Closed captioning in television news programming typically lags the actual spoken word content it transcribes by several seconds as the human transcriptionist types what they hear. For precision search, we use ASR and the "diff" utility to align the human captioning at subsecond accuracy using the per-word ASR timecodes. Yet ASR is extremely expensive, raising the question of whether we could perform serviceable coarse alignment by correcting only on commercial break returns.
Under this model, we use FFMPEG to detect all of the blackframe transition periods in the video where the programming transitions either to or from a commercial break:
ffmpeg -i ./VIDEO.mp4 -vf "blackdetect=d=0.05:pix_th=0.10" -an -f null - 2>&1 | grep blackdetect
For the Dec. 1, 2020 1AM PST episode of CNN Newsroom Live, this yields the list below:
black_start:13.4301 black_end:15.2819 black_duration:1.85185 black_start:743.927 black_end:744.043 black_duration:0.116783 black_start:969.085 black_end:970.653 black_duration:1.56823 black_start:1568.32 black_end:1568.4 black_duration:0.0834167 black_start:1759.81 black_end:1759.87 black_duration:0.0667333 black_start:1764.85 black_end:1766.78 black_duration:1.93527 black_start:2496.99 black_end:2497.08 black_duration:0.0834167 black_start:2572.15 black_end:2572.22 black_duration:0.0667333 black_start:2603.88 black_end:2603.95 black_duration:0.0667333 black_start:2605.92 black_end:2606.14 black_duration:0.216883 black_start:2637.92 black_end:2640.19 black_duration:2.26893 black_start:2641.96 black_end:2642.12 black_duration:0.166833 black_start:2672.12 black_end:2673.12 black_duration:1.001 black_start:2678.04 black_end:2679.19 black_duration:1.15115 black_start:3014.21 black_end:3014.29 black_duration:0.0834167 black_start:3074.32 black_end:3074.39 black_duration:0.0667333 black_start:3239.37 black_end:3240.37 black_duration:1.001 black_start:3418.62 black_end:3418.7 black_duration:0.0834167 black_start:3478.66 black_end:3478.79 black_duration:0.133467 black_start:3508.76 black_end:3508.82 black_duration:0.0667333 black_start:3548.76 black_end:3548.81 black_duration:0.05005 black_start:3608.81 black_end:3609.87 black_duration:1.06773 black_start:3614.71 black_end:3615.85 black_duration:1.13447
Using the "caption mode" field of CCExtractor's TTXT export format, we categorize each second of airtime of the broadcast as either an advertisement/uncaptioned or news programming. At the start of each block of news programming following a commercial break, we compute its start time in the captioning timecode. We then look to the blackframe detection list above to find the nearest blackframe transition period in video timecode. We now know that the given caption timecode corresponds to the given video timecode. In essence, this is akin to the hand clap used synchronize audio and video tracks when filming.
Given that captioning appears as blocks of words that span multiple seconds, we evenly distributed the words in each captioning line across the start and stop times of that block. While in reality some words will be spoken faster than others, this at least achieves a reasonable distribution of the words in assigning them to specific seconds of airtime.
The CNN broadcast above is divided into 7 news blocks that follow a commercial break. For each block the list below shows the actual video timecode begin of the first word of captioning of that block using the precise ASR results. The "Caption Timecode" shows the timecode the closed captioning reports the first word as spoken at. Finally, the "Blackframe Aligned" field returns the corrected timecode for each block by taking the caption timecode and adjusting it backwards to the end of the blackframe divider.
This yields the following:
- News
- ASR: 15s
- Blackframe Aligned: 15s
- Caption Timecode: 23s
- News
- ASR: 74s
- Blackframe Aligned: 69s
- Caption Timecode: 77s
- News
- ASR: 976s
- Blackframe Aligned: 970s
- Caption Timecode: 980s
- News
- ASR: 1772s
- Blackframe Aligned: 1764s
- Caption Timecode: 1775s
- News
- ASR: 2684s
- Blackframe Aligned: 2678s
- Caption Timecode: 2689s
- News
- ASR: 3245s
- Blackframe Aligned: 3238s
- Blackframe + Speech Aligned: 3246s
- Caption Timecode: 3249s
- News
- ASR: 3621s
- Blackframe Aligned: 3616s
- Caption Timecode: 3627s
Unfortunately, as it is clear above, the naive alignment fails to correctly align the captioning transcript and in some cases actually makes the alignment worse than the original captioning timecodes.
