
There are many approaches to exploring television news that includes textual annotation metadata, from closed captioning to OCR-able onscreen text like chyrons. Yet, historical and international television news coverage often lacks such annotations, making at-scale analysis challenging. Many forms of analysis involve visual assessment, such as cataloging appearances of world leaders, inventorying the visual imagery used to depict a major event or measuring studio versus in-the-field footage. In contrast, television news is in the form of infinite linear video streams. These streams can be chopped into discrete clips, but the fast-paced coverage of television news makes it extremely difficult to rapidly survey a channel's coverage to understand how it is framing events from global to local.
To address these issues, one approach with tremendous potential is to split a broadcast into a series of discrete thumbnail images in a grid that essentially summarizes the arc of the broadcast's narratives, from what stories it tells to how it tells those stories. In much the same way that word frequency histograms (ngrams) permit at-scale non-consumptive understanding of the spoken word topical focus of television news, these "visual ngrams" similarly non-consumptively summarize the visual arc of a broadcast. Perhaps most importantly, they can be applied to any broadcast, rendering searchable even broadcasts that lack any form of extractable text or where spoken content is in a language for which current AI speech recognition ASR models don't yet exist or are less accurate.
For at-scale human analysis, a thumbnail sheet representing one frame every 2-3 seconds of a broadcast captures the majority of the broadcast's emphasis while permitting a human analyst to rapidly skim an entire 30 minute broadcast in between 5 to 10 seconds at speed to assess its core contents or search for specific storylines or visual narratives. In the space of just 4-8 minutes, a single person could "watch" an entire day's worth of broadcasts, skimming 24 hours of footage to inventory its coverage.
What might this look like in practice and how do various methods of generating thumbnail images for a broadcast compare?
To examine these questions, we are going to look at a broadcast on Russian state television channel RUSSIA1 from April 5, 2022 from 1-1:30PM MSK covering the invasion of Ukraine that contains a range of elements, including wide-angle and closeup studio commentary, war footage, footage of Russian and Ukrainian combatants, Ukrainian President Volodymyr Zelenskyy and Russian officials. It also contains a survey of Western media coverage of the war and footage of National Security Advisor Jake Sullivan and US Representative Marjorie Taylor Greene. This collage of rapidly-paced footage, ranging from studio camera footage to hand-held cameras whose videographers are running at speed through combat zones, offers an ideal testbed to explore how each approach copes with each type of content.
To create the thumbnails, we use the open source tool "ffmpeg."
Fixed Frame Rate
The simplest and most representative preview mechanism is to generate a fixed framerate preview that samples the video every X seconds. In this case, the broadcast lasts 30 minutes (1,800 seconds), so with a column size of 6 frames and a bit of extra margin, we use a grid of 6×310 frames:
time ffmpeg -i ./VIDEO.mp4 -vf "fps=1,scale=160:-1,tile=6x310" -frames:v 1 -qscale:v 3 THUMBNAILS.jpg > /dev/null 2>&1 < /dev/null&
If we specified too many rows, we can trim the excess blank space on the bottom using ImageMagick (you may have to adjust its default limits on your system if you receive an error about the image being too large):
time convert THUMBNAILS.jpg -define trim:edges=south -trim THUMBNAILS.jpg
How did we pick 6 frames across? This works out to a width that is easily scannable by the human eye without requiring horizontal movement (lessening eye fatigue) and fits well even on smaller monitors. While there is no empirical basis for this specific value, we experimented with a range of values that seemed to be most comfortable and allowed for the most rapid eye scanning of content.
This generates an enormous grid of 1,800 frames stacked in an image that is 960 pixels wide and 27,900 pixels long. In fact, it is so large that many image tools will refuse to process it under their default settings. While it captures the most representative view of the video, it is so large that it is difficult to work with. Importantly, since it uses a fixed frame rate, it will often land on a frame that is in the middle of sweeping rapid motion, leading to blurred frames.
- View 1FPS Preview. (960 x 27900)
{kind=link}
Alternatively, what about a frame every 2 seconds? This requires just half as many frames and should still capture much of the core narrative.
- View 1/2 FPS Preview. (960 x 13860)
{kind=link}
time ffmpeg -i ./VIDEO.mp4 -vf "fps=1/2,scale=160:-1,tile=6x310" -frames:v 1 -qscale:v 3 THUMBNAILS.jpg > /dev/null 2>&1 < /dev/null&
While more manageable, the image is still 13,860 pixels long, making it unwieldly and difficult to rapidly skim. Importantly, there are still numerous blurred frames throughout the video, as seen below (the yellow-highlighted frames).

