Earlier this year we released an ngrams dataset consisting of unigrams and bigrams for a dozen television news stations dating back a decade, using data from the Internet Archive's Television News Archive. In the past we've demonstrated how this dataset can be used to compute complex sentiment scores like anxiety. Yet it can also be used to gain deeper understandings of powerful latent framing dimensions like "ourside" language in which pronouns can alternatively emphasize in-group dynamics ("us", "we", "our" and "ours") versus out-group dynamics ("they", "them", "their" and "theirs"). (These eight words are not exhaustive, but capture a reasonable approximation of the two categories).
The timeline below shows the percentage of all words on CNN that were "ourside" words ("us", "we", "our" and "ours") by month from July 2009 through present compared with the percentage of all words that were "theirside" words ("they", "them", "their" and "theirs").
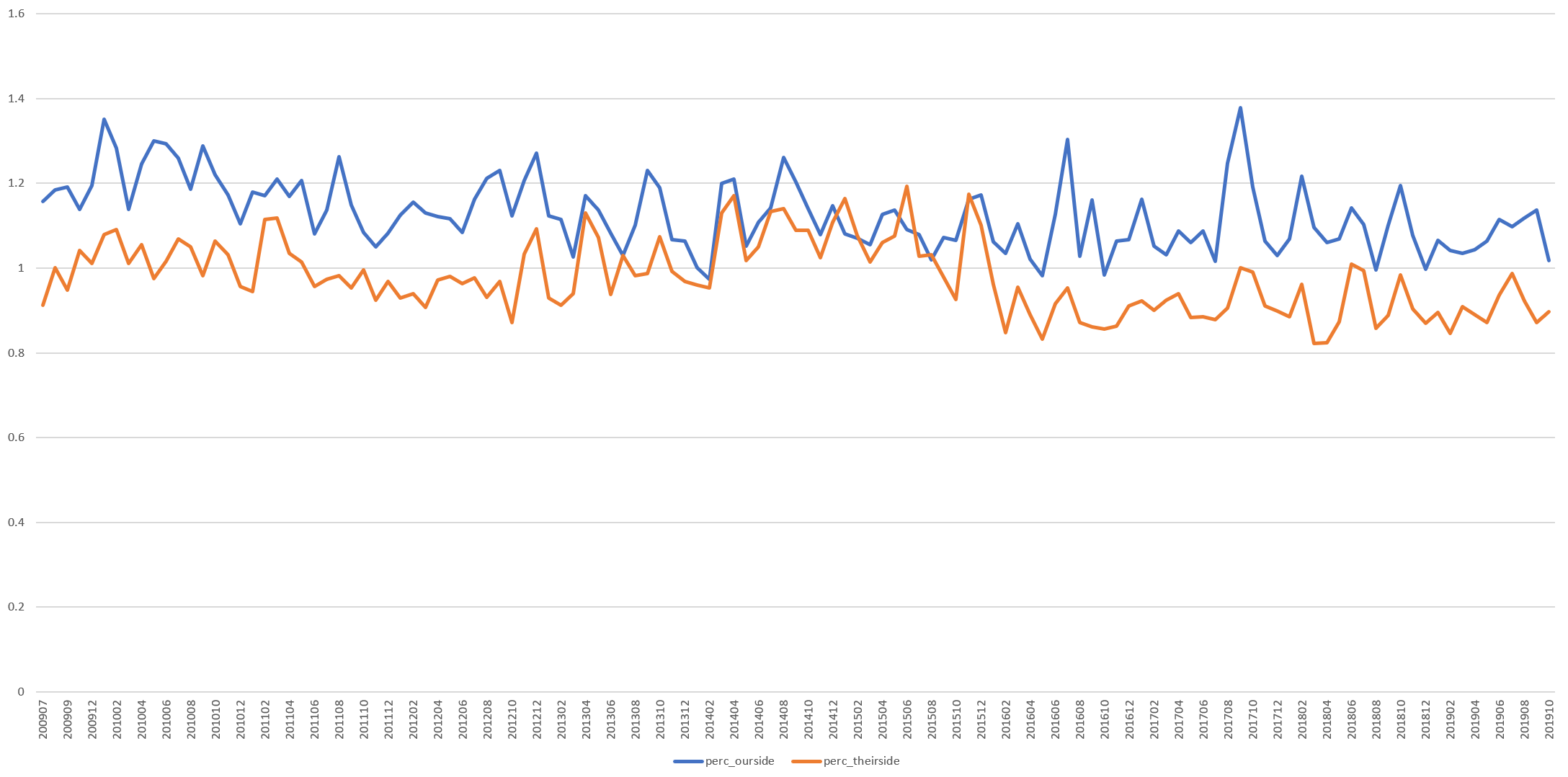
Typically "ourside" language is more prevalent, but interestingly, from early 2013 through late 2015, the two were roughly equal. This resulted not from a decrease in "ourside" language but rather from an increase in "theirside" wording. It is unclear whether this increase resulted from increased use of such words by CNN's own anchors and reporters or whether it was increasingly covering stories in which participants uttered such words.