The reason for this can be seen in this clip at around the 1:53AM PST mark, in which after fading back from black to the news content, the news anchor does not immediately begin speaking. Instead, a stock animation with a music background is shown before the anchor begins speaking. Thus, we can see that we don't want to align the captioning back to the end of the blackframe interval, but rather to the start of the first human speech following that interval. (Though in practice this might need to be tweaked if there was a voiceover during the music).
Using FFMPEG's "showspectrumpic" we can visualize the audio channel during the twenty seconds around this transition:
time ffmpeg -i ./VIDEO.mp4 -lavfi "aselect=between(t\,3230\,3250),asetpts=PTS-STARTPTS,showspectrumpic=s=4024x1024" spectrogramzoom.png
This yields the following image in seconds starting from 3230 seconds into the video:
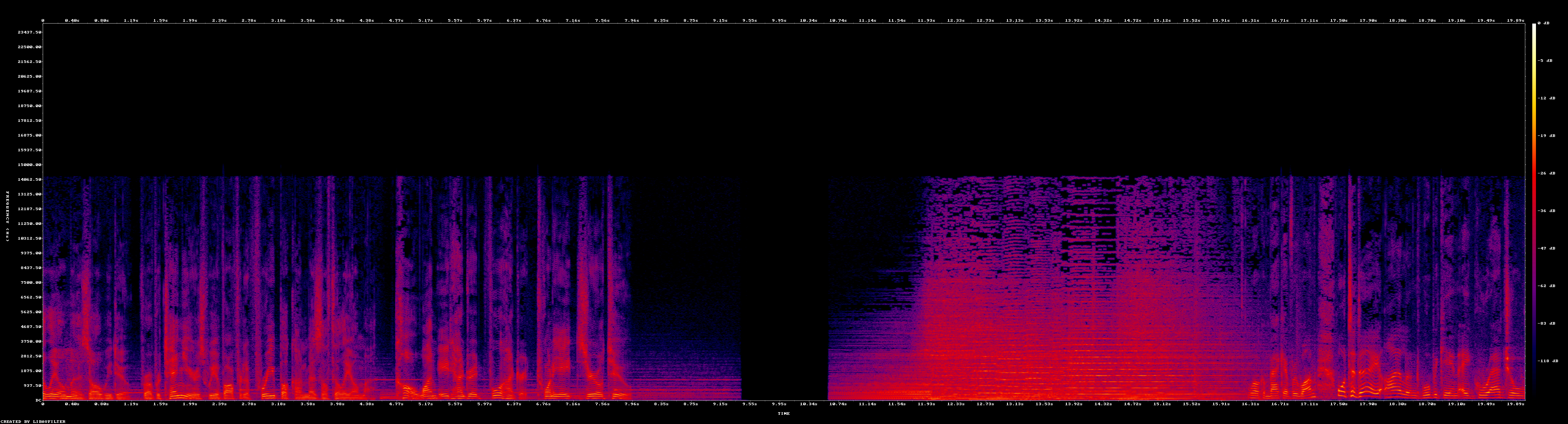
The fade-to-black and then silent period can be seen, as well as the fade-from-black following it. The music follows from 12s to around 16s. This image makes clear why synchronizing the captioning to the blackframe interval is leading us astray.
Yet look closely at the image above and the tell-tale signs of human speech are seen beginning around 16.2s into this block (at video offset 3246). This is where we want to align the captioning to, not to the end of the blackframe interval. Doing so would align this caption block to 3246 seconds whereas the ASR places it at 3245. In this case it is likely that the ASR postprocessing rounded it backwards from the actual fractional second reported by the ASR system which would align what is seen above.
Thus, we end up with a three-stage pipeline. First we scan the video file for blackframe intervals and the closed captioning file for the captioning mode information. We then align each commercial break return with the nearest blackframe interval. We then search forward from that blackframe interval for the beginning of sustained human speech (searching for sustained speech avoids prematurely aligning against a "This is CNN"-style stock clip). Systematically identifying human speech robustly can be done through a number of algorithms that have reasonable and scalably tractable runtimes. Most importantly, this approach avoids the need for the enormous expense of ASR if there is a need only for coarse alignment. In fact, using the spectrograph above it may be possible to perform alignment at a far higher resolution by looking for speech pauses and cadence that correspond to the syllable structure of the captioning.
For those interested in what the entire spectrum graph for the entire broadcast looks like, it can be generated with:
ffmpeg -i ./VIDEO.mp4 -lavfi showspectrumpic=s=6024x1024 spectrogram.png
Yielding the image below:

We're excited to see the kinds of new research questions that become possible through these more sophisticated audio assessments of television news!