
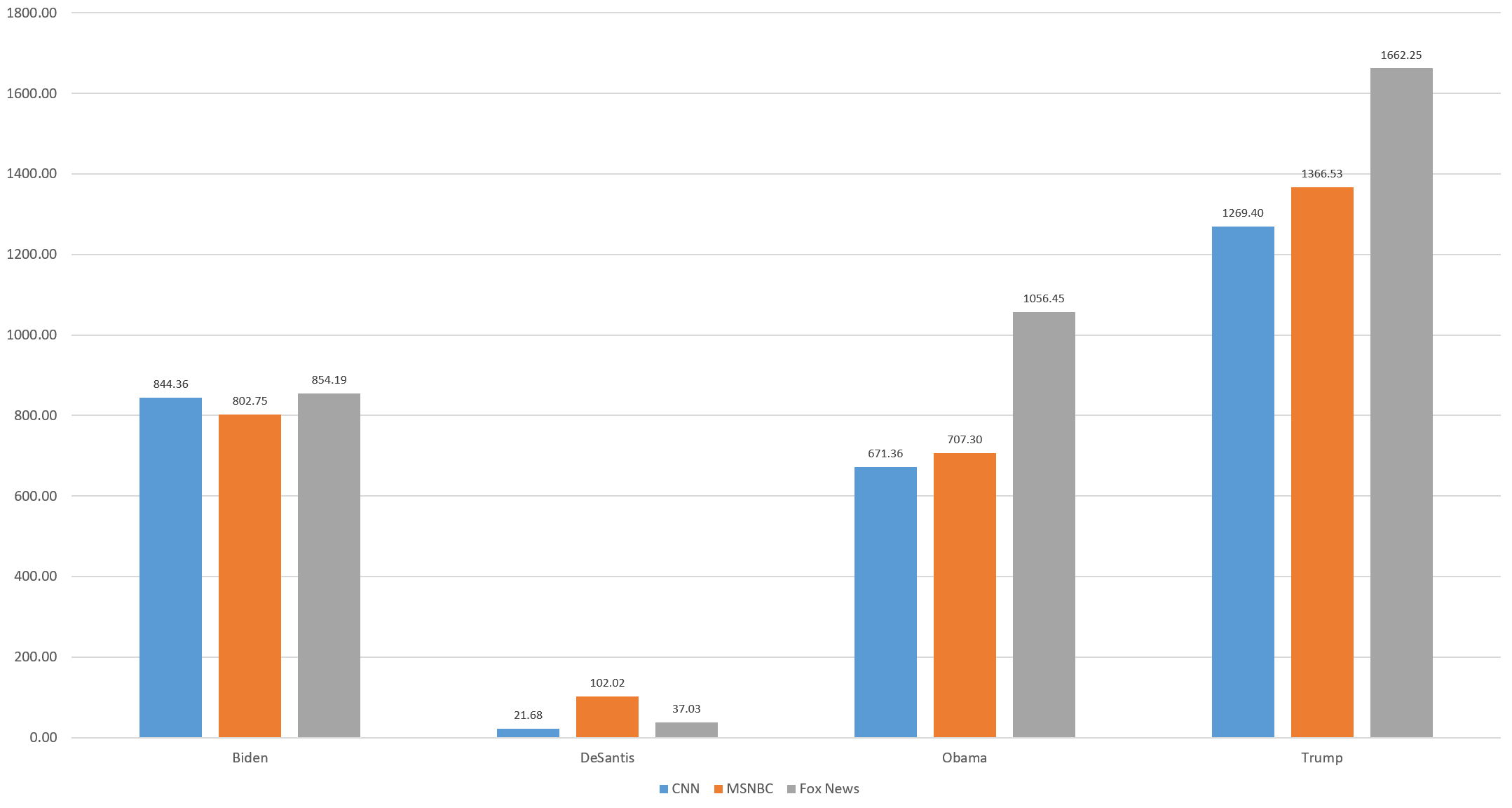
Earlier this week we unveiled a massive new catalog of every appearance of a human face across CNN, MSNBC and Fox News from June 2009 to present, compiled by analyzing 1.2 billion seconds of airtime across the three channels over the past 14 years and yielding a final catalog of of 315 million human face appearances. Today we will explore how to use this immense archive to catalog every appearance of Barack Obama, Donald Trump, Joe Biden and Ron DeSantis across those three channels since June 2009.
