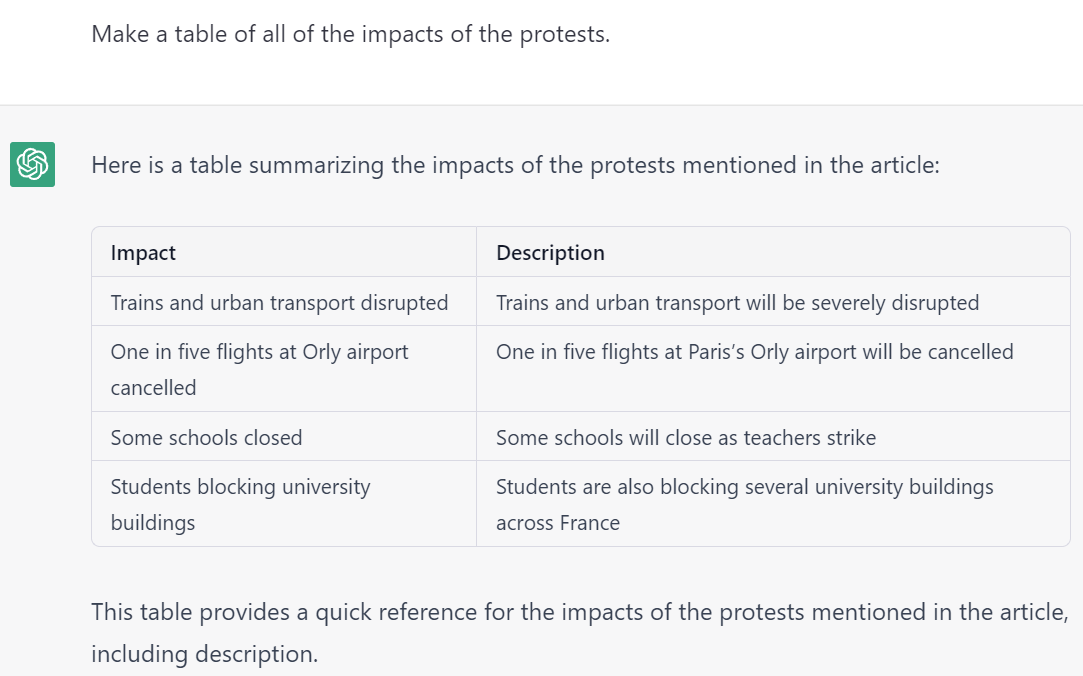
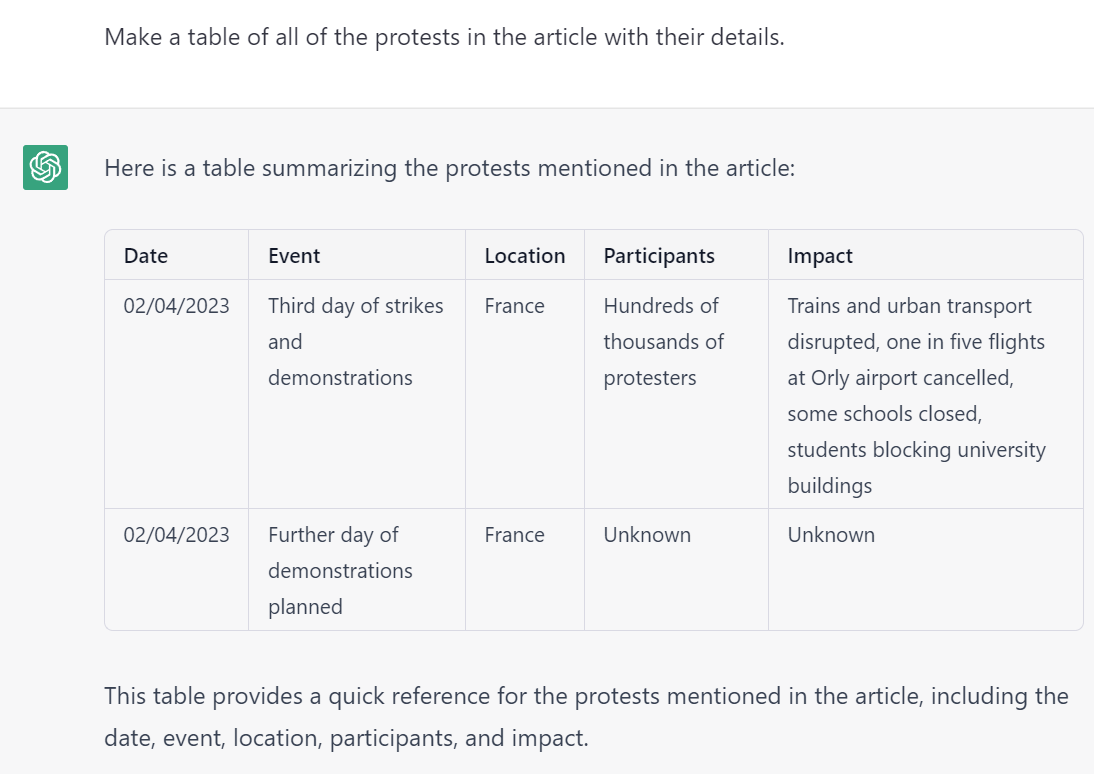
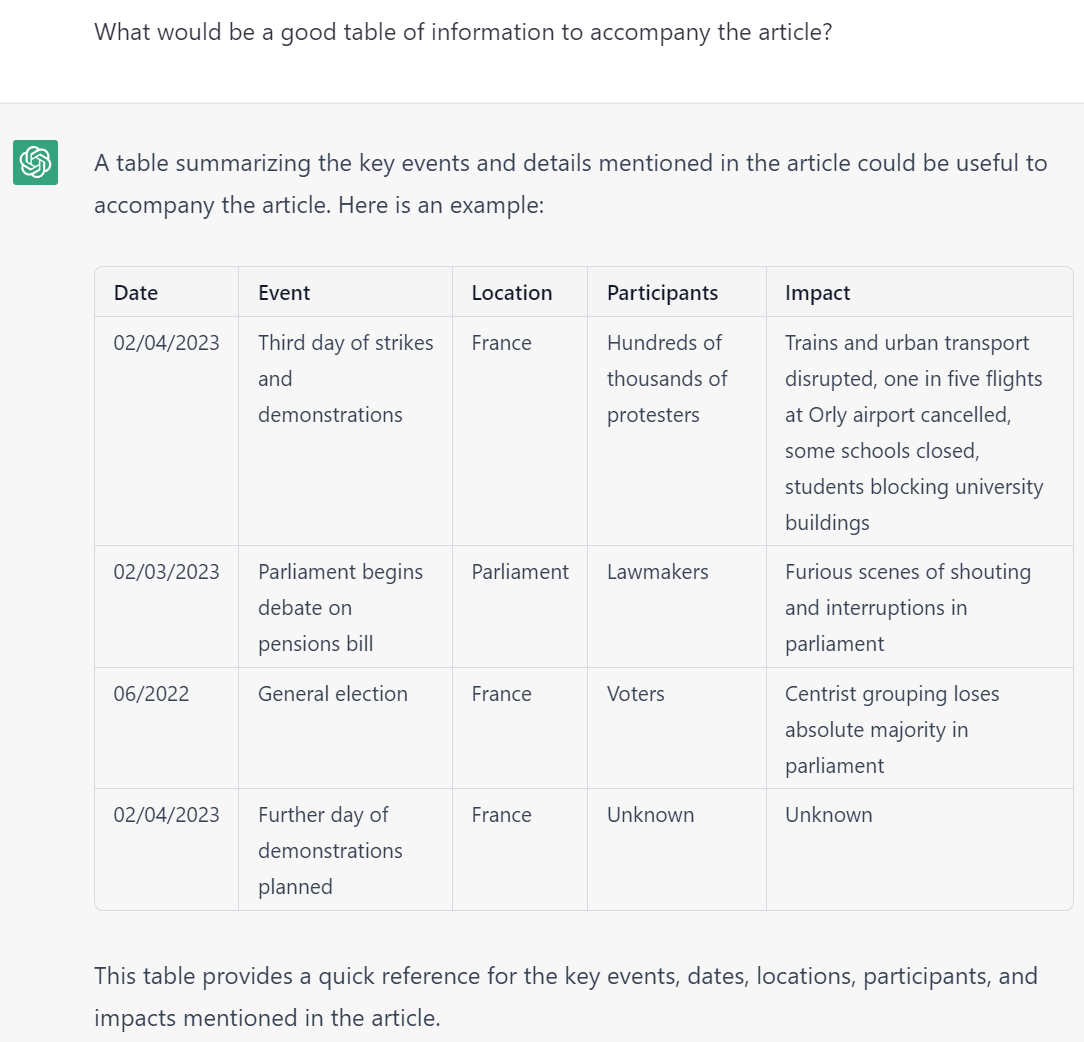
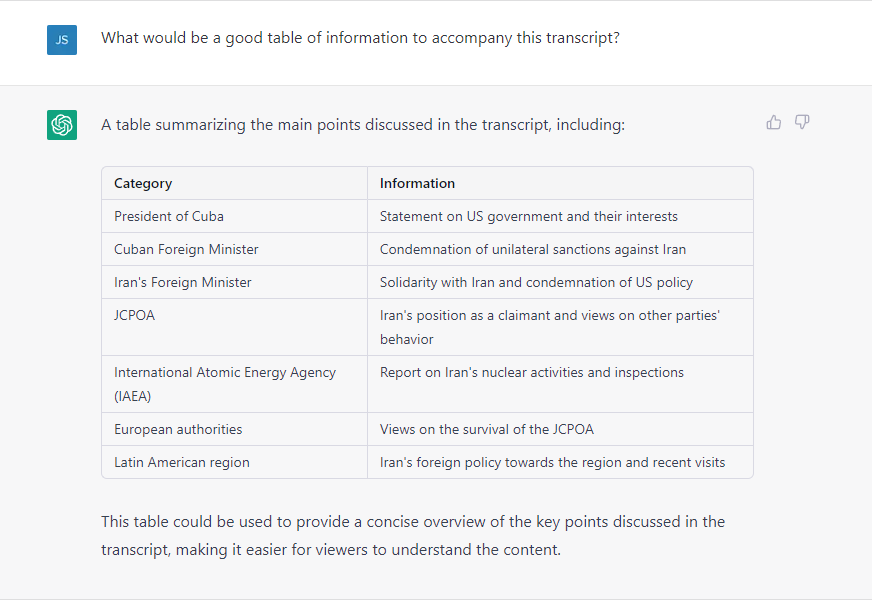
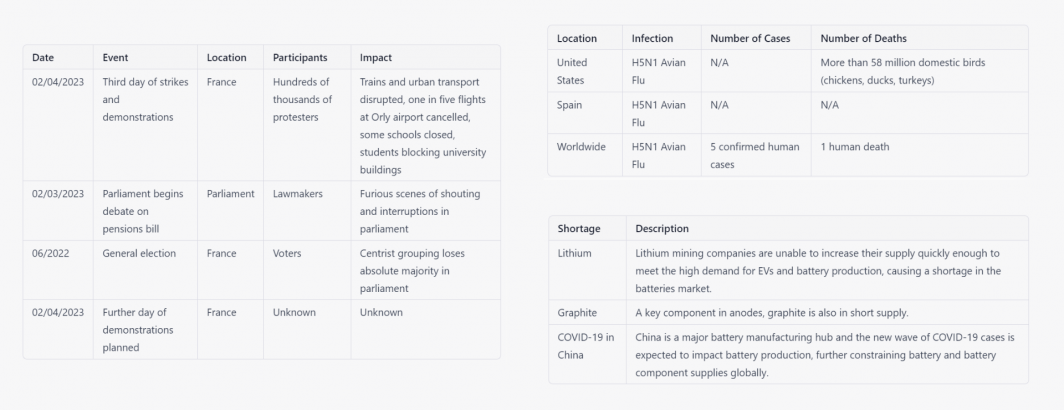
- Codification, Cataloging & Extraction. LLMs are uniquely adept at compiling textual reporting into tabular format. A key use case lies in the codification of news – such as converting news coverage of protests into a codified spreadsheet listing all of the described protests, their locations, sizes, makeup, grievances and impacts.
- Exploratory Q&A. Once a story of interest has been identified, LLMs can be used to look across vast realtime streams of information and answer basic information. For example, in a natural disaster – "what are the organizations promising medical supplies?" or "how many K9 units have been deployed?"
A typical analytic pipeline might be:
- Codification. Automated stream processing pipelines codify the firehose of global news into discrete quantified records for analysis.
- Trend Alerting. Automated systems monitor for anomalies, yielding realtime alerts, and trend summaries, presented in daily reports.
- Summarization. All coverage about a story is distilled down into a concise realtime summary, while individual articles of especial interest are similarly distilled into concise instantly digestible summaries.
