
Continuing yesterday's experiments, what if we boost the resolution of the surrogate thumbnail images from 200×200 pixels to 500×500 pixels – does that improve our OCR results?
Recall our workflow from yesterday: applying ffmpeg's scene detection to the Visual Explorer's 1/4fps frames to output just those images that differ by more than 20% from the preceding frame. Then we resize those selected frames to 500×500 pixels and form the resulting images into a thumbnail montage:
time ffmpeg -i ./CNNW_20240903_230000_Erin_Burnett_OutFront-%06d.jpg -vf "select='gt(scene,0.2)',showinfo" -vsync vfr ./OUTPUT/OUT-%06d.jpg time mogrify -resize 500 ./OUTPUT/* time montage ./OUTPUT/OUT-%06d.jpg[1-500] -tile 10x -geometry +10+10 -background black ./CNNW_20240903_230000_Erin_Burnett_OutFront.change02.montage.jpg;
This yields the following image that clocks in at 5200×6923, still well within our limits:
Running this through Cloud Vision takes 4.8s:
time gsutil -m -q cp "./IMAGE.jpg" gs://[YOURBUCKET]/
curl -s -H "Content-Type: application/json; charset=utf-8" -H "x-goog-user-project:[YOURPROJECTID]" -H "Authorization: Bearer $(gcloud auth print-access-token )" https://vision.googleapis.com/v1/images:annotate -d '{ "requests": [ { "image": { "source": { "gcsImageUri": "gs://[YOURBUCKET]/ IMAGE.jpg" } }, "features": [ {"type":"TEXT_DETECTION"} ] } ] }' | jq -r .responses[].fullTextAnnotation.text
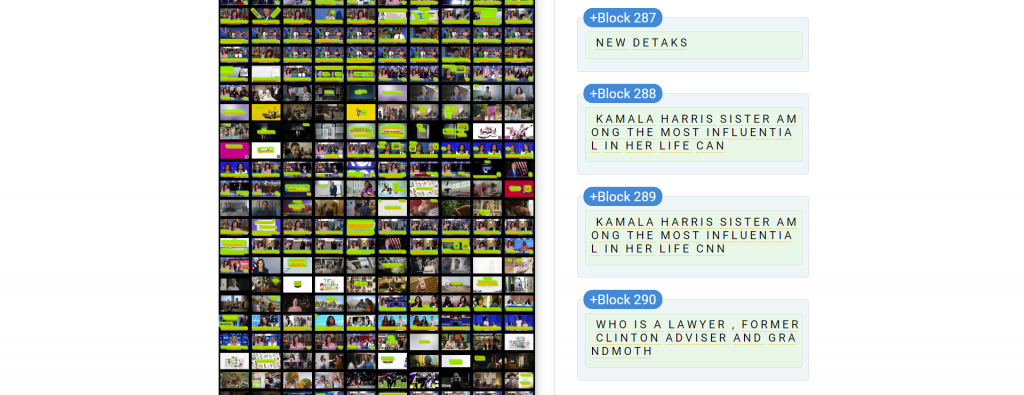
This yields the following OCR results, which are more than twice as large as our 200×200 pixel results, suggesting vastly improved text capture:
Recall that yesterday's experiment using 200×200 pixel images yielded 1,395 words totaling 8,267 characters of OCR'd text. In contrast, this time we extracted 4,571 words totaling 26,932 characters, reflecting the critical importance of image resolution to OCR workflows:
cat ./CNNW_20240903_230000_Erin_Burnett_OutFront.change02lower30.json | jq -r .responses[].fullTextAnnotation.text | wc cat ./CNNW_20240903_230000_Erin_Burnett_OutFront.change02resize500.montage.json | jq -r .responses[].fullTextAnnotation.text | wc
Examining the JSON above you can see how each word has a corresponding XY bounding box that can be used to segment the text by source frame, allowing us to deconstruct the resulting whole-montage text block into the text corresponding to each frame:
{
"description": "SPEAK",
"boundingPoly": {
"vertices": [
{
"x": 83,
"y": 272
},
{
"x": 115,
"y": 272
},
{
"x": 115,
"y": 280
},
{
"x": 83,
"y": 280
}
]
}
},
{
"description": "TO",
"boundingPoly": {
"vertices": [
{
"x": 117,
"y": 272
},
{
"x": 130,
"y": 272
},
{
"x": 130,
"y": 280
},
{
"x": 117,
"y": 280
}
]
}
},
{
"description": "NETANYAHU",
"boundingPoly": {
"vertices": [
{
"x": 133,
"y": 272
},
{
"x": 189,
"y": 272
},
{
"x": 189,
"y": 280
},
{
"x": 133,
"y": 280
}
]
}
},