In total, Trump's face appeared across the three channels over the past 14 years for more than 4,298 hours. To put that in perspective, that is 179 days of 24/7 Trump if played end-to-end. Biden is second, appearing for 2,501 hours, followed by Obama at 2,435 hours and DeSantis at 160 hours. While at first glance it is surprising that Biden appeared more than Obama, despite being 2.5 years into his presidency compared with Obama's 8 years, it is important to remember that during those 14 years, Biden was vice president for 8 and president for 2.5. When comparing spoken mentions over the same time frame, Obama leads with 1.5 million to Biden's 1.1 million.
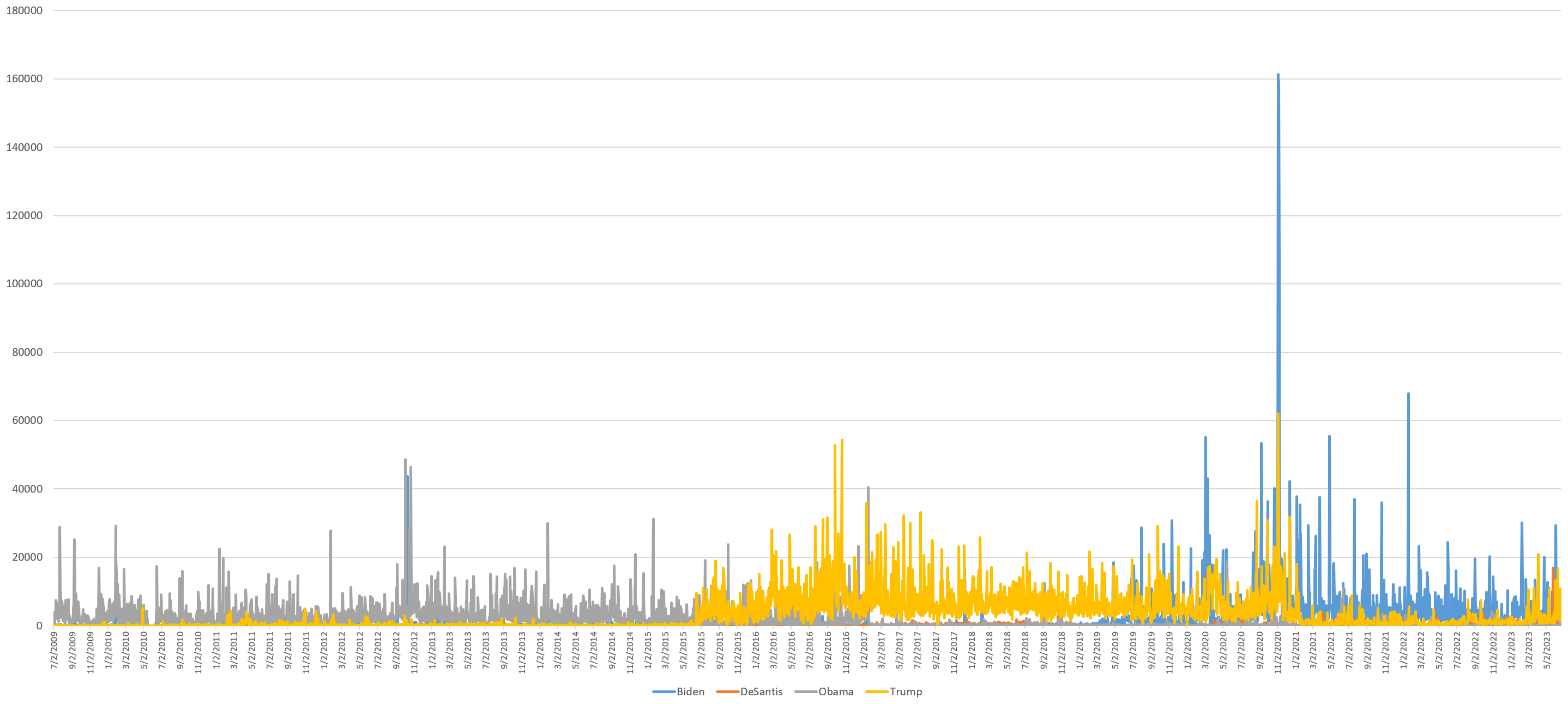
The timeline below shows the total combined seconds per day across the three channels in which each of the four men's faces were visible. Obama gives way to Trump gives way to Biden, with a year-long overlap in each case covering the campaign cycle, showing just how long the campaign process really lasts and just how much television coverage the frontrunner opponent can get. But what explains that vertical surge on November 4th, 5th, 6th and 7th, 2020? While the presidential election was held on November 3, 2020, no winner was declared that evening and until Joe Biden being declared the winner on November 7th, for four days the two men's faces were omnipresent across the three channels, with Biden receiving more coverage as the opponent.
