
The Internet Archive's Television News Archive encompasses over 9.5 million broadcasts totaling 6.6 million hours of airtime from 108 television news channels spanning 50 countries and territories in 35 languages and dialects over 20 years on 5 continents. The launch of the Visual Explorer last June has driven home the immense power of this vast and singular global archive of visual storytelling in allowing journalists and scholars to "see" global events in unprecedented new ways, such as reporting on the parallel domestic Russian media landscape being used to support its invasion of Ukraine or how the Iranian government has reframed women's rights protests. As researchers have increasingly realized the incredible potential of this vast archive to understand local events through local eyes across the world and especially to capture domestic visual narratives and portrayals, we've heard loud and clear the desire to replicate this kind of television news monitoring on-the-fly in response to breaking events. For example, imagine being able to monitor Cuban television as the protests began or Indian channels in the aftermath of assaults in Manipur or Afghan broadcasters as the US began withdrawing or instantly monitoring Nigerien and all major regional channels across neighboring countries in the opening hours of the coup? The ability to instantly and trivially begin monitoring channels from across the planet at the first glimmer of unfolding events is a capability that simply has not existed at scale for journalists and scholars – until now. Today we are excited to unveil a pipeline wrapped around yt-dlp that allows it to be used in precisely these kinds of "instant on" streaming monitoring environments, with full optional integration with the GCP cloud environment to leverage continuous 24/7 state of the art multilingual OCR (onscreen text recognition) and ASR (speech recognition and transcription) of the monitored channels.
Historically, television news monitoring was possible only through physical hardware capture systems connected to coaxial and satellite television receivers. Today, more and more television channels across the world are offering live streaming of their coverage, in whole or in part, in order to maximize the global reach of their messages. Open source tools like yt-dlp make it possible to monitor these video streams, but offer such a rich array of options that it can be difficult to know how to most effectively deploy them or that they can do things like monitor captioning on select channels. Critically, few provide effective stream monitoring capabilities with the ability to monitor a 24/7 stream and split it into an endless stream of one minute discrete MP4 files to allow live analysis and error protection or integrate with cloud AI APIs.
To address this, today we are releasing a toolkit that wraps around yt-dlp or other video interface packages and situates them in the modern cloud ecosystem for complete AI analysis. At its core is the powerful open source yt-dlp package that provides support for more than 1,800 different video hosting platforms. To analyze the monitored content, wrappers are provided for GCP's Cloud Video AI API (for onscreen text OCR) and GCP's Cloud Speech To Text API (for ASR), both supporting a large array of languages.
The toolkit can be used in two different monitoring modes:
- Static Video Monitoring. In this mode, it is given the URL of a standalone (non-streaming) hosted video on a platform like YouTube and uses yt-dlp to download it, preconfiguring with the options we have found to be most useful to download the video and (for supported platforms) associated closed captioning as an MP4 and VTT file direct to local disk. Thus, handed the URL of a YouTube video it will download it directly to an ondisk MP4 file. Downloading the video to a local MP4 file can be run on any Linux computer. If run on the GCP cloud environment, three additional options are available: mirroring to GCS and OCR and ASR via GCP's AI APIs. The integration with GCP AI APIs is completely turnkey, meaning you simply enable those APIs and can request OCR or ASR analysis selectively for each monitored channel. The scripts could also be modified to integrate with other cloud platform APIs using them as a template.
- Streaming Video Monitoring. This mode showcases the real power of the toolkit. Given the URL of a streaming video on a platform like YouTube, it monitors the strean 24/7, automatically recovering from stream errors and chops the stream into a perpetual stream of one minute MP4 files on disk by combining open source packages yt-dlp and ffmpeg. In monitor-only mode it can be run under any Linux environment. If run on the GCP cloud environment, the same options as above are available (GCS mirroring, OCR and ASR) and it automatically manages all of the workflow of applying the requested analytic features to each of the sharded one minute files.
