
Last month we demonstrated how Google's Cloud Vision API could be used to rapidly and non-consumptively annotate a Russian television news broadcast using the TV News Visual Explorer's downloadable preview image ZIP file that contains the full resolution version of the images in the thumbnail grid sampling the broadcast one frame every 4 seconds and how this could be used to track all of the Fox News clips appearing in that show. What would it look like to scale this up to five channels over an entire day?
To explore the potential for at-scale analysis of Russian television news, we analyzed all broadcasts monitored by the Internet Archive's Television News Archive from 1TV, NTV, Russia 1, Russia 24 and Russia Today that aired from midnight to midnight UTC on September 28, 2022. For each broadcast, we downloaded its non-consumptive image ZIP file and ran each frame (sampled one frame every 4 seconds) through the Google Cloud Vision API's logo detection service to compile a list of all recognized logos found in each frame.
The first step is to compile a list of all of the available shows across the five monitored Russian channels on September 28, 2022. We download the master list we compiled last week and filter for matching shows:
mkdir CACHE curl http://data.gdeltproject.org/blog/2022-tv-news-visual-explorer/VISUALEXPLORER-IDLIST-20220929.TXT -o VISUALEXPLORER-IDLIST-20220929.TXT grep -E '/(1TV_|NTV_|RUSSIA1_|RUSSIA24_|RT_)20220928' VISUALEXPLORER-IDLIST-20220929.TXT > ./CACHE/SHOWLIST wc -l ./CACHE/SHOWLIST
This yields a list of 159 distinct broadcasts, which we then download locally and unzip:
apt-get -y install parallel
apt-get -y install zip
cd ./CACHE/
time cat SHOWLIST | parallel --eta 'curl -s {} -o ./{/}'
time cat SHOWLIST | parallel --eta 'unzip -q {/}'
rm *.zip
This will result in 159 subdirectories containing a combined total of 110,287 JPEG images. We want to move all of those JPEG images into a single directory and copy them all to a temporary GCS bucket for submission to the Cloud Vision API. While the API supports submitting local images via BASE64 encoding, using GCS as a staging point simplifies the pipeline:
mkdir FRAMES
find . | grep -E '\.jpg$' | parallel --eta 'mv {} ./FRAMES/{/}'
time gsutil -m -q cp "./FRAMES/*.jpg" gs://[MYBUCKET]/
Now we submit all 110,287 images through the Cloud Vision API:
mkdir JSON
find ./FRAMES/ | grep -E '\.jpg$' > FRAMELIST
wc -l FRAMELIST
time cat FRAMELIST | parallel -j 7 --resume --joblog ./PAR.LOG --eta "[ ! -f ./JSON/{/.}.json ] && curl -s -H \"Content-Type: application/json; charset=utf-8\" -H "x-goog-user-project:[MYPROJECTID]" -H \"Authorization: Bearer $(gcloud auth print-access-token)\" https://vision.googleapis.com/v1/images:annotate -d '{ \"requests\": [ { \"image\": { \"source\": { \"gcsImageUri\": \"gs://[MYBUCKET]/{/}\" } }, \"features\": [ {\"type\":\"LOGO_DETECTION\"} ] } ] }' > ./JSON/{/.}.json"
This will submit each image to the API and write its results to a local file that contains the full raw JSON output of the API with the same filename as the original JPEG image.
Note that the Cloud Vision API defaults to a limit of 1,800 requests per minute, so you may need to adjust the "-j 7" parameter to decrease the number of parallel submissions depending on your specific project's Cloud Vision API quota or request a higher quota to submit more images faster.
Based on current Cloud Vision API pricing, the cost to scan all 110,287 images for logos is 110,287 / 1000 = 111 billable groups * $1.5 = $166.5 (see formula). Thus, scanning the total airtime over an entire day of five channels costs for every identified logo costs just $166.5.
Many frames do not contain recognizable logos or do not have logos recognized by the Cloud Vision API, so we want to move those to different directory (they will have a filesize of exactly 32 bytes):
cd JSON
mkdir ../NOLOGOS/
time find . -type f -size 32c | parallel --eta 'mv {} ../NOLOGOS/{}'
To make it easier to work with the files, we use "jq" to extract the list of logos from the JSON file and write them all to a plain text ASCII file called ".logos" for each frame, which makes it possible to grep them more easily:
apt-get -y install jq
cd JSON/
time find . | grep -E '\.json$' | parallel --eta 'cat {} | jq -r .responses[0].logoAnnotations[]?.description > {}.logos'
Now we can use that file to compile a master list of all unique logos seen across the five channels on September 28, 2022:
rm CONCAT
time find . -type f -name "*.logos" -exec cat {} + >> CONCAT
cat CONCAT | sort | uniq > LOGOS.20220928.TXT
This yields a master list of 4,377 unique logos identified by Cloud Vision:
Looking through the list we see "Volkswagen" as one of the logos:
time find . -type f -name "*.logos" | xargs grep 'Volkswagen' ./1TV_20220928_020000_Telekanal_Dobroe_utro-001290.json.logos:Volkswagen ./RT_20220928_043000_Documentary-000416.json.logos:Volkswagen ./RT_20220928_123000_Documentary-000397.json.logos:Volkswagen ./RT_20220928_203000_Documentary-000443.json.logos:Volkswagen
Sure enough, if we look at the video for that frame, we can see that it features a soldier driving a Volkswagen vehicle:

What about a television channel like CNN?