The timeline below shows the same analysis for MSNBC.
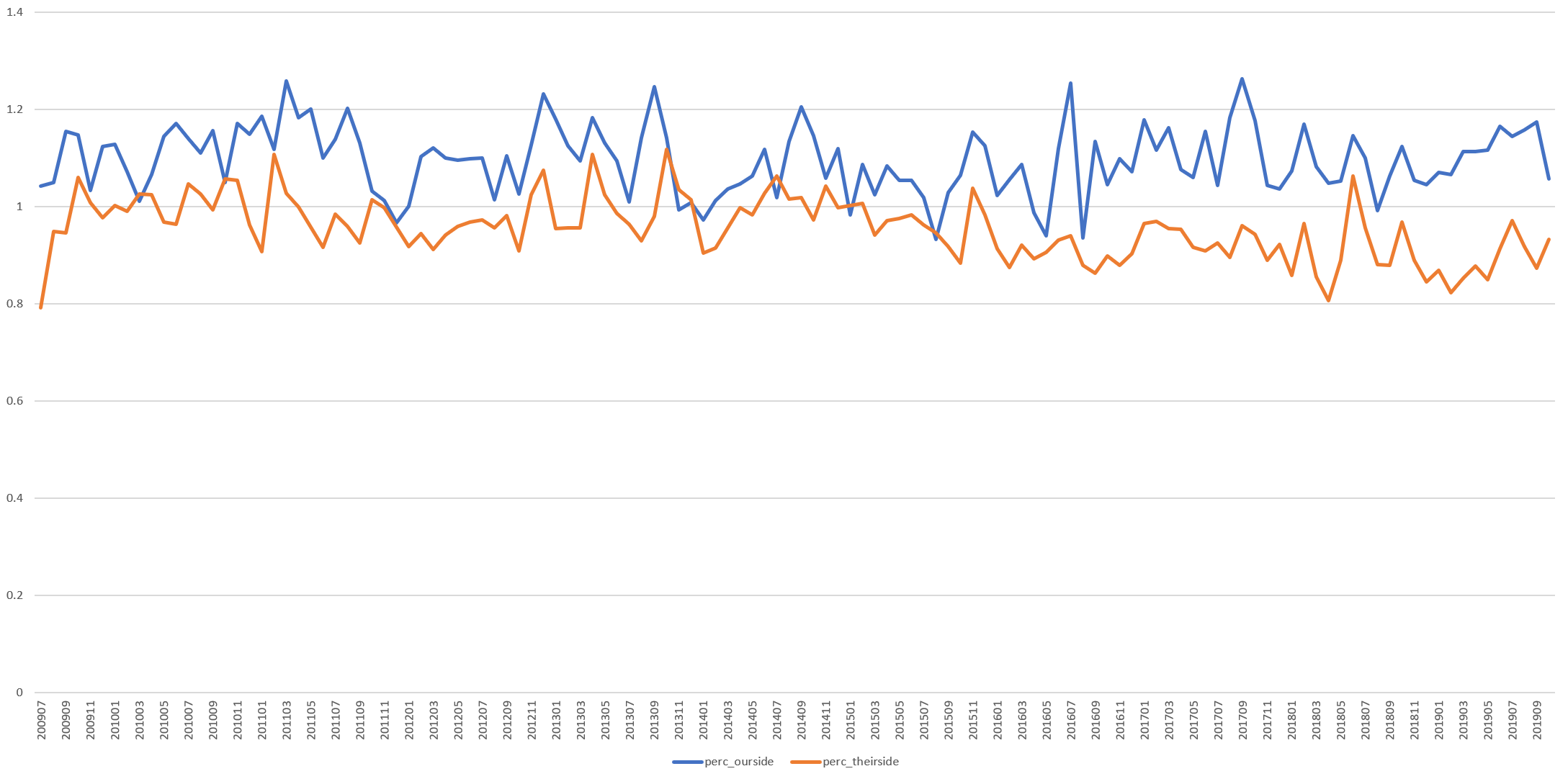
Here the 2013-2015 period is visible, though to a lesser degree and the preceding period has a closer overlap as well. Noticeably, starting in late 2015 as Trump rose in national prominence, MSNBC's use of "theirside" language has decreased considerably.