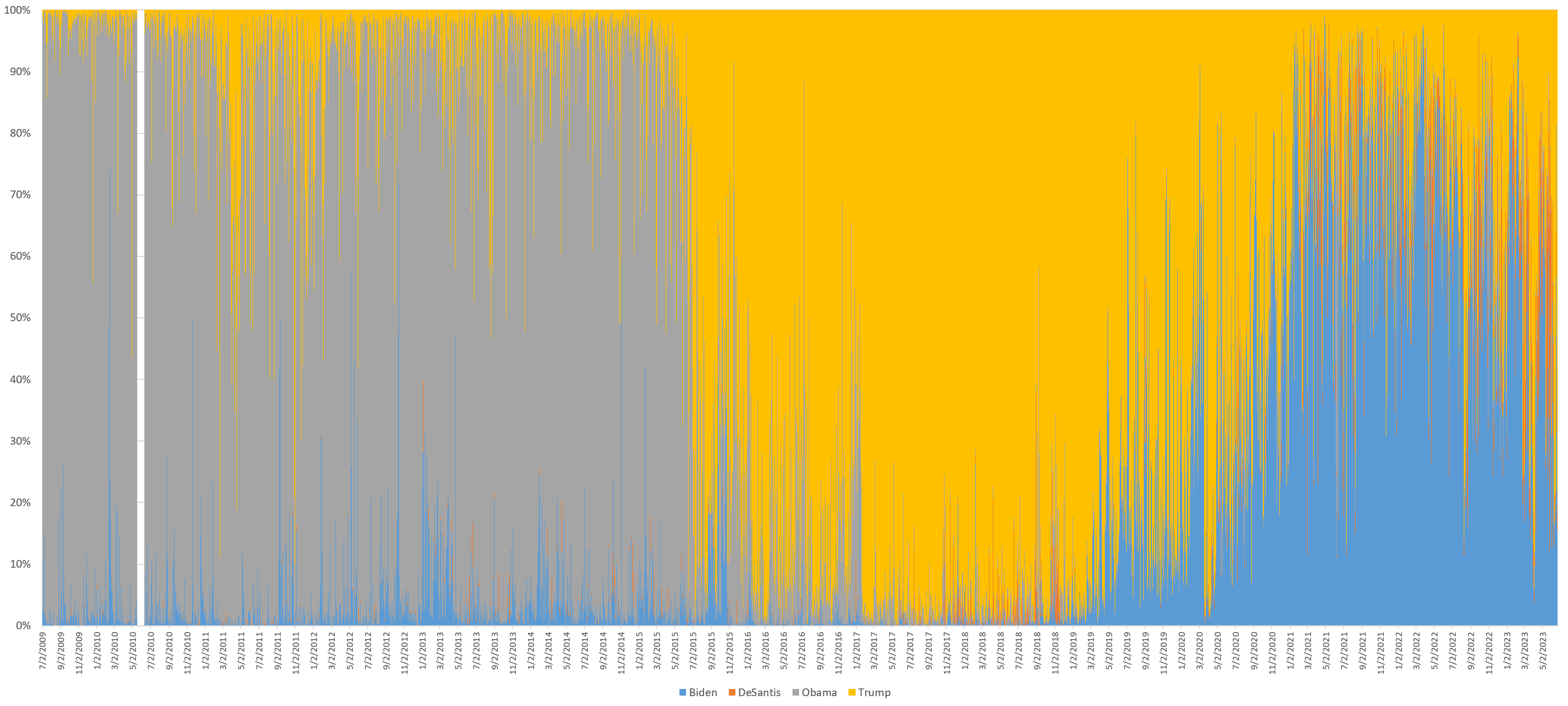
To make the results clearer, the chart below shows the same timeline, but for each day shows the percentage of all appearances that day that were each of the four men, making the breakdown between the four clearer. The gap in mid-2010 is due to missing data. Trump displaces Obama in mid-2015, onlg to be slowly cede airtime to Biden from early 2019. DeSantis
