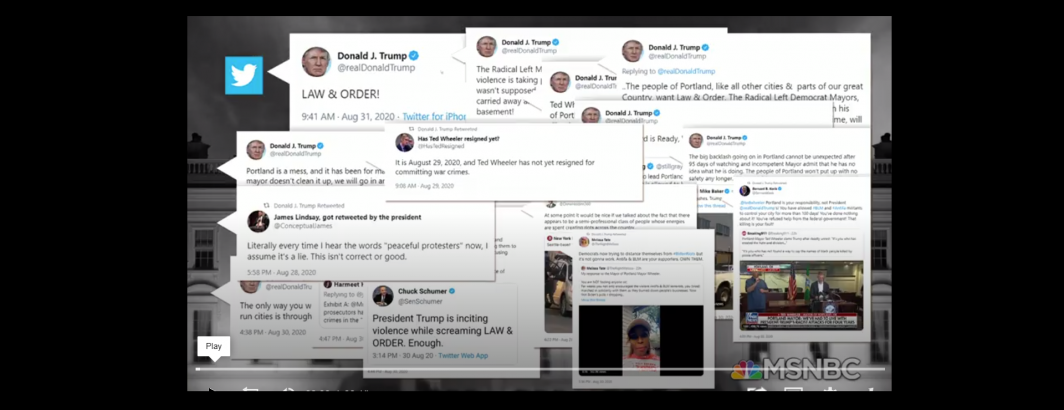
Twitter has become a primary communications medium for world leaders, with US President Donald Trump famously relying on the platform to issue a daily stream of statements and policy prescriptions. These tweets can drive the news cycle, being republished and commented on endlessly on television news. Last month we showed how we can visualize the almost hourly appearances of Trump’s tweets on a selection of national television news channels over the course of this year. What if we could go a step further and actually tie each onscreen appearance of a tweet back to the actual tweet ID, allowing researchers to understand which specific tweets got the most attention on television news?
What would it look like to scan television news using computer vision to identify every onscreen appearance of a tweet and connect it back to the actual tweet ID of the tweet in question? Understanding the interplay of social and mainstream media would open the door to a huge array of new research questions involving how social media drives mainstream coverage and can even short circuit traditional editorial processes like agenda setting. Increasingly, official government announcements, including public health policies, are being announced by tweet, with mainstream media republishing those tweets as government policy statements. How are these statements being covered on television media? What happens when social media platforms flag a post as disputed, does that decrease coverage or backfire and lead to additional news attention beyond what would have been otherwise expected? These are just some of the questions that become explorable once we connect social and television media.
How might we tractably search television news for tweets? Given that tweets are often displayed alongside the user's Twitter handle, what if we simply searched the OCR'd onscreen text of each second of airtime for Twitter handles and then searched that text against the tweets made by that user?
With the support of the Media-Data Research Consortium’s (M-DRC) Google Cloud COVID-19 Research Grant “Quantifying the COVID-19 Public Health Media Narrative Through TV & Radio News Analysis,” we have used Google’s Cloud Video AI API to non-consumptively analyze the entirety of television news programming since Jan. 1, 2020 on BBC News London, CNN, MSNBC and Fox News, including using OCR to transcribe all of their onscreen text second by second. The complete open dataset of these non-consumptive machine annotations, along with annotations for ABC, CBS and NBC evening news broadcasts since 2010, are available as the Visual Global Entity Graph 2.0 (VGEG).
To explore the idea of scanning television news for tweets, we conducted a pilot analysis involving tweets by Donald Trump and Joe Biden given their outsized potential influence in setting the news agenda, especially around public health issues like COVID-19. From the VGEG 2.0 dataset we extracted the onscreen text of CNN, MSNBC and Fox News from Jan. 1 of this year through midday Sept. 4 and searched it for all mentions of the two candidate's Twitter handles. Using an archive of Donald Trump's tweets since 2015 from the Trump Twitter Archive website we used an automated approach to link each onscreen tweet appearance with the actual tweet in question, while for the much smaller number of Biden tweets we manually connected them.
The end result is a second-by-second chronology of airtime across CNN, MSNBC and Fox News this year displaying tweets from either candidate, with the onscreen appearance connected back to the actual tweet!
Some important caveats to this dataset:
- Only tweets credited to "@realDonaldTrump" are included. Particularly high-profile tweets may simply be credited to "President Trump" or "Trump" without any mention that they originated on Twitter, meaning at best the numbers here are substantial undercounts.
- Other than the single manually added tweet mentioned above, video tweets without textual captioning/commentary in the tweet itself are ignored. Tweets that are less than 25 alphanumeric characters in length with hyperlinks removed are also ignored, as are tweets that are only a link. This means tweets like “LAW & ORDER” are ignored here, since that text can appear inside other tweets and is difficult to uniquely distinguish from onscreen text alone.
- Some deleted tweets may not be included if they were not archived in the Trump Twitter Archive.
- Only tweets sent, retweeted or linked by @realDonaldTrump are included. Tweets sent by other Trump family members or sent to the president are not analyzed here.
- Only tweets sent on or after Jan. 1, 2015 are included. This will miss onscreen appearances of tweets sent in previous years, but these are typically far rarer.