Using the toolkit is incredibly simple. First download the scripts and install the required supporting libraries (requires Linux):
apt-get -y update apt-get -y upgrade apt-get -y install ffmpeg apt-get -y install python3-pip python3 -m pip install -U yt-dlp mkdir /VIDCAPTURE/ cd /VIDCAPTURE/ mkdir VIDEOS mkdir VIDEOS_STREAMING wget https://storage.googleapis.com/data.gdeltproject.org/blog/2023-tvnewsstreammonitoring/vidcap_downloadsinglevideo.pl wget https://storage.googleapis.com/data.gdeltproject.org/blog/2023-tvnewsstreammonitoring/vidcap_downloadstreamingvideo.pl wget https://storage.googleapis.com/data.gdeltproject.org/blog/2023-tvnewsstreammonitoring/vidcap_ocrvideo.pl wget https://storage.googleapis.com/data.gdeltproject.org/blog/2023-tvnewsstreammonitoring/vidcap_asrvideo.pl chmod 755 *.pl
To utilize the GCP-specific features (GCS, ASR, OCR), you'll need to run on a GCP GCE VM with the gcloud/gsutil tools installed and enable the necessary APIs in the GCP project. In a production environment you'll also want to rerun "python3 -m pip install -U yt-dlp" periodically to update to the latest version with the latest integration updates.
To download a static video on any Linux system (not using the GCP-specific features) is as simple as:
./vidcap_downloadsinglevideo.pl --filename="./VIDEOS/Bonferey-8-17-2023.mp4" --url="https://www.youtube.com/watch?v=So0oBsB7CsI"
In this case we're downloading this Nigerien Bonferey TV broadcast and saving it to an MP4 file on local disk named "Bonferey-8-17-2023.mp4". That's literally all there is to it. The "filename" parameter tells it where to download the file to on local disk and URL is the URL of the video to download.
You'll end up with the following two files in the ./VIDEO/ subdirectory:
-rw-r--r-- 1 user user 92K Aug 20 15:18 NigerNews-8-17-2023.en.vtt -rw-r--r-- 1 user user 54M Aug 18 19:10 NigerNews-8-17-2023.mp4
The MP4 file is a standalone MP4 video file. In this case, the broadcast had an associated VTT captioning file. While the VTT format is not the easiest to parse, there are numerous tools that can convert it to other formats:
WEBVTT Kind: captions Language: en 00:00:07.580 --> 00:00:16.070 align:start position:0% [Music] 00:00:16.070 --> 00:00:16.080 align:start position:0% 00:00:16.080 --> 00:00:19.910 align:start position:0% good <00:00:16.534>evening <00:00:16.988>thank <00:00:17.442>you <00:00:17.896>for <00:00:18.350>your <00:00:18.804 >loyalty <00:00:19.258>given 00:00:19.910 --> 00:00:19.920 align:start position:0% good evening thank you for your loyalty given 00:00:19.920 --> 00:00:22.810 align:start position:0% good evening thank you for your loyalty given the <00:00:20.279>ordinance <00:00:20.638>number <00:00:20.997>of <00:00:21.356>Mila 00:00:22.810 --> 00:00:22.820 align:start position:0% the ordinance number of Mila 00:00:22.820 --> 00:00:27.529 align:start position:0% the ordinance number of Mila 23-01 <00:00:23.749>of <00:00:24.678>July <00:00:25.607>21, <00:00:26.536>2013 ...
If you wanted to upload the video to GCS and also apply OCR and ASR, you would add the following options:
./vidcap_downloadsinglevideo.pl --filename="./VIDEOS/Bonferey-8-17-2023.mp4" --url="https://www.youtube.com/watch?v=So0oBsB7CsI" --gcs="gs://[YOURBUCKET]/videos/" --asr=fr-FR,latest_long --ocr=yes --upload=yes --proj=[YOURGCPPROJECTID]
This adds a few extra parameters (these must appear with double hyphens in front and quote marks around as needed):
- gcs: This is the complete GCS path (with "gs://" prefix) to upload the video to when download is complete. Note that this is required for OCR/ASR support, since those APIs require the underlying media to exist in GCS, but it can also be used by itself to just upload the MP4 file to GCS.