What about a frame every 10 seconds? This requires just a tenth as many frames and results in an image just 2,801 pixels long, making it quite manageable. While it still summarizes the core narratives of the broadcast, it decimates so much detail that smaller arcs disappear.
- View 1/10 FPS Preview. (960 x 2,801)
{kind=link}
time ffmpeg -i ./VIDEO.mp4 -vf "fps=1/10,scale=160:-1,tile=6x310" -frames:v 1 -qscale:v 3 THUMBNAILS.jpg > /dev/null 2>&1 < /dev/null&
What about every 30 seconds? This results in a highly compact view of the broadcast, but eliminates so much detail that only the coarse macro narrative arc remains.
- View 1/30 FPS Preview. (960 x 993)
{kind=link}
time ffmpeg -i ./VIDEO.mp4 -vf "fps=1/30,scale=160:-1,tile=6x310" -frames:v 1 -qscale:v 3 THUMBNAILS.jpg > /dev/null 2>&1 < /dev/null&
Finally, what about every 60 seconds? This summarizes the entire broadcast in just 5 rows, but makes the narrative focus of the broadcast almost unintelligible.
- View 1/60 FPS Preview. (960 x 545)
{kind=link}
time ffmpeg -i ./VIDEO.mp4 -vf "fps=1/60,scale=160:-1,tile=6x310" -frames:v 1 -qscale:v 3 THUMBNAILS.jpg > /dev/null 2>&1 < /dev/null&
I-Frames
Compressed videos contain intra-coded frames (I-frames) that represent self-contained images that act essentially as "key frames" in a video. This results in a relatively compact view of the video, but the frames exhibit substantial compression artifacts, rendering some unintelligible and making it difficult to discern fine detail. Not all narrative sequences are included or key portions are missing, making it difficult to understand their significance.
- View I-Frame Preview. (960 x 2,801)
{kind=link}
time ffmpeg -i ./VIDEO.mp4 -vf "select='eq(pict_type,PICT_TYPE_I)',scale=160:-1,tile=6x92" -vsync vfr THUMBNAIL.jpg > /dev/null 2>&1 < /dev/null&
Scene Detection
Looking at the sequences above, there are often long camera shots in which little changes (such as a person talking to the camera). What if we could compare each frame to the one before it and only generate thumbnails when there is a substantial "scene change" in the video? FFMPEG supports this natively via its "select" and "scdet" filters, allowing us to trivially set the differencing threshold.
You can use scdet as:
time ffmpeg -f lavfi -i "movie=VIDEO.mp4,scdet=s=1:t=10" -vf "scale=160:-1,tile=6x80" -frames:v 1 -qscale:v 3 THUMBNAIL.jpg
In this case we will use select to compile all frames that were at least 20% different from the previous frame:
- View 20% Scene Change Preview. (960 x 8,280)
{kind=link}
time ffmpeg -i ./VIDEO.mp4 -vf "select='gt(scene,0.2)',scale=160:-1,tile=6x92" -frames:v 1 -qscale:v 3 THUMBNAIL.jpg > /dev/null 2>&1 < /dev/null&
This yields long sequences of images during periods of fast motion, but collapses minutes of fixed-camera airtime into a single frame. For example, the brief scene below comes a lengthy sequence of largely blurry images depicting its fast-paced motion:

In contrast, more than a minute of studio time featuring Marjorie Taylor Greene is collapsed to a single frame, highlighted below:

In the context of television news, scene detection is essentially "motion detection," flagging long sequences of motion. Yet, even here many key scenes are underrepresented or missing entirely. Thus, it can be useful as a way of scanning broadcasts for sequences of fast-paced camera motion, but results in a representation that collapses time in a way that makes it more difficult to understand how much attention each narrative sequence received. For example, looking at the two sequences above, the combat sequence would appear to have occupied a much longer portion of the broadcast than Greene's brief cameo appearance, but in reality Greene was onscreen for far longer than the combat skirmish.