The timeline below repeats this analysis for Fox News.
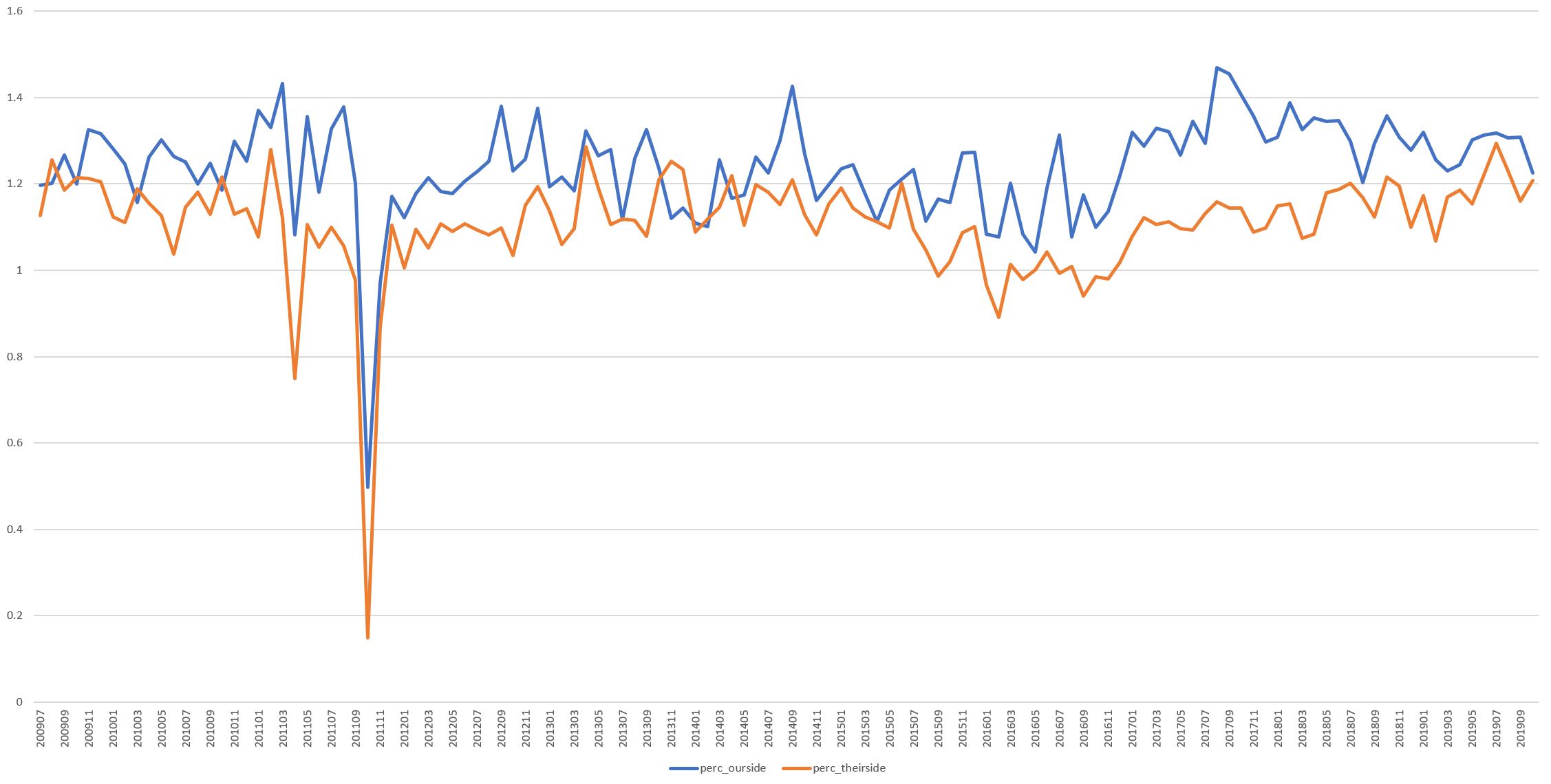
Here the two categories are fairly overlapped through late 2015 and which point they separate. Both record increases, with "theirside" language increasingly linearly.
