Last month we demonstrated applying facial scanning to Russian television news to catalog all of the appearances of Tucker Carlson across a year of 60 Minutes. That workflow was designed for traditional broadcast television news channels monitored by the Internet Archive's TV News Archive, but means it cannot be readily extended to the myriad other streaming video channels available today, from mainstream broadcasters across the world to live video of global events streamed across social platforms each day. Here we will show how using a few off-the-shelf tools the same workflow can be applied to any streaming video feed in just a few lines of code.
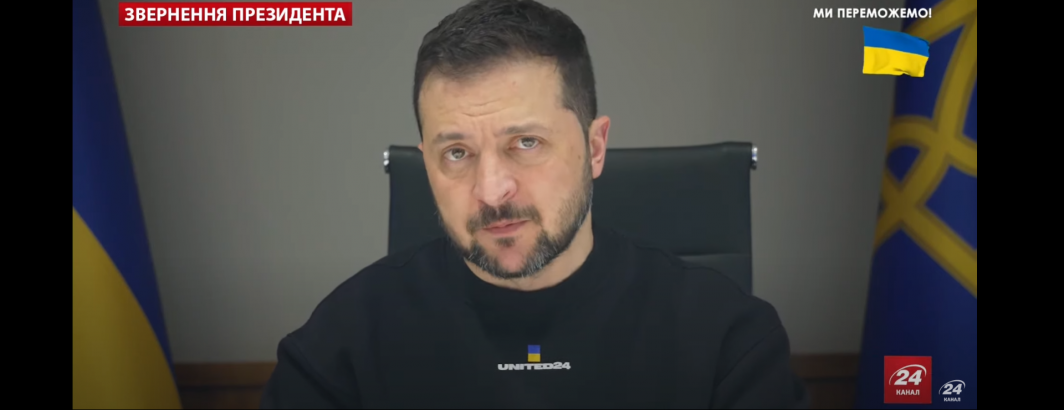
Let's take Channel 24, a Ukrainian television channel that live-streams 24/7 on Youtube and scan it continuously for all appearances of Joe Biden, Vladimir Putin and Volodymyr Zelenskyy. Here is their live-streaming YouTube feed:
First, we need to find a way of accessing that stream in a way that we can process it. One of the most widely-used tools is youtube-dl, of which we'll use the yt-dlp fork which we've found in our own work to update more frequently with the latest templates for major video platforms.
Let's install the tool:
python3 -m pip install -U yt-dlp
This will accept any video hosting URL for major platforms like YouTube and download them to disk. For static videos this works perfectly, but for live-streaming videos, we need to be able to process the video data continuously. For that, we'll have yt-dlp pipe the video data to standard out and pipe it into another widely used tool, ffmpeg. We'll use some advanced capabilities of ffmpeg to shard the continuous stream into one minute files with independent timestamps and faststart.
Let's install ffmpeg:
apt-get update apt-get -y install ffmpeg
Now to take the livestream above and shard it into one minute files we simply connect the two and and add a few command line options:
mkdir VIDEOCACHE yt-dlp -q -o - "https://www.youtube.com/watch?v=hns12gYNRq0" | ffmpeg -hide_banner -loglevel error -i - -c copy -flags +global_header -f segment -segment_time 60s -segment_atclocktime 1 -strftime 1 -segment_format_options movflags=+faststart -reset_timestamps 1 ./VIDEOCACHE/VIDEO_%Y%m%d%H%M00.mp4&
That single line does an incredible amount of work. It connects to the YouTube livestream above and ingests it, splitting it every minute into a new file with the current timestamp and writing the one minute files into a subdirectory called ./VIDEOCACHE/. That's literally all that is needed to ingest any streaming video.