- Only a single tweet per second of airtime will match. This means collages of multiple tweets will yield only a single match. Most importantly, this also means that tweet storms or longer messages broken across multiple individual tweets will yield only a single tweet match and thus threads of tweets will need to be manually connected together from the individual tweet matches in this dataset.
You can download the datasets here:
With the caveats above in mind, we're tremendously excited to see what researchers are able to do with this pioneering new dataset. Most importantly, we hope this small experiment inspires a new way of thinking about the social-mainstream divide and leads to further research in automated scanning of television news for onscreen display of social media posts.
TECHNICAL DETAILS
Using the following query, we selected all 109,652 seconds of airtime as of midday Sept. 4 in which President Trump’s Twitter handle was displayed on screen:
SELECT date, station, showName, iaShowId, iaClipUrl, OCRText FROM `gdelt-bq.gdeltv2.vgegv2_iatv` WHERE DATE(date) >= "2020-01-01" and (LOWER(OCRText) like '%realdonald%' OR LOWER(OCRText) like '%donald j. trump retweeted%') order by date asc
His full social media handle “@realDonaldTrump” is shorted to “realdonald” here to match a common OCR error that splits the handle into two words “@realDonald Trump”. Retweets by the president are typically displayed by Twitter as “Donald J. Trump retweeted” and thus are separately included in the search above.
We then downloaded an archive of his tweets since 2015 from the Trump Twitter Archive website. This archive contains the majority of his tweets, though some deleted tweets may be missing.
To connect the two datasets, we used the following algorithm (see the PERL script for the full algorithm):
- All tweets from the Trump Twitter Archive published from Jan. 1, 2015 through midday Sept. 4, 2020 were loaded into memory. If the tweet is a retweet, the “RT: “ string is removed from the start of the tweet. All hyperlinks are also removed from the tweet and it is lowercased using standard Unicode lowercasing rules. All characters other than a-z and 0-9 are removed, including all spaces and punctuation (it was observed that the majority of OCR errors were centered around punctuation and spacing). If the resulting minimize tweet is less than 25 characters in length, it is discarded. This prevents very short tweets, such as one or two-word tweets, from matching, but also prevents high numbers of false positives where a one-word tweet is found within large numbers of other tweets.
- One now-partially-deleted tweet (“Terrified Todler [sic] runs from racist baby”) in which the video was subsequently removed, while the tweet itself remains, was manually added to the dataset. In this case the text of the tweet appears in a faux chyron in the video and not as part of the actual tweet text and thus otherwise would have been ignored. This is an important caveat to this data – most video tweets (except those with a textual tweet caption) are not counted here.
- The OCR airtime data from the Visual Global Entity Graph 2.0 (VGEG) is loaded. Each second's onscreen text is first compared to that of the previous airtime second using word-based cosine similarity. A match above 70% similarity will treat the line as the same as the previous line and copy its tweet match (if any) and move on to the next airtime second.
- If the onscreen text is substantially different from the preceeding second, each of the tweets sent in 2020 is compared to the airtime second. A cutoff ensures that only tweets sent prior to the airtime second are considered (thus, an airtime second on June 1 won’t match a tweet sent July 20). Each tweet from the start of Jan. 1, 2020 is compared against the airtime second in order until an exact match is found. The first exact match is recorded and the system moves to the next airtime second. If no exact match is found, the lowercased tweet (with all punctuation removed) is broken into words using space boundaries and compared against the onscreen airtime second. If at least 90% of the tweet’s words are found onscreen, it is added to a candidate match list, along with the percentage of its words that matched. After processing all 2020 tweets sent prior to the airtime second, the tweet with the highest overlap is selected. In the case of multiple tweets with the same percent match, the first is selected.
- If no 2020 tweets had greater than 90% of their words appear in the second of airtime, the system repeats the process for tweets sent from Jan. 1, 2015 through Dec. 31, 2019. If no match is found after all of this, the airtime second is recorded in the “No Matches” file. Otherwise, the match is recorded in the “Matches” file.
In all, of the 109,652 seconds of airtime referencing @realDonaldTrump in the onscreen text, 87,816 seconds yielded a match and 20,757 did not. Of the matching seconds of airtime, 1,079 occurred during the precise second between programs, such as MSNBC transitioning from its 4PM to its 5PM show. Since the VGEG counts each program separately, this yields two entries for the same second – we drop the second match since it is duplicative for these purposes.
For Joe Biden, the OCR process appears to have frequently split his social media handle "@JoeBiden" into "@Joe" and "Biden" (similar to how "@realDonaldTrump" was frequently split into "@realDonald" and "Trump") so the following SQL query was used to retrieve all appearances:
SELECT date, station, showName, iaThumbnailUrl, iaClipUrl,OCRText FROM `gdelt-bq.gdeltv2.vgegv2_iatv` WHERE DATE(date) >= "2020-01-01" and (station='CNN' OR station='MSNBC' OR station='FOXNEWS') and REGEXP_CONTAINS(LOWER(OCRText), r'@\s*joe\s*biden') ORDER BY DATE ASC
Given the small number of results, these were then manually connected to their corresponding tweets. In this case, multiple tweets appearing onscreen concurrently were each uniquely recorded.