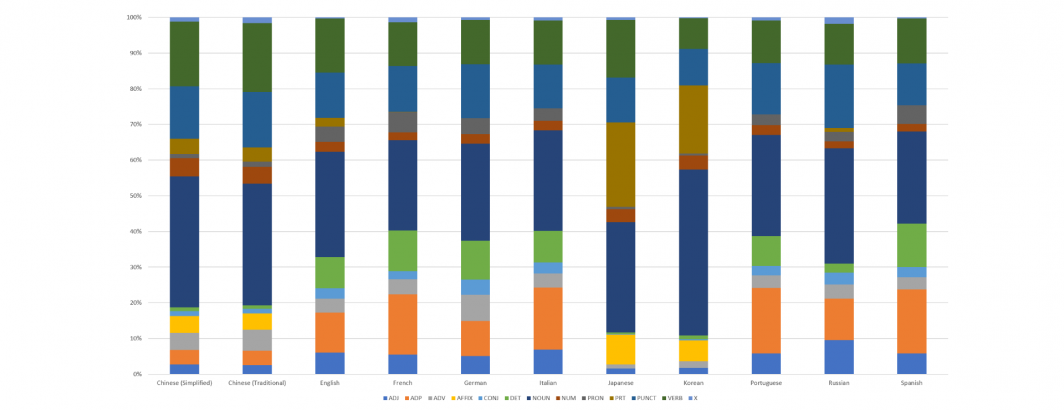
In January, we visualized one week's worth of the part of speech distribution of the 11 languages annotated by Google's Natural Language API that make up GDELT's Web Part Of Speech dataset: Chinese (Simplified), Chinese (Traditional), English, French, German, Italian, Japanese, Korean, Portuguese (Brazilian & Continental), Russian and Spanish. Looking across these languages, what does the overall part of speech distribution look like in such a multilingual world?
The hierarchical chart below shows the overall distribution across the 11 languages over the period January 17, 2020 through present. Despite covering a third of a year of global news coverage, compiling this graph took a single SQL query in BigQuery just 3 seconds to create!
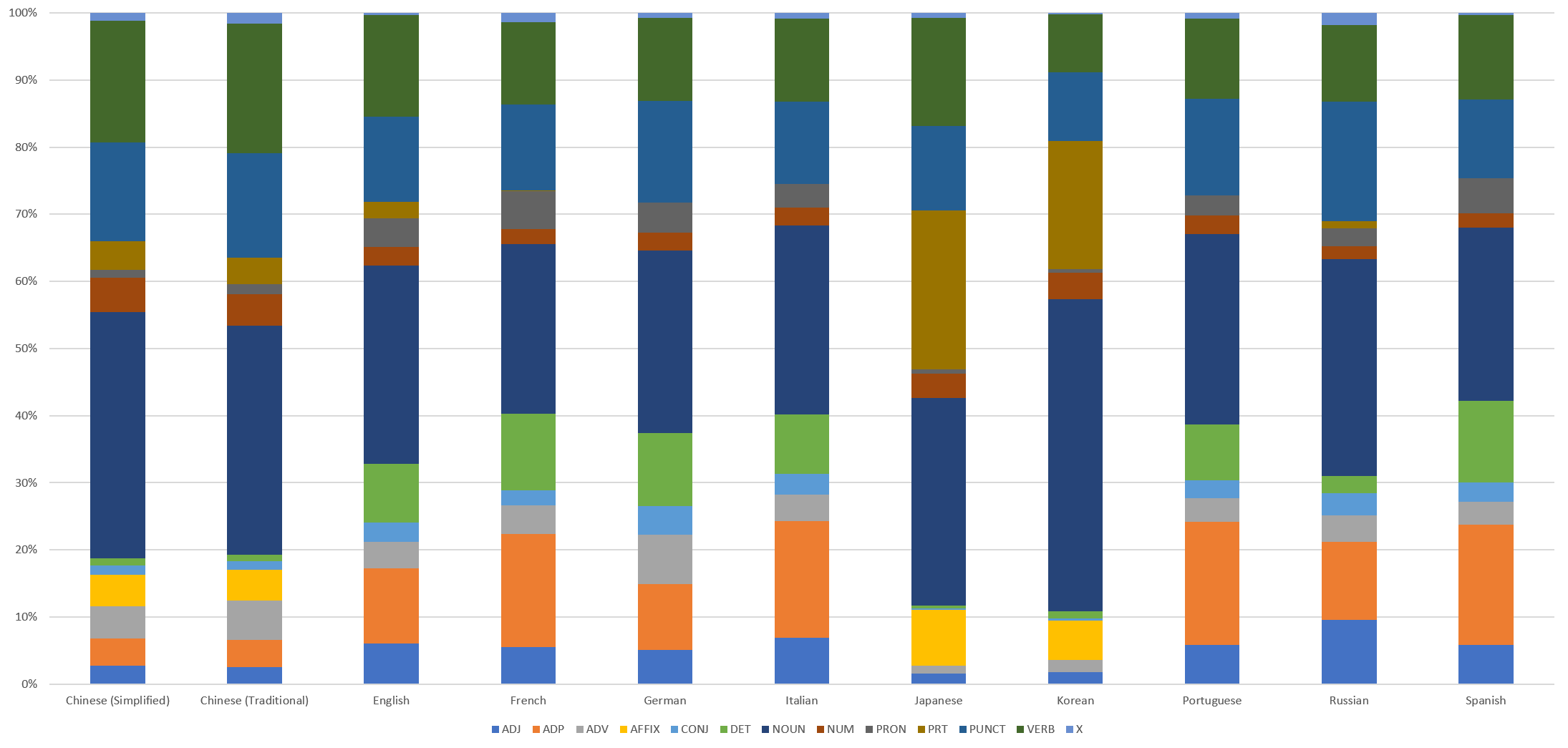
TECHNICAL DETAILS
Compiling the chart above took just a single line of SQL:
select lang, posTag, sum(count) count FROM `gdelt-bq.gdeltv2.web_pos` where DATE(dateTime) >= "2020-01-17" group by lang, posTag order by lang asc, posTag asc