Of course, in reality, network issues and other technical problems can cause a stream to disconnect. Use the Perl script below as a simple template for a wrapper around yt-dlp that will automatically reconnect when a stream is lost. Each time it updates yt-dlp in case the disconnect was due to a change in a hosting platform that requires a new template. Save this as "streamvideo.pl":
#!/usr/bin/perl
$STREAMURL = $ARGV[0];
if ($STREAMURL eq '') { print "USAGE: ./streamingfaceanalyze.pl URL\n"; exit; };
mkdir("./VIDEOCACHE/");
while(1==1) {
open(OUT, ">>./LOG.TXT"); print OUT localtime(time) . ": Startup...\n"; close(OUT);
#update yt-dlp to add any updated regexes...
open(OUT, ">>./LOG.TXT"); print OUT localtime(time) . ": Updating YT-DLP...\n"; close(OUT);
system("python3 -m pip install -U yt-dlp");
#and begin streaming...
open(OUT, ">>./LOG.TXT"); print OUT localtime(time) . ": Beginning Streaming...\n"; close(OUT);
$START = time;
system("yt-dlp -q -o - \"$STREAMURL\" | ffmpeg -hide_banner -loglevel error -i - -c copy -flags +global_header -f segment -segment_time 60s -segment_atclocktime 1 -strftime 1 -segment_format_options movflags=+faststart -reset_timestamps 1 ./VIDEOCACHE/VIDEO_%Y%m%d%H%M00.mp4");
#if we reach this point, our stream broke, so loop back again - will update yt-dlp and resume streaming...
#to prevent fast-cycling, check if the stream exited too fast and exit if so - the stream is either over or there is an underlying issue that requires further attention
if ( (time - $START) < 15) {
print "FATAL STREAM ERROR: EXITING\n";
open(OUT, ">>./LOG.TXT"); print OUT localtime(time) . ": Fatal Stream Error: EXITING...\n"; close(OUT);
exit;
};
}
Run it as:
./streamvideo.pl https://www.youtube.com/watch?v=hns12gYNRq0&
You'll end up with a directory full of MP4 files like the following, with each representing one minute of the livestream:
-rw-r--r-- 1 user user 14M Apr 5 00:50 VIDEO_20230405004900.mp4 -rw-r--r-- 1 user user 11M Apr 5 00:51 VIDEO_20230405005000.mp4 -rw-r--r-- 1 user user 11M Apr 5 00:52 VIDEO_20230405005100.mp4 -rw-r--r-- 1 user user 9.1M Apr 5 00:53 VIDEO_20230405005200.mp4 -rw-r--r-- 1 user user 12M Apr 5 00:54 VIDEO_20230405005300.mp4 -rw-r--r-- 1 user user 15M Apr 5 00:55 VIDEO_20230405005400.mp4 -rw-r--r-- 1 user user 9.7M Apr 5 00:56 VIDEO_20230405005500.mp4 -rw-r--r-- 1 user user 11M Apr 5 00:57 VIDEO_20230405005600.mp4 -rw-r--r-- 1 user user 11M Apr 5 00:58 VIDEO_20230405005700.mp4 -rw-r--r-- 1 user user 15M Apr 5 00:59 VIDEO_20230405005800.mp4 -rw-r--r-- 1 user user 14M Apr 5 01:00 VIDEO_20230405005900.mp4 -rw-r--r-- 1 user user 11M Apr 5 01:01 VIDEO_20230405010000.mp4
There are a number of realtime face analysis tools out there that can leverage GPU acceleration to process a live video stream in true realtime, but here we'll show how you can use any off-the-shelf still image analyzer with this pipeline.
First, we'll need to take each video file and convert it to a sequence of still images. FFMPEG can do this with a single command. Here we'll ask ffmpeg to take one of the one-minute videos above and sample it at one frame every one second and output them all as a sequence of JPEG images into a subdirectory:
mkdir FRAMECACHE mkdir FRAMECACHE/VIDEO_20230405005600/ time ffmpeg -nostdin -hide_banner -loglevel panic -i ./VIDEOCACHE/VIDEO_20230405005600.mp4 -vf "fps=1,scale=iw*sar:ih" "./FRAMECACHE/VIDEO_20230405005600/%06d.jpg"
Note the scale formula above, which allows it to correct handle PAL format videos and others with unusual ratios.
