GDELT combines extreme globalized scale, a geographically distributed footprint across all of GCP's datacenters worldwide, a combination of all-regions hyperscale distributed compute and stream processing on GCE with GCP's APIs and analytics services, extreme data movement and an incredible diversity of input sources, spanning multiple general and specialized crawler fleets and stream and batch ingest fleets distributed across the world. We field a lot of questions about our architectures and lessons learned, so as part of our "Behind The Scenes" series we regularly post glimpses into the world that powers GDELT.
Today's glimpse is a few minutes in the life of one of our video ingest VMs on GCE that is part of a small handful of nodes responsible for ingesting television news MPEG historical backfile streams for processing from one of our collaborating institutions. Each node is a c2-standard-4 GCE instance running 45 ingest processes. Each process is a simple script that connects to a central queue server, receives a task order with connection and other information, performs a series of validation checks, ingests the MPEG stream to GCS, runs post verification to ensure the transfer completed successfully and loops to receive its next task order. The specific choice of 45 processes is based on extensive manual fine-tuning that ensures the VM achieves performance saturation: fewer processes do not fully utilize the VM, while additional processes reduce performance and increase instability due to oversaturation.
The ingest VMs are physically located in GCP data centers closest to the source data center to maximize ingest rates and then transferred over GCP's backbone to the GCS US multiregion for storage, where it is then accessed by a separate processing fleet that performs various kinds of compute on it and is additionally submitted to various GCP AI APIs for processing.
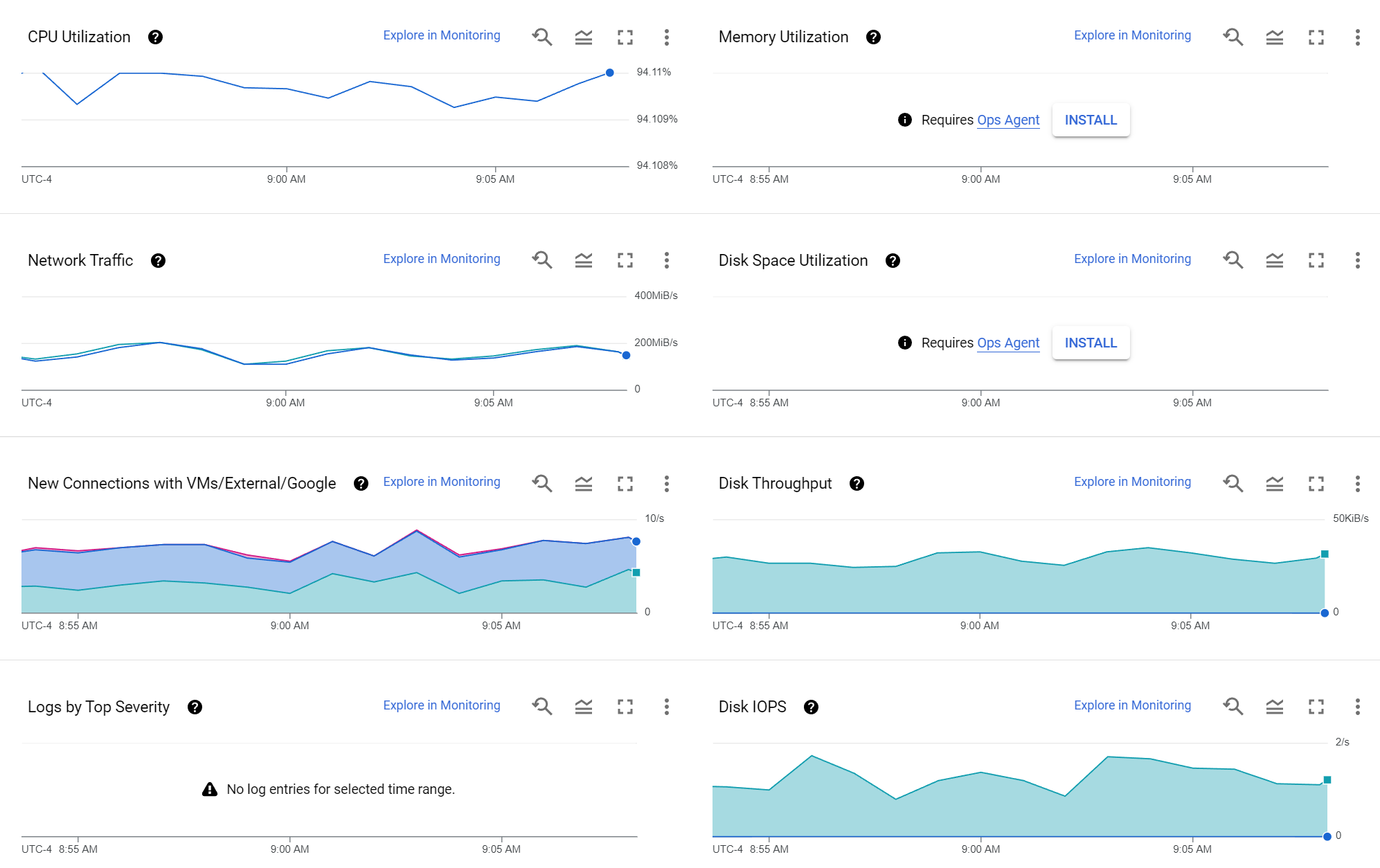
You can see a ~5 minute snapshot of its workload this morning via the Observability console below. CPU utilization varies by just 0.01% at around 94% (in reality, this is actually around 99% as reported by the kernel). Each actual download is performed via CURL -> MBUFFER -> GCS, so the VM essentially acts as a proxy border node, just ingesting data and routing it to GCS without anything touching local disk. You can see this below in the disk graphs showing just 2 IOPS and around 30KiB/s throughput from the ingest processes' local diagnostic logging that is used to flag when the VM's local network stack becomes unstable and reboots the node.
The network traffic graph shows that ingest and egress are perfectly matched as is expected due to the node's function as a streaming proxy. Remarkably, they vary fairly consistently between 150MiB/s and 200MiB/s in each direction (300MiB/s and 400MiB/s bidirectionally). While this is substantially below a c2-standard-4's maximum sustained external ingress and egress caps, that is due to the system being CPU-limited with all of the GCS streaming write overhead, but is still impressive given that each node is stream writing 45 MPEG streams in parallel to the GCS US multiregion at any given moment, meaning that scaled across multiple nodes, this architecture can achieve significant ingest performance that is limited only by the source data center's disk and networking capacity, with close coordination to avoid network link saturation.