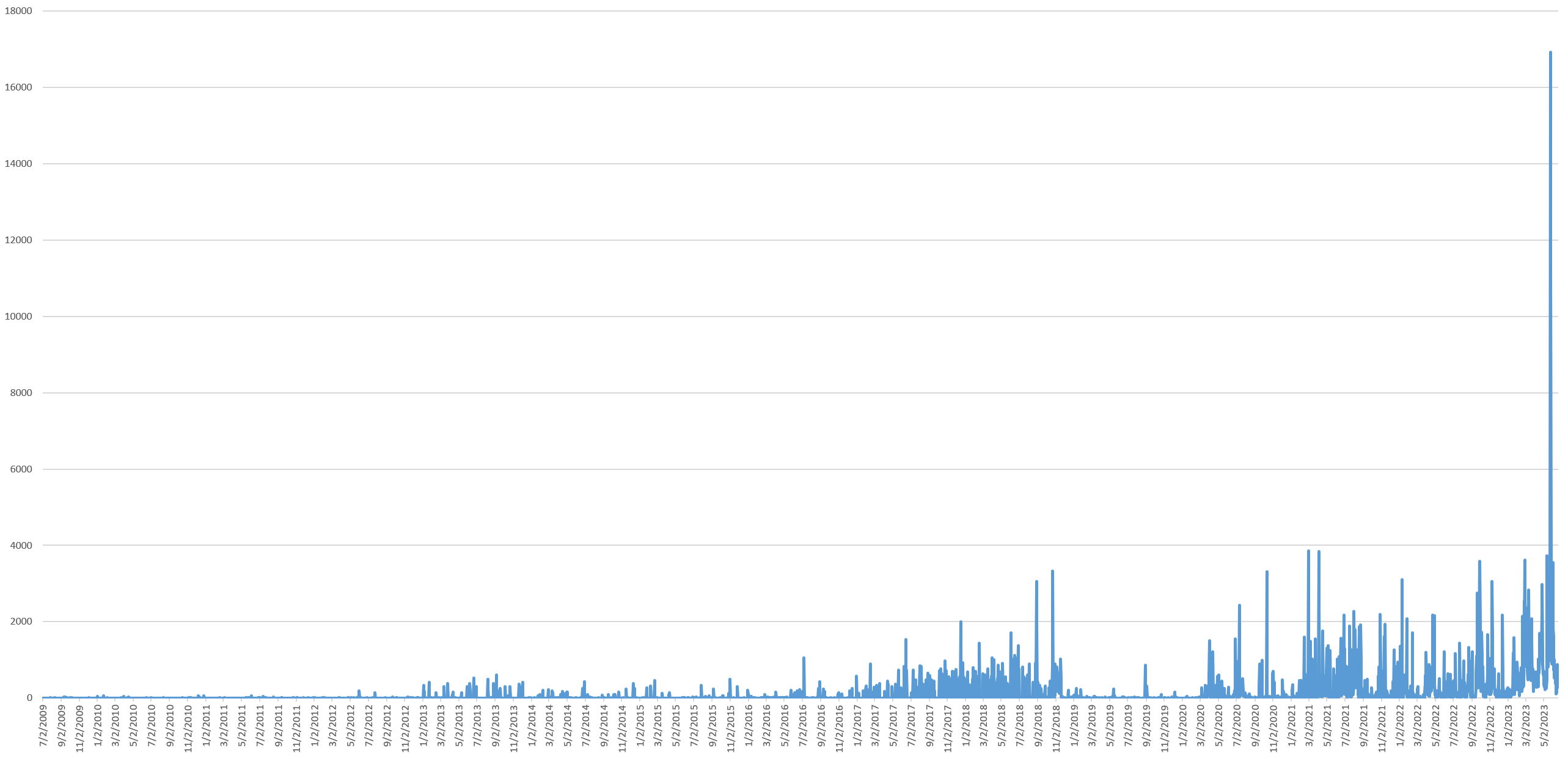
As a governor, rather than president, DeSantis has received far less coverage than the other three, so the timeline below shows only his appearances, showing a somewhat steady but bursty timeline of appearances since early 2021, with appearances becoming far more steady since February of this year.