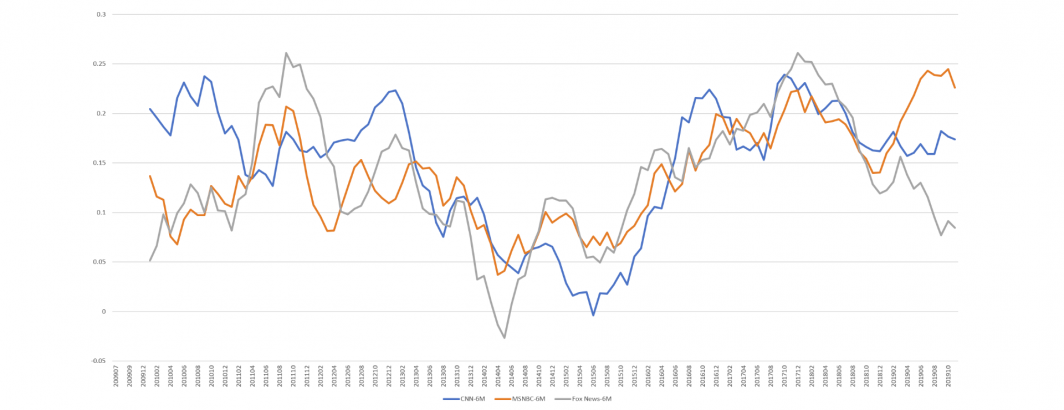
How does the separation between "ourside" and "theirside" language compare across the three channels? The timeline below subtracts the percentage of "theirside" language from "ourside" language by month and overlays the three stations, using a 6 month rolling average to make the trends clearer.
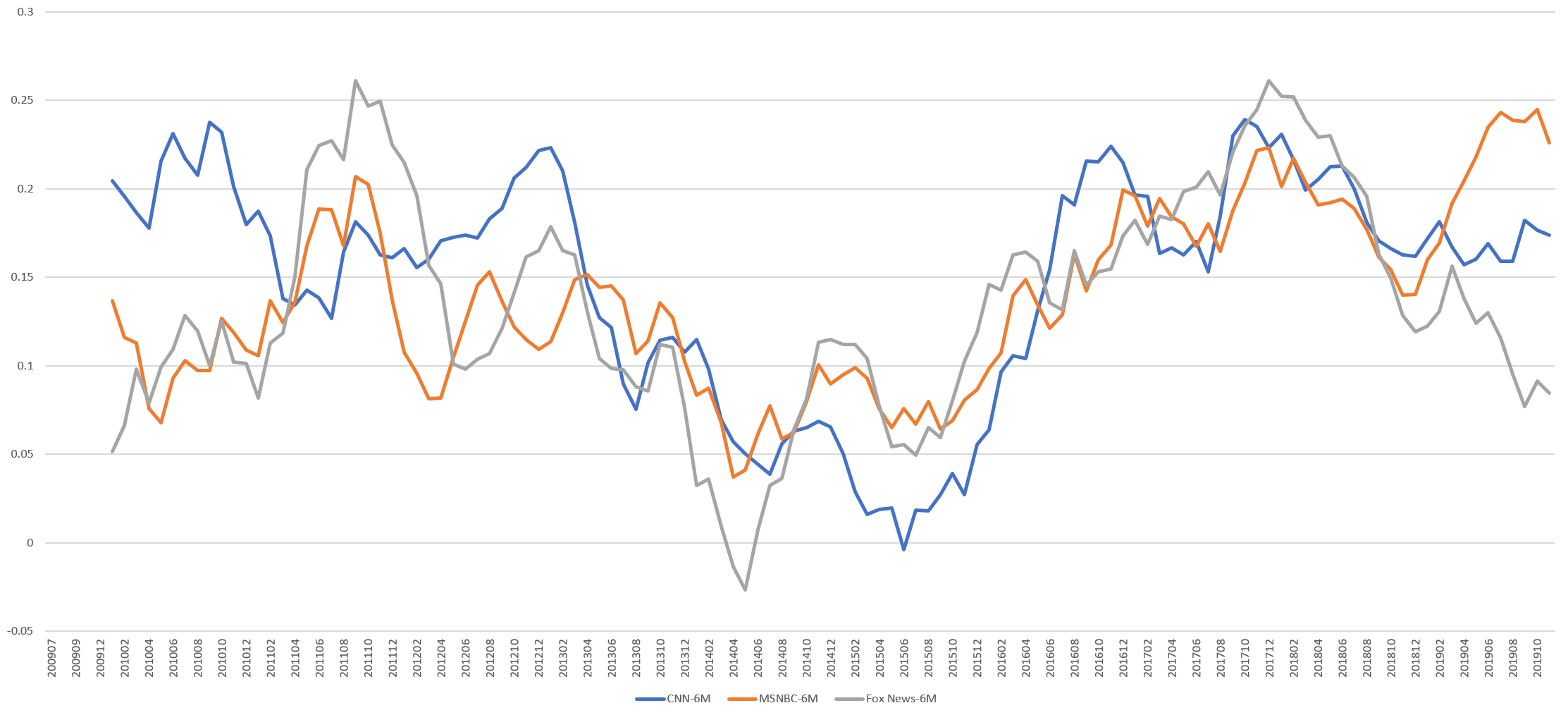
All three stations follow an overall similar macro curve with a sharp decrease from late 2013 through mid 2016. The three stations also appear to be diverging sharply over the course of 2019, with MSNBC markedly favoring "ourside" language, Fox News shifting towards "theirside" language and CNN holding to a relatively consistent balance of the two categories.
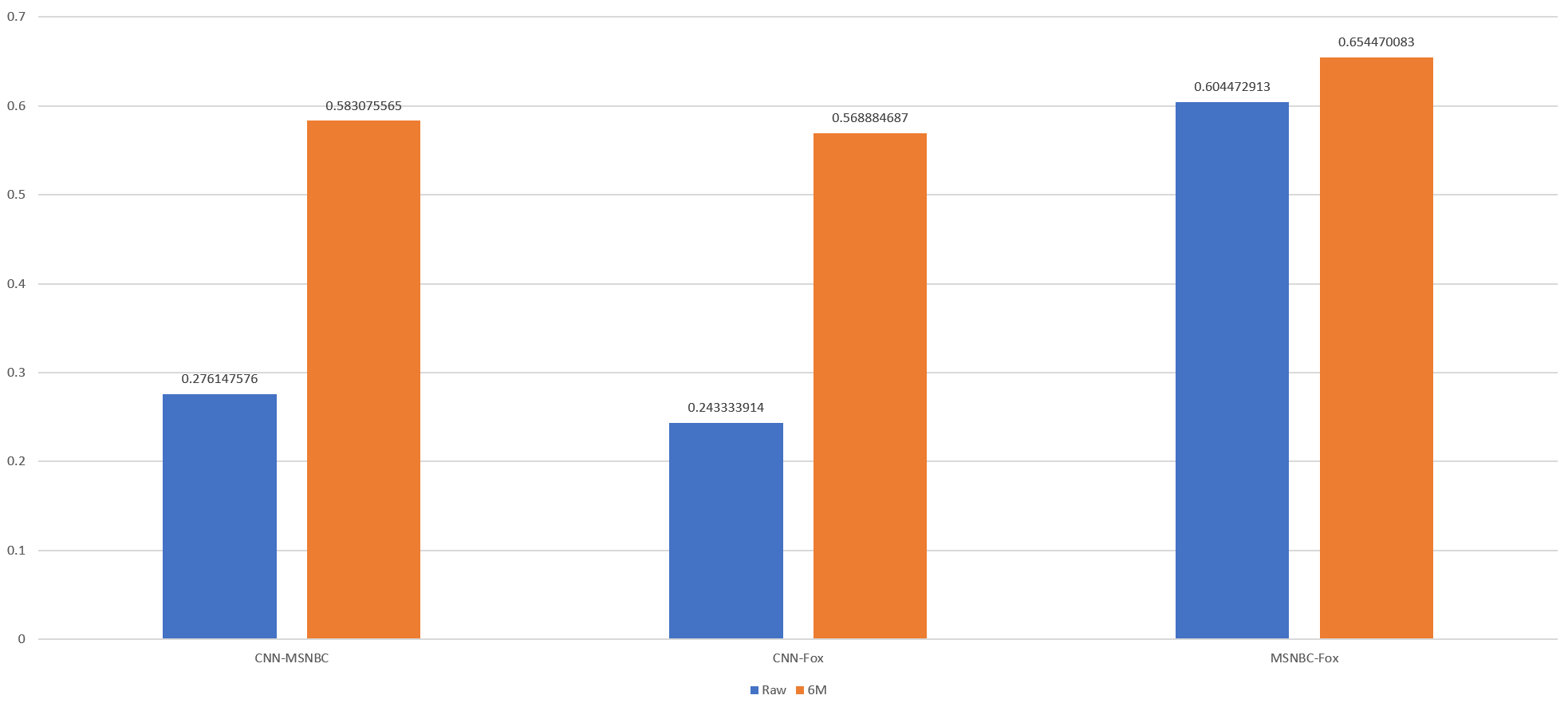
Interestingly, MSNBC and Fox News show the greatest similarity while CNN is the most divergent from the two, as seen in the chart below which displays the Pearson correlations of their "ourside – theirside" differences for both the raw timeline and the 6-month rolling average version above.
