A new paper by researchers at Wuhan University, NVIDIA and the University of Macau:
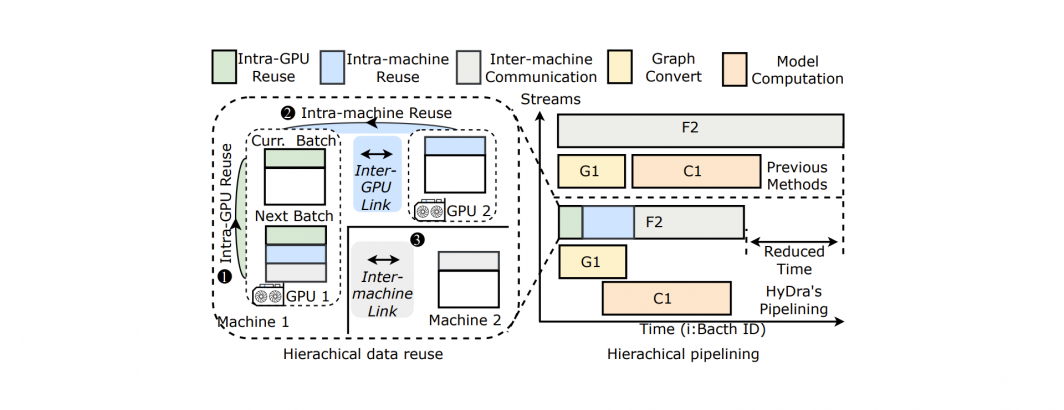
Efficient training of Graph Neural Networks (GNNs) on billion-edge graphs poses significant challenges due to memory constraints and data transfer bottlenecks, particularly affecting GPU-based sampling. Traditional methods either face severe CPU-GPU data transfer bottlenecks or encounter excessive data shuffling and synchronization overheads in multi-GPU setups. To overcome these challenges in GNN training on large-scale graphs, we introduce HyDRA, a pioneering framework that elevates mini-batch, sampling-based training. HyDRA innovates in multi-GPU memory sharing and multi-node feature retrieval, transforming cross-GPU sampling by seamlessly integrating sampling and data transfer into a single kernel operation. It develops a hybrid pointer-driven data placement technique to enhance neighbor retrieval efficiency, designs a targeted replication strategy for high-degree vertices to reduce communication overhead, and leverages dynamic cross-batch data orchestration with pipelining to minimize redundant data transfers. Evaluated on systems equipped with up to 64 A100 GPUs, HyDRA significantly outperforms current leading methods, achieving 1.4x to 5.3x faster training speeds compared to DSP and DGL-UVA and demonstrating up to a 42x improvement in multi-GPU scalability. HyDRA sets a new benchmark for high-performance GNN training at large scales.