This will output a directory of 60 images, one per second of airtime, of our video.
Now its time to scan them for known faces. We'll use the same "face_recognition" package we used for our Tucker Carlson analysis. First we'll install the package and dependencies (along with ImageMagick, which we'll use to speed things up with our known images):
apt-get -y install imagemagick apt-get -y install build-essential brew install cmake pip3 install face_recognition
Now we'll download a set of "known" faces to scan for (you can have as many as you want):
mkdir KNOWNFACES wget https://upload.wikimedia.org/wikipedia/commons/9/9c/Volodymyr_Zelensky_Official_portrait.jpg mv Volodymyr_Zelensky_Official_portrait.jpg KNOWNFACES/VolodymyrZelenskyy.png wget https://www.whitehouse.gov/wp-content/uploads/2021/04/P20210303AS-1901-cropped.jpg mv P20210303AS-1901-cropped.jpg KNOWNFACES/JoeBiden.jpg wget http://static.kremlin.ru/media/events/press-photos/orig/41d3e9385e34ebc0e3ba.jpeg mv 41d3e9385e34ebc0e3ba.jpeg KNOWNFACES/VladimirPutin.jpg #resize them to speed up the processing convert KNOWNFACES/VolodymyrZelensky.png -resize 1000x1000 KNOWNFACES/VolodymyrZelenskyy.jpg; rm VolodymyrZelenskyy.png convert KNOWNFACES/JoeBiden.jpg -resize 1000x1000 KNOWNFACES/JoeBiden.jpg convert KNOWNFACES/VladimirPutin.jpg -resize 1000x1000 KNOWNFACES/VladimirPutin.jpg
To scan our one minute video for these known faces is as simple as:
time face_recognition --cpus 4 --show-distance true --tolerance 0.52 ./KNOWNFACES/ ./FRAMECACHE/VIDEO_20230405005600/ | sort > RESULTS.ALL.TXT
Let's wrap this pipeline (shard video into images, run face_recognition over it and then clean up the temporary images) into a single script. Save the Perl script below as "scanvideo.pl":
#!/usr/bin/perl
if (!-e "./FRAMECACHE/") { mkdir("./FRAMECACHE/"); };
$FILENAME = $ARGV[0]; if ($FILENAME eq '') { print "USAGE: ./scanvideo.pl VIDEO.mp4\n"; exit; };
$FRAMENAME = $FILENAME; $FRAMENAME=~s/^.*\///;
system("mkdir ./FRAMECACHE/$$");
#burst into frames...
system("ffmpeg -nostdin -hide_banner -loglevel panic -i $FILENAME -vf \"fps=1,scale=iw*sar:ih\" \"./FRAMECACHE/$$/${FRAMENAME}-%06d.jpg\"");
#run face_detect on them...
system("cd ./FRAMECACHE/$$/; face_recognition --cpus 4 --show-distance true --tolerance 0.52 ../../KNOWNFACES/ . | sort >> ../../FACEDETECTRESULTS.TXT");
#clean up...
system("rm -rf ./FRAMECACHE/$$/");
Run it on one of the videos above as:
./scanvideo.pl ./VIDEOCACHE/VIDEO_20230405005400.mp4
Finally, we'll need a script that loops and once a minute calls "scanvideo.pl" to process the previous minute's MP4 file. Save the following as "scanvideo_loop.pl":
#!/usr/bin/perl
while(1==1) {
#wait until X sec after the minute for any final closings to complete on the file...
($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime(time);
while ($sec != 5) {
sleep 1;
($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime(time);
}
#compute the filename of the previous minute's file that is now ready to process...
