On Monday, we explored how BigQuery can be combined with Bigtable to create a digital twin over a vast GCS video archive totaling 4.1M global broadcasts in 150 languages spanning 50 countries over nearly a quarter century totaling 10.9 billion seconds (182M minutes / 3M hours) of news programming and 1 quadrillion pixels analyzed by the Visual Explorer. How much disk does all of this content occupy? While we could trivially answer such a question using GCS' built-in capabilities, one of the key benefits of using our Bigtable-based digital twin and BigQuery is that we can incorporate and filter by a wealth of additional rich metadata about each video, allowing us to construct customized rollups around any filter criteria using standard SQL. Let's see what this looks like in practice.
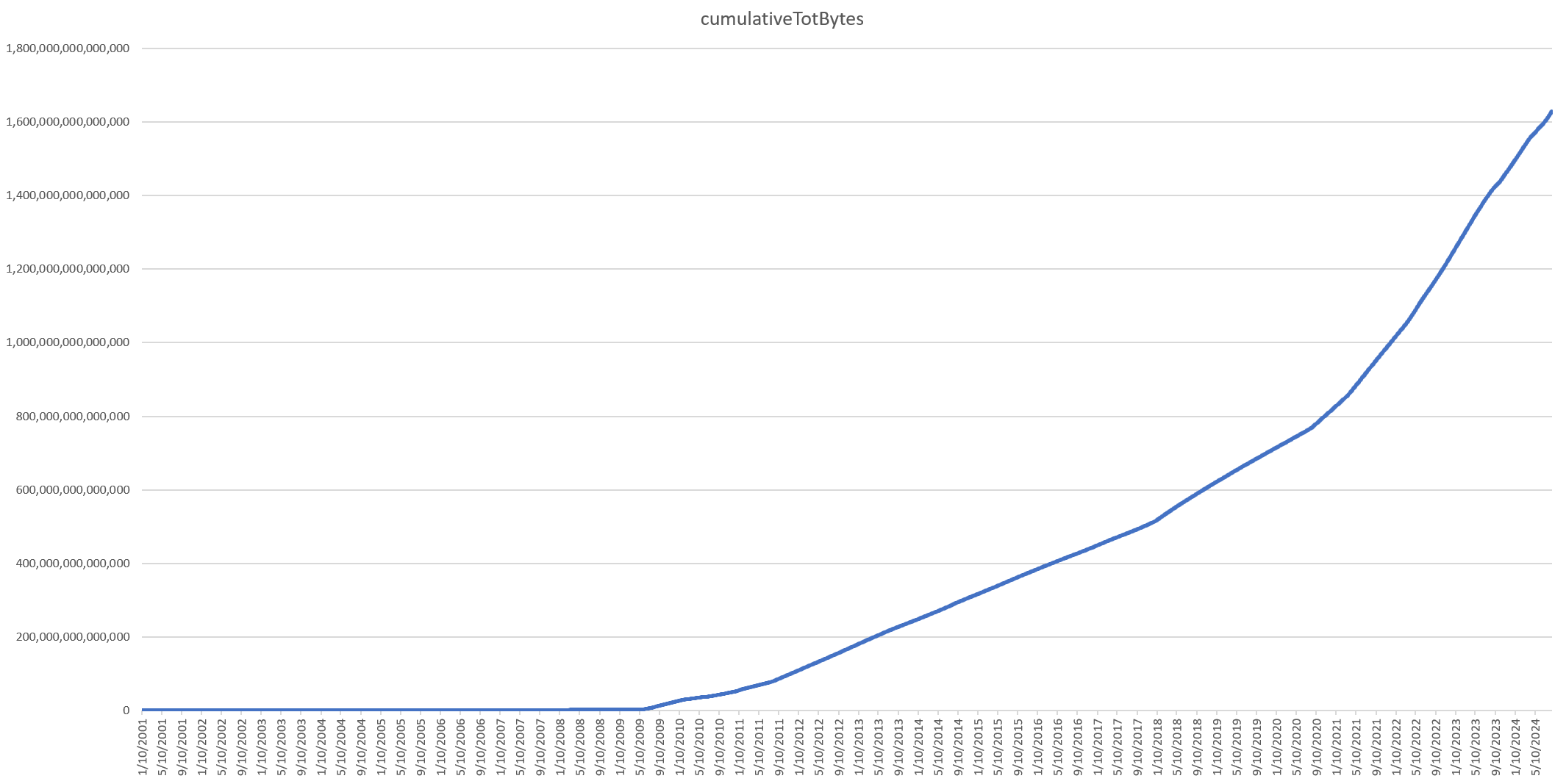
Using just a single SQL statement, we were able to use BigQuery's powerful JSON parsing and statistical aggregation capabilities to generate a summarized timeline of total GCS storage usage from our Bigtable digital twin in just a few minutes. In all, the total archive of 3 million hours of news programming totals 1.623PB of disk.