- asr: If present, enables automatic speech transcription of the broadcast using GCP's Speech To Text API. There are two parameters, separated by commas. The first is the STT API language code for the language spoken in the broadcast. At this time, STT only supports a single language per video, so for broadcasters with code switching, pick the primary language. In this case, the Bonferey broadcast is in French and of the available STT API French dialects, we chose the main France French dialect "fr-FR". The second parameter is the STT API "recognition model" to use. The most accurate is called "latest_long", but not all languages support that. When looking up the language code to use for a broadcast on the STT API languages listing, look whether there is a row for that language with "Latest Long" supported. If not, specify "default" as the model. Also, if you get errors about unsupported features, you may have to modify the "vidcap_asrvideo.pl" script to remove requested ASR features if not supported by the given language. Note that the GCP STT API does not currently support MP4 input natively, so the toolkit automatically creates a FLAC raw audio file extract from the video and uploads it to your GCS path, submits it to the API and then removes the temporary FLAC file when recognition is complete.
- ocr: If present, enables automatic onscreen text recognition in all of the supported Cloud Video OCR languages. Unlike ASR, you don't need to specify what onscreen text languages might appear in the broadcast and multiple simultaneous languages are supported – if English, Arabic, French and Chinese all appear in a single video frame, they will all be transcribed.
- upload: If present, enables automatic upload of the downloaded MP4 file to the specified GCS path. Must be enabled for ASR or OCR support.
- proj: Required for GCS, ASR or OCR support. This is your GCP Project ID (the textual, not the numeric ID).
If you want to just upload the videos to GCS without running OCR or ASR you could use:
./vidcap_downloadsinglevideo.pl --filename="./VIDEOS/Bonferey-8-17-2023.mp4" --url="https://www.youtube.com/watch?v=So0oBsB7CsI" --gcs="gs://[YOURBUCKET]/videos/" --upload=yes --proj=[YOURGCPPROJECTID]
The script may take several minutes to tens of minutes, depending on the length of the broadcast and which features are enabled.
With all of the features enabled, on local disk you'll end up with:
-rw-r--r-- 1 user user 92K Aug 20 15:18 NigerNews-8-17-2023.en.vtt -rw-r--r-- 1 user user 54M Aug 18 19:10 NigerNews-8-17-2023.mp4
And in GCS you'll end up with four files:
470.25 KiB 2023-08-19T20:36:37Z gs://[YOURBUCKET]/videos/NigerNews-8-17-2023.asr.json 91.34 KiB 2023-08-19T20:27:17Z gs://[YOURBUCKET]/videos/NigerNews-8-17-2023.en.vtt 53.83 MiB 2023-08-19T20:27:18Z gs://[YOURBUCKET]/videos/NigerNews-8-17-2023.mp4 11.86 MiB 2023-08-19T20:29:29Z gs://[YOURBUCKET]/videos/NigerNews-8-17-2023.mp4.ocr.json
The ASR file is the raw JSON output of the GCP STT API which looks like:
{
"results": [ {
"alternatives": [ {
"confidence": 0.91890275,
"transcript": "Bonsoir Merci pour votre fidélité vu l'ordonnance à numéro 2000 à 23h01 du 28 juillet 2020 23 portes suspension de la Constitutio
n du 25 novembre à 2010 est créé le Conseil national pour la sauvegarde de la de la partie, il est créée une ordonnance un numéro de Mila 23-0 2 du 28
juillet 2023 portant organisation des pouvoirs à public pendant la période de la Renaissance en question a une valeur constitutionnelle et déterminan
t le mode de fonctionnement le plusieurs institutions de la République à dissoute par les nouvelles autorités du pays à l'heure à prise de pouvoir Abd
elaziz Mamadou",
"words": [ {
"confidence": 0.93855584,
"endTime": "16.700s",
"startTime": "15.500s",
"word": "Bonsoir"
}, {
"confidence": 0.93855584,
"endTime": "17.700s",
"startTime": "16.700s",
"word": "Merci"
}, {
"confidence": 0.93855584,
"endTime": "18.100s",
"startTime": "17.700s",
"word": "pour"
}, {
"confidence": 0.93855584,
"endTime": "18.400s",
"startTime": "18.100s",
"word": "votre"
}, {
"confidence": 0.93855584,
"endTime": "19.200s",
"startTime": "18.400s",
"word": "fidélité"
},
...