($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime(time-30);
$FILENAME = sprintf("VIDEO_%04d%02d%02d%02d%02d00", $year+1900,$mon+1,$mday,$hour,$min);
#and process...
system("./scanvideo.pl ./VIDEOCACHE/$FILENAME.mp4&");
sleep 5;
}
To run the entire pipeline, save the scripts above and run as:
./streamvideo.pl https://www.youtube.com/watch?v=hns12gYNRq0& ./scanvideo_loop.pl&
That's literally all there is to it! Within 60 seconds you'll start to see data being appended to FACEDETECTRESULTS.TXT that looks like the lines below:
./VIDEO_20230405000300.mp4-000001.jpg,no_persons_found,None ./VIDEO_20230405000300.mp4-000002.jpg,no_persons_found,None ./VIDEO_20230405000300.mp4-000003.jpg,no_persons_found,None ./VIDEO_20230405000300.mp4-000004.jpg,no_persons_found,None ./VIDEO_20230405000300.mp4-000005.jpg,VolodymyrZelenskyy,0.4707938704590828 ./VIDEO_20230405000300.mp4-000006.jpg,unknown_person,None ./VIDEO_20230405000300.mp4-000007.jpg,unknown_person,None ./VIDEO_20230405000300.mp4-000008.jpg,unknown_person,None ./VIDEO_20230405000300.mp4-000009.jpg,VolodymyrZelenskyy,0.5029658692207 ./VIDEO_20230405000300.mp4-000010.jpg,VolodymyrZelenskyy,0.45118895826692834 ./VIDEO_20230405000300.mp4-000011.jpg,VolodymyrZelenskyy,0.4777247927209883 ./VIDEO_20230405000300.mp4-000012.jpg,VolodymyrZelenskyy,0.48751702625814913 ./VIDEO_20230405000300.mp4-000013.jpg,VolodymyrZelenskyy,0.495598934796091 ./VIDEO_20230405000300.mp4-000014.jpg,VolodymyrZelenskyy,0.4514292540830682 ./VIDEO_20230405000300.mp4-000015.jpg,VolodymyrZelenskyy,0.4657893173497163 ./VIDEO_20230405000300.mp4-000016.jpg,VolodymyrZelenskyy,0.439866910034344 ./VIDEO_20230405000300.mp4-000017.jpg,VolodymyrZelenskyy,0.46329180616681764 ./VIDEO_20230405000300.mp4-000018.jpg,VolodymyrZelenskyy,0.4790736329334561 ./VIDEO_20230405000300.mp4-000019.jpg,VolodymyrZelenskyy,0.49253782287136383 ./VIDEO_20230405000300.mp4-000020.jpg,VolodymyrZelenskyy,0.4917721288976006 ./VIDEO_20230405000300.mp4-000021.jpg,VolodymyrZelenskyy,0.46000864509442385 ./VIDEO_20230405000300.mp4-000022.jpg,unknown_person,None ./VIDEO_20230405000300.mp4-000023.jpg,VolodymyrZelenskyy,0.41238372780053334
You can see Zelenskyy appearing briefly for a second, then disappearing for three seconds, then being displayed steadily for 13 seconds. You can add new images to the KNOWNFACES directory at any time – we experimented with loading different additional faces that were then immediately scanned for from that point further.
Of course, in a production pipeline you could run two copies of yt-dlp – one saving MP4's on disk for archival reference and one sharding into a steady stream of still images live and piping those images into a standing copy of the face_recognition tool in memory, which automatically removes the images as it processes them. In fact, such a pipeline could achieve a latency of just 1-2 seconds. Sharding into one-minute MP4 files, splitting into still images and processing by loading the model anew each minute like we do here is extremely inefficient but for demonstration purposes shows how trivial the entire pipeline is.
In fact, absent the comments, spacing and extra error handling logic above, this entire pipeline could be written in just a few lines of code!
A production system would also save the embedding for all extracted faces as a live JSON database and pipe into ElasticSearch or similar ANN search service to permit live realtime facial search.
In the end, with just a few lines of code you can scan any livestream video now. In fact, you can use yt-dlp to download most videos from most major hosting platforms, including social platforms like Twitter and can simply feed the downloaded MP4 file through the scanvideo.pl script above.