To assess total storage usage, we'll use our same SQL query as before and just add an aggregation over filesize:
SELECT DATE, COUNT(1) totShows, ROUND(SUM(sec)) totSec, ROUND(SUM(bytes)) totBytes, ROUND(SUM(pixels)) totVEPixels from (
select FORMAT_DATE('%m/%d/%Y', PARSE_DATE('%Y%m%d', substr(rowkey, 0, 8) )) AS DATE,
CAST(JSON_EXTRACT_SCALAR(DOWN, '$.durSec') AS FLOAT64) sec,
CAST(JSON_EXTRACT_SCALAR(DOWN, '$.sizeBytes') AS FLOAT64) bytes,
(
(CAST(JSON_EXTRACT_SCALAR(DOWN, '$.durSec') AS FLOAT64) / 4) *
CAST(JSON_EXTRACT_SCALAR(DOWN, '$.height') AS FLOAT64) *
CAST(JSON_EXTRACT_SCALAR(DOWN, '$.width') AS FLOAT64)
) AS pixels FROM (
SELECT
rowkey, ( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('DOWN') ) DOWN
FROM `[PROJECTID].bigtableconnections.digtwin`
) WHERE DOWN like '%DOWNLOADED_SUCCESS%' and substr(rowkey, 0, 8) != '00000000'
) group by date order by date
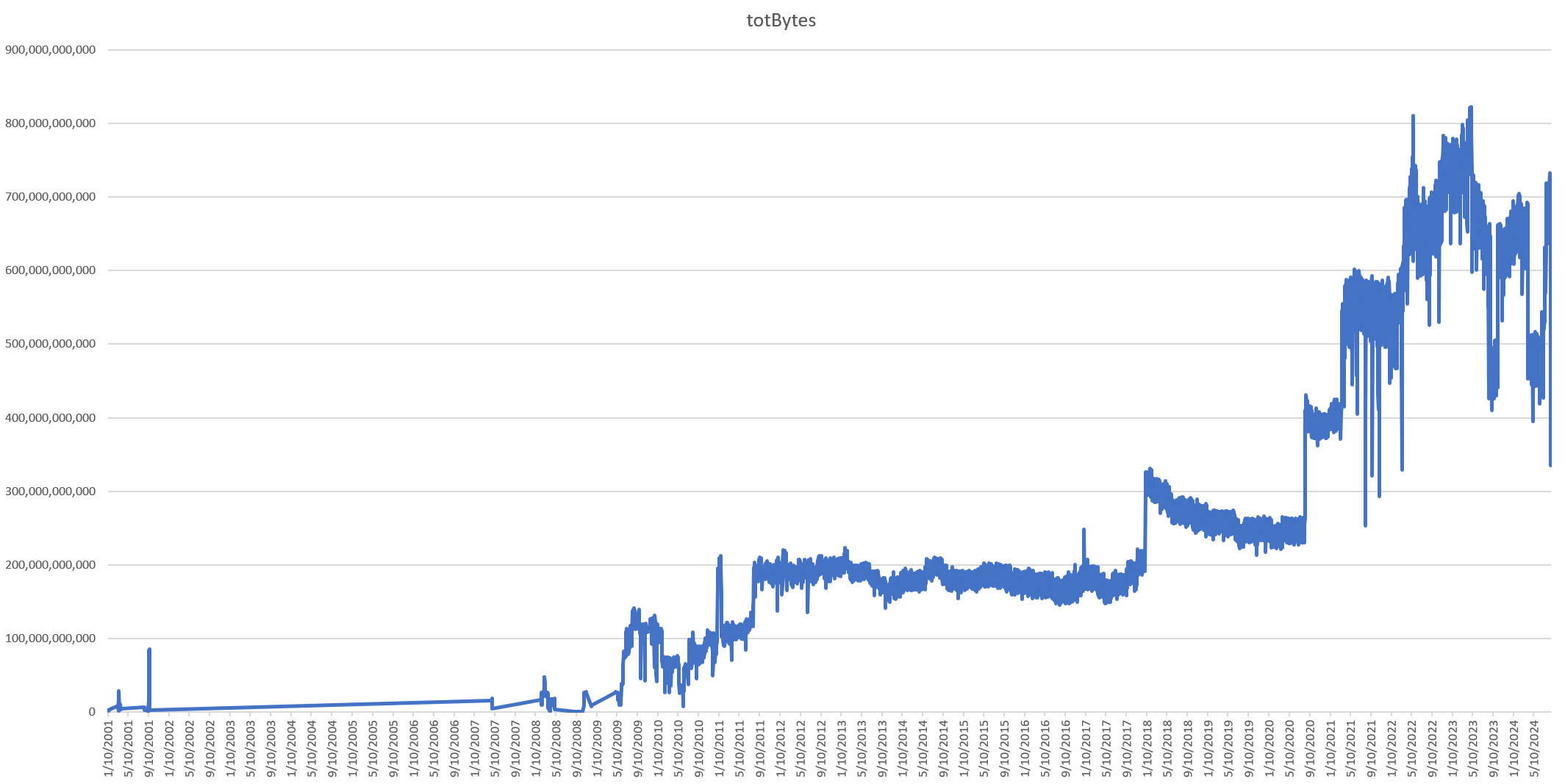
This yields the following graph, showing us that a decade ago the archive was growing by around 200GB per day – a number that has increased to over three quarters of a terabyte per day now, illustrating the tremendous storage requirements of moving video:
Looking at the same timeseries as a cumulative growth total, we see that today the archive sits at around 1.623PB of total video content (not including all related metadata files).