As a verification test, here is the same process repeated to plot the density of the word "the" and the word "a" over the same time period. Interestingly, the word "the" decreases" slightly during the same slight dip as the ourside/theirside words, while the word "a" shows no similar decrease. Overall, however, both are relatively stable over the period, suggesting that the trends above are genuine.

Again, it is important to recognize that these graphs reflect a mixture of statements by the station's own reporters and anchors and those of people they are interviewing, guests and those they are covering, but reflect the macro-level image of society seen by their viewers.
TECHNICAL DETAILS
Constructing the graphs above was trivial, requiring just a single SQL query that took just 4 seconds to execute. Change the "CNN" in the query below to "MSNBC" or "FOXNEWS" to repeat for each of the three stations above.
SELECT DATE, SUM(COUNT) TOTWORDS, SUM(OURCOUNT) TOTOURWORDS, SUM(OURCOUNT) / SUM(COUNT) * 100 perc_ourside, SUM(THEIRCOUNT) TOTTHEIRWORDS, SUM(THEIRCOUNT) / SUM(COUNT) * 100 perc_theirside FROM ( SELECT SUBSTR(CAST(DATE AS STRING), 0, 6) DATE, WORD, 0 COUNT, COUNT OURCOUNT, 0 THEIRCOUNT FROM `gdelt-bq.gdeltv2.iatv_1grams` WHERE STATION='CNN' and WORD in ( SELECT * FROM UNNEST (["us", "we", "our", "ours"]) AS WORD ) UNION ALL SELECT SUBSTR(CAST(DATE AS STRING), 0, 6) DATE, WORD, 0 COUNT, 0 OURCOUNT, COUNT THEIRCOUNT FROM `gdelt-bq.gdeltv2.iatv_1grams` WHERE STATION='CNN' and WORD in ( SELECT * FROM UNNEST (["them", "they", "their", "theirs"]) AS WORD ) UNION ALL SELECT SUBSTR(CAST(DATE AS STRING), 0, 6) DATE, WORD, COUNT, 0 OURCOUNT, 0 THEIRCOUNT FROM `gdelt-bq.gdeltv2.iatv_1grams` WHERE STATION='CNN' ) group by DATE order by DATE asc
Happy querying!