And the OCR output is the raw Cloud Video AI API output that looks like:
NigerNews-8-18-2023.mp4.ocr.json
{
"annotation_results": [ {
"input_uri": "/[YOURBUCKET]/videos/NigerNews-8-17-2023.mp4",
"segment": {
"start_time_offset": {
},
"end_time_offset": {
"seconds": 977,
"nanos": 920000000
}
},
"text_annotations": [ {
"text": "des Draits Humains CNDM",
"segments": [ {
"segment": {
"start_time_offset": {
"seconds": 168,
"nanos": 480000000
},
"end_time_offset": {
"seconds": 168,
"nanos": 840000000
}
},
"confidence": 0.84896803,
"frames": [ {
"rotated_bounding_box": {
"vertices": [ {
"x": 0.80156249,
"y": 0.27500001
}, {
"x": 0.94999999,
"y": 0.27500001
}, {
"x": 0.94999999,
"y": 0.31111112
}, {
"x": 0.80156249,
"y": 0.31111112
} ]
},
...
Of course, the real power of this toolkit lies in its ability to perform continuous stream monitoring.
Let's take this Ukrainian channel that streams 24/7 via YouTube.
If we just want to monitor it and ingest to local disk, we can simply use:
./vidcap_downloadstreamingvideo.pl --channelname="UKRAINE-24CHANNELONLINE" --url="https://www.youtube.com/watch?v=hns12gYNRq0"&
Note this time instead of "filename" there is a different parameter: "channelname". The toolkit will begin to monitor the channel and will save it to the local subdirectory ./STREAMING/[CHANNELNAME]/. So, in this case, the MP4 files will be written to "./STREAMING/UKRAINE-24CHANNELONLINE/". The stream is saved into a sequence of MP4 files, one per minute, named as "YYYYMMDDHHMM00.mp4".
You can see below what this looks like. Note how filesizes can range minute-by-minute and experience especially large jumps during program changes on a channel, since one show might have sparse graphics and the other richly detailed moving graphics that require a higher bitrate:
>ls -alh ./STREAMING/UKRAINE-24CHANNELONLINE/ -rw-r--r-- 1 user user 9.1M Aug 22 16:50 20230822164900.mp4 -rw-r--r-- 1 user user 7.6M Aug 22 16:51 20230822165000.mp4 -rw-r--r-- 1 user user 8.0M Aug 22 16:52 20230822165100.mp4 -rw-r--r-- 1 user user 7.0M Aug 22 16:53 20230822165200.mp4 -rw-r--r-- 1 user user 7.2M Aug 22 16:54 20230822165300.mp4 -rw-r--r-- 1 user user 6.6M Aug 22 16:55 20230822165400.mp4 -rw-r--r-- 1 user user 7.2M Aug 22 16:56 20230822165500.mp4 -rw-r--r-- 1 user user 6.5M Aug 22 16:57 20230822165600.mp4 -rw-r--r-- 1 user user 8.6M Aug 22 16:58 20230822165700.mp4 -rw-r--r-- 1 user user 7.8M Aug 22 16:59 20230822165800.mp4 -rw-r--r-- 1 user user 9.6M Aug 22 17:00 20230822165900.mp4 -rw-r--r-- 1 user user 11M Aug 22 17:01 20230822170000.mp4 -rw-r--r-- 1 user user 18M Aug 22 17:02 20230822170100.mp4 -rw-r--r-- 1 user user 20M Aug 22 17:03 20230822170200.mp4 -rw-r--r-- 1 user user 24M Aug 22 17:04 20230822170300.mp4 -rw-r--r-- 1 user user 26M Aug 22 17:05 20230822170400.mp4 -rw-r--r-- 1 user user 14M Aug 22 17:06 20230822170500.mp4 -rw-r--r-- 1 user user 14M Aug 22 17:07 20230822170600.mp4 -rw-r--r-- 1 user user 14M Aug 22 17:08 20230822170700.mp4
What if we want to apply OCR and ASR to the stream? Those parameters remain unchanged from static video monitoring:
./vidcap_downloadstreamingvideo.pl --channelname="UKRAINE-24CHANNELONLINE" --url="https://www.youtube.com/watch?v=hns12gYNRq0" --gcs="gs://[YOURBUCKET]/streaming/" --asr=uk-UA,latest_long --ocr=yes --upload=yes --proj=rapid-strength-490&