Technical Details
For those interested in how we created the timelines above, here is the complete workflow. We ran this workflow on a GCE 64-core high-memory N1 VM with 400GB of RAM with half allocated as a RAM disk and running standard Debian.
First we'll install a couple of dependences:
apt-get -y install parallel apt-get -y install wget apt-get -y install python3 apt-get -y install python3-pip pip3 install argparse pip3 install numpy
Then we'll create our directory structure and download the search script:
mkdir /dev/shm/EMBED mkdir /dev/shm/EMBED/KNOWNFACES/ mkdir /dev/shm/EMBED/MATCHES/ mkdir /dev/shm/EMBED/COUNTS/ cd /dev/shm/EMBED/ wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/search_faceembeddings.py chmod 755 ./search_faceembeddings.py
Using our precomputed Public Figures Embedding Database, we'll download the signatures for Barack Obama, Donald Trump, Joe Biden and Ron DeSantis:
cd /dev/shm/EMBED/KNOWNFACES/ wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/faceembeddb/DonaldTrump.json wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/faceembeddb/JoeBiden.json wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/faceembeddb/BarackObama.json wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/faceembeddb/RonDeSantis.json
If you want to search for other people, you'll have to follow the instructions to install the Face Embedding Server and related infrastructure. Note that computing custom face embeddings is far more complex and involved.
Given the enormous volume of facial signatures to be searched (315 million), we'll use a helper script to wrap the search pipeline so that we can simply call a bash script for any given channel and date range:
cd /dev/shm/EMBED/ wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/scanchannel_faceembeddings.sh chmod 755 ./scanchannel_faceembeddings.sh
This script encapsulates our standard search workflow of downloading the VE inventory files for a given channel and date range, compiling the list of showids from those inventories, then downloading the face signature catalogs for those shows, then running the search, then finally cleaning up all of the temporary files in the end. It accepts four parameters: CHANNEL, STARTDATE (YYYYMMDD) ENDDATE (YYYYMMDD) OUTPUTSUFFIX (for the matches to be written to).
Running it is as simple as:
cd /dev/shm/EMBED/ #run with progress written to stdout/stderr: time ./scanchannel_faceembeddings.sh MSNBC 20220101 20220131 202201.MSNBC 0.52 #alternatively, run while piping the logging info to /dev/null time ./scanchannel_faceembeddings.sh MSNBC 20220101 20220131 202201.MSNBC 0.52 > /dev/null 2> /dev/null&
Despite being only 128-dimension vectors, the enormous size of the embedding database means that a single year of embeddings for CNN, MSNBC and Fox News combined can require 70-80GB of disk. Since we are using a RAM disk here to minimize IO delay, that means we can quickly exhaust the 200GB allocated to our RAM disk. Thus, we'll process the full 14-year 3-channel archive by splitting it into month-channel chunks and processing 50 chunks in parallel, which just barely fits into our 200GB RAM disk:
cd /dev/shm/EMBED/
rm MONTHS; start_date="200906"; stop_date="202306"; current_date=$start_date; while [[ $current_date -le $stop_date ]]; do echo $current_date; current_date=$(date -d "${current_date}01 + 1 month" +%Y%m); done > MONTHS
rm CMDS
cat MONTHS | parallel -j 1 'echo CNN {}01 {}31 {}.CNN >> CMDS'
cat MONTHS | parallel -j 1 'echo MSNBC {}01 {}31 {}.MSNBC >> CMDS'
cat MONTHS | parallel -j 1 'echo FOXNEWS {}01 {}31 {}.FOXNEWS >> CMDS'
wc -l CMDS
time cat CMDS | parallel --eta -j 50 --colsep ' ' "./scanchannel_faceembeddings.sh {1} {2} {3} {4} 0.52 > OUT.LOG 2> ERR.LOG"
The code above starts by compiling a list of months in YYYYMM format from June 2009 to June 2023 and outputs them to a file called MONTHS. Then it uses those months and constructs at list of channel-months to process and writes them to CMDS. Note that if you look closely above, for each month it appends "01" to STARTDATE and "31" to ENDDATE so that the month "200906" becomes "20090601" and "20090631". Even though many months don't have 31 days, this automatically stops with the last day of each month, but using "31" as the last day for each month saves us the trouble of trying to compute per-month ends with leap years, etc. Then, the complete set is run in parallel.