time find . -type f -name "*.logos" | xargs grep 'CNN' ./1TV_20220928_060000_Novosti-000254.json.logos:CNN ./1TV_20220928_060000_Novosti-000252.json.logos:CNN ./1TV_20220928_060000_Novosti-000253.json.logos:CNN ./1TV_20220928_060000_Novosti-000251.json.logos:CNN ./1TV_20220928_060000_Novosti-000250.json.logos:CNN ./1TV_20220928_060000_Novosti-000249.json.logos:CNN ./1TV_20220928_060000_Novosti-000248.json.logos:CNN ./RUSSIA1_20220928_143000_60_minut-000044.json.logos:CNN
The CNN logo was identified in just two broadcasts for just one segment each. In both cases, the segment was informational:

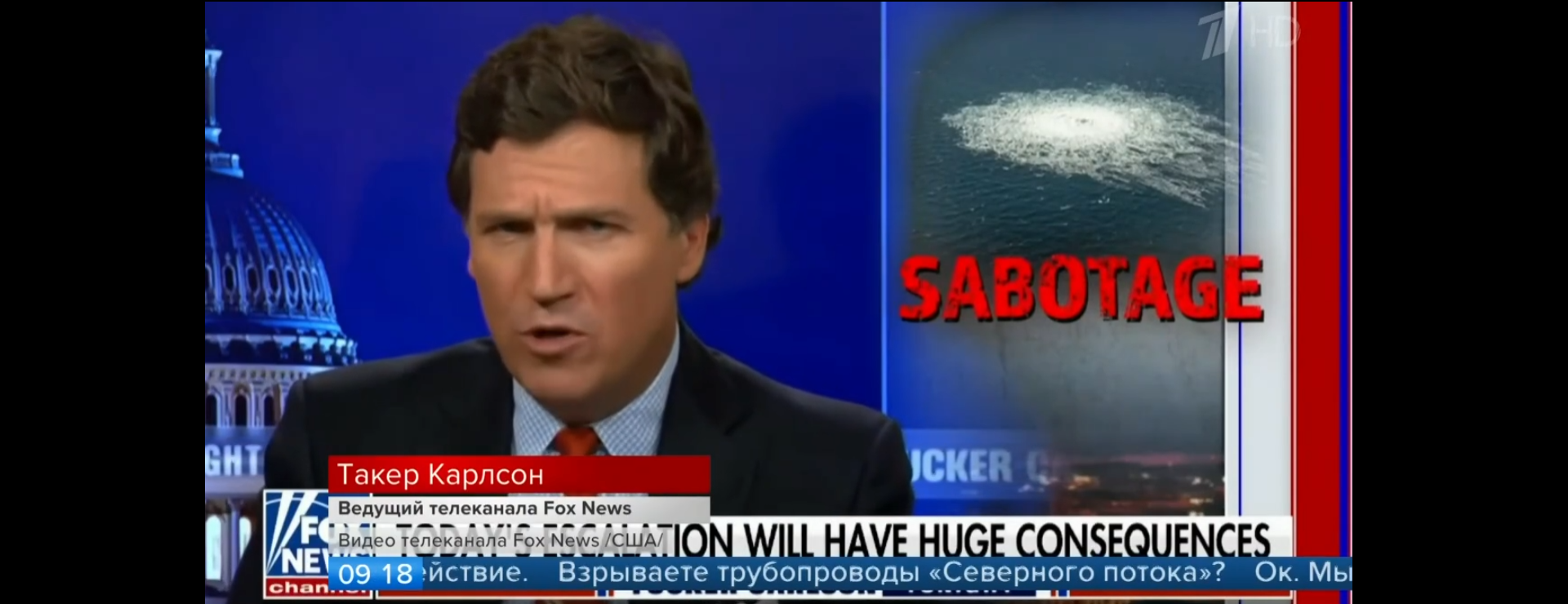
What about Fox News? In contrast to CNN, Fox News featured in 391 distinct frames, showing just how popular it is across Russian television news:
time find . -type f -name "*.logos" | xargs grep 'Fox News' > LOGOS.20220928-FOXNEWS.TXT cat LOGOS.20220928-FOXNEWS.TXT ./1TV_20220928_060000_Novosti-000299.json.logos:Fox News ./1TV_20220928_060000_Novosti-000298.json.logos:Fox News ./1TV_20220928_060000_Novosti-000297.json.logos:Fox News ./1TV_20220928_060000_Novosti-000295.json.logos:Fox News ./1TV_20220928_060000_Novosti-000296.json.logos:Fox News ./1TV_20220928_090000_Novosti-000215.json.logos:Fox News ./1TV_20220928_090000_Novosti-000218.json.logos:Fox News ./1TV_20220928_090000_Novosti-000216.json.logos:Fox News ./1TV_20220928_090000_Novosti-000217.json.logos:Fox News ./1TV_20220928_090000_Novosti-000210.json.logos:Fox News ./1TV_20220928_090000_Novosti-000211.json.logos:Fox News ./1TV_20220928_090000_Novosti-000212.json.logos:Fox News ./1TV_20220928_090000_Novosti-000214.json.logos:Fox News ./1TV_20220928_090000_Novosti-000213.json.logos:Fox News ./1TV_20220928_091500_Informatsionnii_kanal-002333.json.logos:Fox News ... ./1TV_20220928_091500_Informatsionnii_kanal-002409.json.logos:Fox News ...
You can see the complete list of all 391 matching frames:
Just from the list of the first few matches above, you can see four clips across three broadcasts, all of them from Tucker Carlson:
- 1TV: 9/28/2022 9:19:36 AM
- 1TV: 9/28/2022 12:13:56 PM
- 1TV: 9/28/2022 2:50:28 PM
- 1TV: 9/28/2022 2:55:32 PM
You can download the complete dataset, including both the raw JSON output produced by the Cloud Vision API and the parsed ".logos" version of each frame:
We'd love to see what you're able to do with this sample dataset and hope it inspires new kinds of creative applications of the downloadable ZIP files and the kinds of at-scale non-consumptive visual analyses they enable!