The local directory files remain unchanged. It will create a subdirectory under your GCS path named as the channelname and upload all of the files there. You can see the results below. The ASR.json and OCR.json files are in the same format as the examples above.
27 KiB 2023-08-22T13:10:47Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822130900.asr.json 8.95 MiB 2023-08-22T13:10:18Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822130900.mp4 3.29 MiB 2023-08-22T13:11:02Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822130900.mp4.ocr.json 23.89 KiB 2023-08-22T13:11:45Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131000.asr.json 9.73 MiB 2023-08-22T13:11:18Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131000.mp4 3.8 MiB 2023-08-22T13:11:54Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131000.mp4.ocr.json 22.93 KiB 2023-08-22T13:12:43Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131100.asr.json 10.59 MiB 2023-08-22T13:12:19Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131100.mp4 3.26 MiB 2023-08-22T13:13:21Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131100.mp4.ocr.json 16.42 KiB 2023-08-22T13:13:41Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131200.asr.json 19.57 MiB 2023-08-22T13:13:18Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131200.mp4 3.22 MiB 2023-08-22T13:14:06Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131200.mp4.ocr.json 29.84 KiB 2023-08-22T13:14:54Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131300.asr.json 14.48 MiB 2023-08-22T13:14:19Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131300.mp4 4.02 MiB 2023-08-22T13:15:27Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131300.mp4.ocr.json 25.65 KiB 2023-08-22T13:15:46Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131400.asr.json 12.11 MiB 2023-08-22T13:15:19Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131400.mp4 3.47 MiB 2023-08-22T13:15:52Z gs://[YOURBUCKET]/streaming/UKRAINE-24CHANNELONLINE/20230822131400.mp4.ocr.json
What kind of hardware is needed to run the toolkit? For monitoring the single streaming Ukraine channel above, with GCS, ASR and OCR we spun up a standard 4-core N1 (Skylake) VM and gave it an expanded 24GB of RAM for an extra buffering safety margin, though you could likely give it far less memory. For disk it is equipped with a 500GB SSD to enable scaling to a larger number of channels. You can see that monitoring a single 24/7 HD channel on this 4-core N1 24GB RAM VM with a 500GB SSD disk over a 6 hour period it utilized just 5% of the VM's CPU at around 5 IOPs and 500KiB/s disk. Note that since OCR and ASR are being performed using the GCP AI APIs, the only local CPU required is for the ASR script to use ffmpeg to convert each one minute MP4 file to a raw FLAC file and upload to GCS.
Thus, even with all features enabled, monitoring a 24/7 HD channel requires just a tiny fraction of the resources of a small CPU-only VM. In practice, you could likely get away with a 2-core VM, though the FLAC conversion needed for ASR can require momentary bursts of CPU that can be taxing for a 2-core VM. Since the ASR/OCR AI tasks are outsourced, the VM does not require a GPU or other exotic hardware and can run on small CPU-only VMs.