Recall this Twitter post we examined last year, of a video posted to Twitter that excerpts a series of clips from Russian media. What if we wanted to scan that video – a random video on Twitter – for Biden, Putin and Zelenskyy's faces? Doing so takes literally two lines:
rm TWITTERVIDEO.mp4; yt-dlp -o TWITTERVIDEO.mp4 https://twitter.com/JuliaDavisNews/status/1586395220476039168 rm FACEDETECTRESULTS.TXT; ./scanvideo.pl ./TWITTERVIDEO.mp4
The results will be written to ./FACEDETECTRESULTS.TXT and look like:
./TWITTERVIDEO.mp4-000001.jpg,no_persons_found,None ./TWITTERVIDEO.mp4-000002.jpg,no_persons_found,None ./TWITTERVIDEO.mp4-000003.jpg,no_persons_found,None ./TWITTERVIDEO.mp4-000004.jpg,no_persons_found,None ./TWITTERVIDEO.mp4-000005.jpg,unknown_person,None ./TWITTERVIDEO.mp4-000006.jpg,no_persons_found,None ./TWITTERVIDEO.mp4-000007.jpg,unknown_person,None ./TWITTERVIDEO.mp4-000008.jpg,unknown_person,None ./TWITTERVIDEO.mp4-000009.jpg,unknown_person,None ./TWITTERVIDEO.mp4-000010.jpg,unknown_person,None ./TWITTERVIDEO.mp4-000011.jpg,unknown_person,None ...
In this case, none of the three heads of state we are interested in appear in the video.
What about this video from earlier today of Polish president Andrzej Duda with Zelenskyy?
rm TWITTERVIDEO.mp4; yt-dlp -o TWITTERVIDEO.mp4 https://twitter.com/AndrzejDuda/status/1643599931687436289 rm FACEDETECTRESULTS.TXT; ./scanvideo.pl ./TWITTERVIDEO.mp4
The results are saved to ./FACEDETECTRESULTS.TXT and look like:
./TWITTERVIDEO.mp4-000001.jpg,unknown_person,None ./TWITTERVIDEO.mp4-000001.jpg,unknown_person,None ./TWITTERVIDEO.mp4-000002.jpg,VolodymyrZelensky,0.510376752615344 ./TWITTERVIDEO.mp4-000002.jpg,unknown_person,None ./TWITTERVIDEO.mp4-000003.jpg,VolodymyrZelensky,0.49649295257399223 ./TWITTERVIDEO.mp4-000003.jpg,unknown_person,None ./TWITTERVIDEO.mp4-000004.jpg,VolodymyrZelensky,0.4795819510802723 ./TWITTERVIDEO.mp4-000004.jpg,unknown_person,None ./TWITTERVIDEO.mp4-000005.jpg,unknown_person,None ./TWITTERVIDEO.mp4-000006.jpg,unknown_person,None ./TWITTERVIDEO.mp4-000007.jpg,unknown_person,None ./TWITTERVIDEO.mp4-000007.jpg,unknown_person,None ./TWITTERVIDEO.mp4-000008.jpg,VolodymyrZelensky,0.44328139217391416 ./TWITTERVIDEO.mp4-000008.jpg,unknown_person,None
Here it correctly identified Zelenskyy in several of the frames, along with the presence of a second unknown person (Duda).
Why did it miss some of the frames? Here is a closer look at frame 000005:

Unfortunately, at the precise frame that begins the 5th second of the video, Zelenskyy's face is tilted down at an extreme angle, worsened by heavy motion blur and severe compression artifacts. FFMPEG has a large number of options that can assist with this, including features to identify the clearest and "best" image within a given set of frames. Improving the video-to-images conversion command above would significantly improve the results with videos like this.
In the end, just a handful of lines of code is all that's required to process both static social media videos and live-streaming videos with just a 1-2 minute latency and even, with a few extra lines of code, feed the resulting embeddings into a search system for realtime interactive search.
Using the pipeline above, you can extend this workflow to any live-streamed event across the web.