When this completes, the "./MATCHES/" subdirectory will be filled with one JSON file per channel per month containing all of the appearances of the four public figures we searched for on that channel in that month in the format like "MATCHES.202306.CNN.json". Each row represents an appearance of a face in a given frame and its confidence (lower numbers mean a stronger match since the actual metric is the "distance" from the given face to the known face). For example, this tells us that Joe Biden was seen in frame 47 of this episode of Wolf Blitzer:
{"face": "JoeBiden", "id": "CNNW_20230605_210000_The_Situation_Room_With_Wolf_Blitzer-000047", "dist": 0.1954778659863318}
Remember that using the "&frame=" URL parameter you can view this specific appearance in the Visual Explorer by taking the "id" up to the dash mark at the end as the "id=" in the URL and the 6-digit number following the dash as the frame as in:
https://api.gdeltproject.org/api/v2/tvv/tvv?id=CNNW_20230605_210000_The_Situation_Room_With_Wolf_Blitzer&frame=000047
You can see what this looks like in the Visual Explorer.
Matches of all four men are interspersed together in each file. To break them out into 12 separate files (one file for each of the four candidates across each of the three channels:
grep --no-filename '"face": "JoeBiden"' MATCHES/MATCHES.*.CNN.json > CNN-200906-202306-JoeBiden-match.json grep --no-filename '"face": "JoeBiden"' MATCHES/MATCHES.*.MSNBC.json > MSNBC-200906-202306-JoeBiden-match.json grep --no-filename '"face": "JoeBiden"' MATCHES/MATCHES.*.FOXNEWS.json > FOXNEWS-200906-202306-JoeBiden-match.json grep --no-filename '"face": "BarackObama"' MATCHES/MATCHES.*.CNN.json > CNN-200906-202306-BarackObama-match.json grep --no-filename '"face": "BarackObama"' MATCHES/MATCHES.*.MSNBC.json > MSNBC-200906-202306-BarackObama-match.json grep --no-filename '"face": "BarackObama"' MATCHES/MATCHES.*.FOXNEWS.json > FOXNEWS-200906-202306-BarackObama-match.json grep --no-filename '"face": "DonaldTrump"' MATCHES/MATCHES.*.CNN.json > CNN-200906-202306-DonaldTrump-match.json grep --no-filename '"face": "DonaldTrump"' MATCHES/MATCHES.*.MSNBC.json > MSNBC-200906-202306-DonaldTrump-match.json grep --no-filename '"face": "DonaldTrump"' MATCHES/MATCHES.*.FOXNEWS.json > FOXNEWS-200906-202306-DonaldTrump-match.json grep --no-filename '"face": "RonDeSantis"' MATCHES/MATCHES.*.CNN.json > CNN-200906-202306-RonDeSantis-match.json grep --no-filename '"face": "RonDeSantis"' MATCHES/MATCHES.*.MSNBC.json > MSNBC-200906-202306-RonDeSantis-match.json grep --no-filename '"face": "RonDeSantis"' MATCHES/MATCHES.*.FOXNEWS.json > FOXNEWS-200906-202306-RonDeSantis-match.json
You can download the final set of match files:
wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/CNN-200906-202306-BarackObama-match.json wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/CNN-200906-202306-DonaldTrump-match.json wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/CNN-200906-202306-JoeBiden-match.json wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/CNN-200906-202306-RonDeSantis-match.json wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/FOXNEWS-200906-202306-BarackObama-match.json wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/FOXNEWS-200906-202306-DonaldTrump-match.json wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/FOXNEWS-200906-202306-JoeBiden-match.json wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/FOXNEWS-200906-202306-RonDeSantis-match.json wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/MSNBC-200906-202306-BarackObama-match.json wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/MSNBC-200906-202306-DonaldTrump-match.json wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/MSNBC-200906-202306-JoeBiden-match.json wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/MSNBC-200906-202306-RonDeSantis-match.json
You can also tally up the total number of faces examined (useful if you are only looking at a subset of dates:
cd /dev/shm/EMBED/COUNTS/
awk '{sum += $1} END {print sum}' COUNTS.*
To make the timelines above, we used a Perl script to collapse the results into a fixed timeline:
wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/faceembeddings_maketimeline.pl
chmod 755 faceembeddings_maketimeline.pl
time find *-match.json | parallel './faceembeddings_maketimeline.pl {}'
That's all there is to it! We hope this inspires you to think about new ways of using this massive new dataset to understand who is telling the news each day.