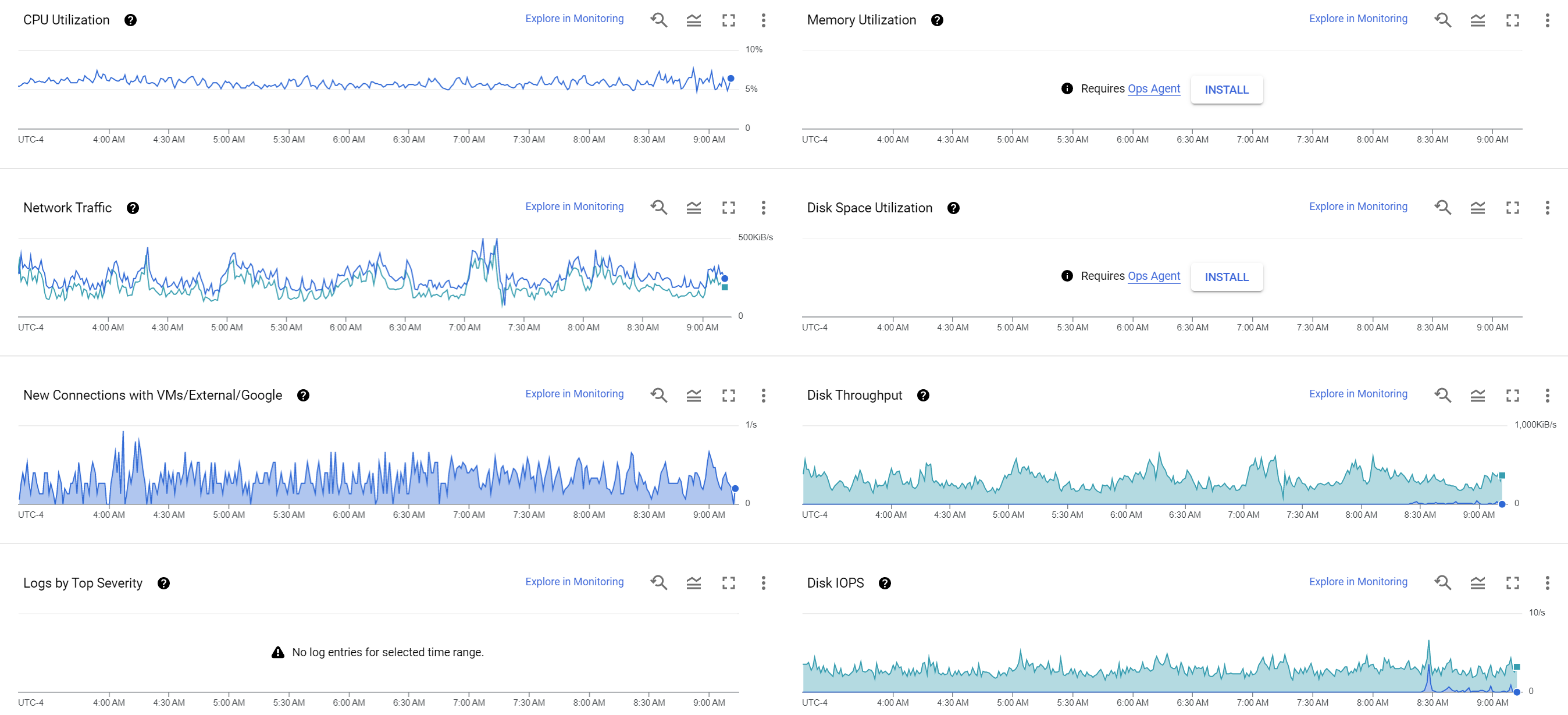
What if you just want to monitor a channel and not perform OCR, ASR or upload to GCS? The graph below shows the results of the same hardware running 30 minutes with GCS/OCR/ASR and 30 minutes with those features turned off (saving to local disk only). When saving to local disk only, CPU requirements averaged only around 0.3%, though network and disk requirements remained the same (other than outgoing network which went to zero).