- Exploration. Once a story of interest to an analyst or decision-maker is identified, exploratory interactive Q&A can be used to answer key questions and help the analyze or decision maker understand the contours of the story.
From a technical standpoint, combining GDELT's NGrams 3.0 dataset with LLMs offers the incredibly unique opportunity to perform at-scale realtime classification over global news in realtime. Our recommended workflow is as follows:
- GDELT NGrams 3.0. The NGrams 3.0 dataset is ingested in realtime, with lightweight relevancy filtering (grammar-based, statistical or "mini model" neural classifiers or embedding-based similarity) used to winnow down the full GDELT firehose to just relevant coverage. Only relevant articles are passed beyond this stage. Rather than the LLM having to process every single article, this stage is used to massively reduce the processing load on the LLM.
- Winnowing. Embeddings and/or mini models are used to filter each relevant article down to just its relevant passages. Alternatively, the full LLM or a customized summarization version can be used to summarize the article. The goal here is to further reduce the processing and attention load on the LLM. In a typical article, only a handful of sentences contain much of the detail of interest, with distillation of the article into those component passages allowing the final LLM analysis to focus its attention on that text, both improving result accuracy and comprehensiveness and dramatically reducing computational load.
- LLM Analysis. Finally, relevant text is analyzed by the LLM. This could be a single unified LLM or multiple targeted LLMs, depending on architecture and computational resources. Goals would be for the LLM to generate an article-level summarization and to distill core facts via templated stream processing pipelines.
- Trend Analysis. The codified results of the LLM analysis are then passed to at-scale trend analysis such as Timeseries Insights API and related, which yield realtime anomaly detection and overall trend structuring.
- Presentation & Q&A. When a story of interest is identified, the LLM is used to look across all of the relevant coverage to generate a unified textual and tabular summary and to support interactive Q&A with the user.
We are tremendously excited for the emerging opportunities of LLMs paired with GDELT. Below is a selection of tabular codifications compiled by ChatGPT from GDELT's datasets, both online news and Internet Archive TV News Archive-monitored television transcripts.