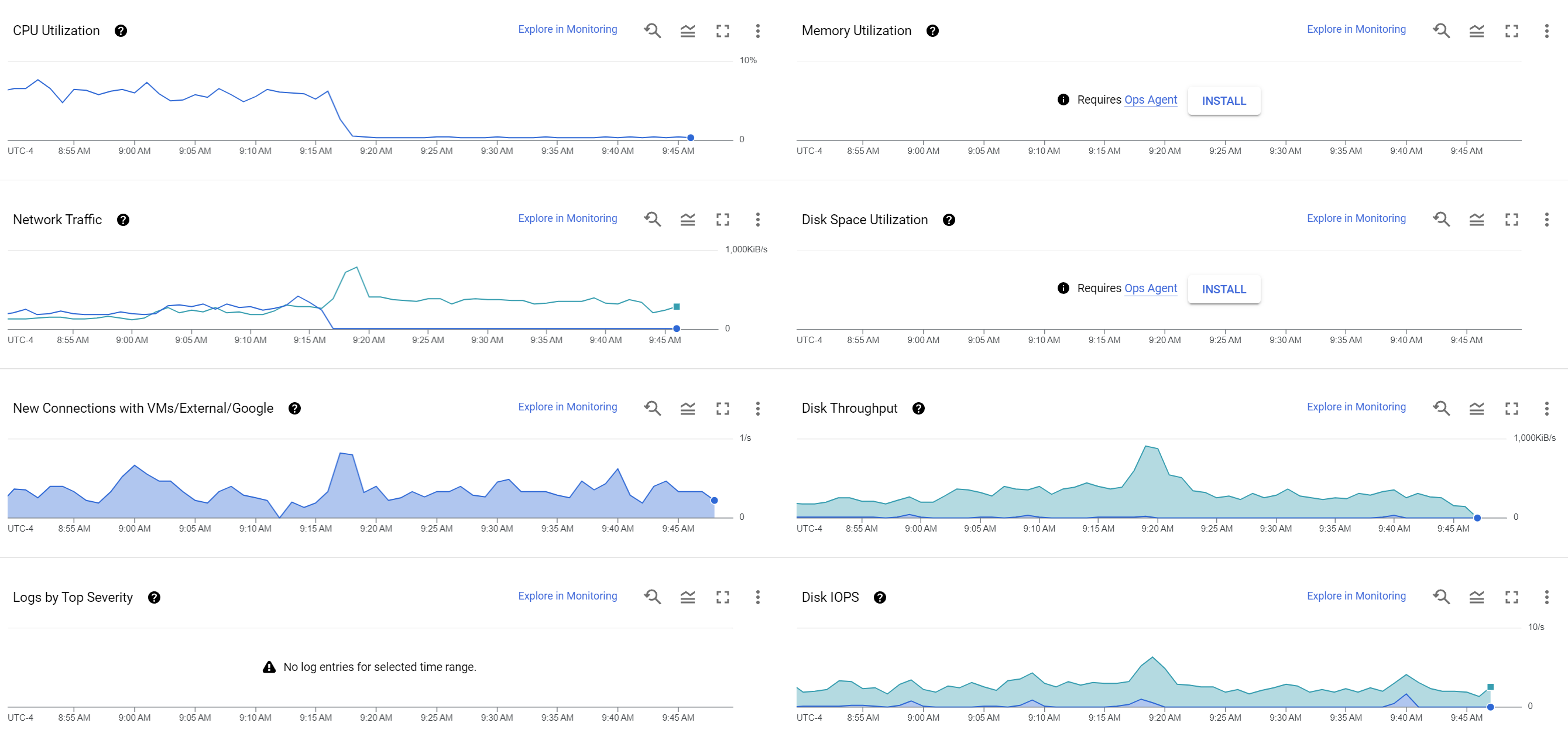
We are tremendously excited to see what kinds of new research and reporting capabilities this toolkit makes possible!