The difference is even more stark when using a 10% difference threshold:
- View 10% Scene Change Preview. (960 x 17,370)
{kind=link}
time ffmpeg -i ./VIDEO.mp4 -vf "select='gt(scene,0.1)',scale=160:-1,tile=6x92" -frames:v 1 -qscale:v 3 THUMBNAIL.jpg > /dev/null 2>&1 < /dev/null&
This is halfway between our 1fps and 2fps fixed framerate previews in terms of vertical size, but is a poorer macro-level representation in that it overemphasizes brief bursts of rapid motion and underemphasizes long periods of fixed camera time.
Alternatively, a more typical value for the change threshold might be 40%, resulting in a much smaller file, but which omits numerous key narratives, including the appearance of Greene:
- View 40% Scene Change Preview. (960 x 3,345)
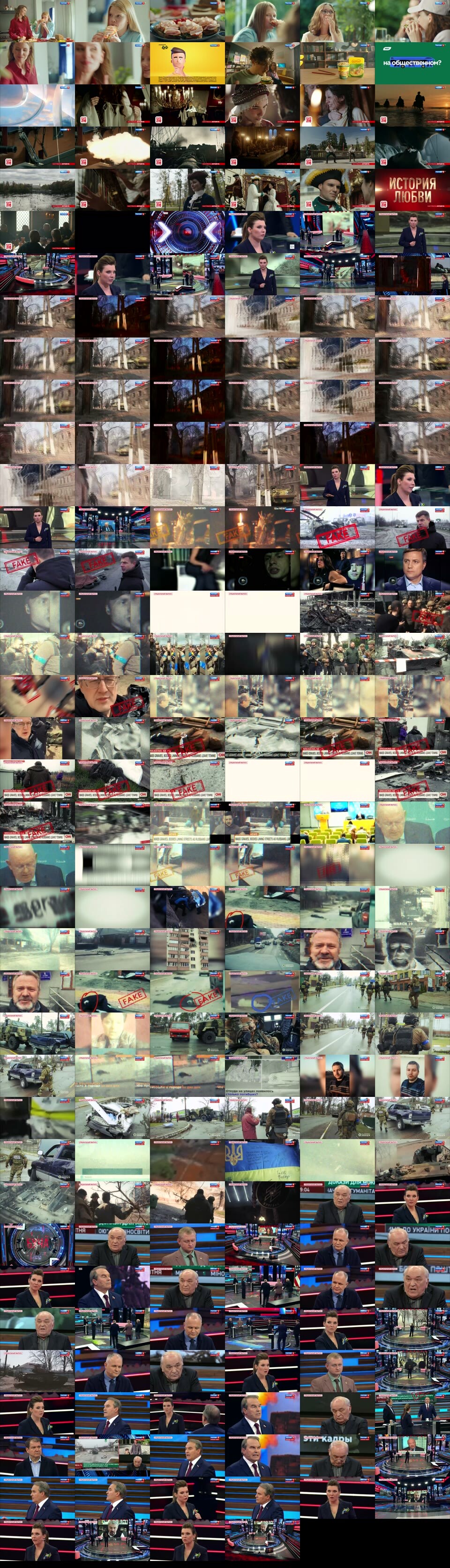{kind=link}
Given its sensitivity to rapid motion, one useful application of scene detection is to output the timestamps at which scene changes are detected and use these as a metadata enrichment recording the level of motion through the broadcast.
This can be done through the "showinfo" filter:
time ffmpeg -i ./VIDEO.mp4 -vf "select='gt(scene,0.10)',showinfo" -f null - 2> ffout& grep showinfo ffout | grep pts_time:[0-9.]* -o > timestamps wc -l timestamps
Or the more compact "metadata" filter:
time ffmpeg -i ./VIDEO.mp4 -filter_complex "select='gt(scene,0.1)',metadata=print:file=./time.txt" -f null - > /dev/null 2>&1 < /dev/null& grep pts_time time.txt | wc -l
Thus, in the context of television news, scene detection appears to be more useful as a "camera speed" annotation metric that can be used to record the speed of camera change second-by-second through the broadcast, rather than as a broadcast previewing mechanism.
Representative Frame Selection
Finally, FFMPEG includes a built-in thumbnail generation filter that batches the video into sequences of 100 frames and for each batch computes the color histogram of each frame, averages them together to derive the average histogram of that sequence, then selects the frame that is closest to the average and thus most "representative" of that sequence of frames. This enhances the temporal representativeness of the fixed frame rate previews by largely filtering out isolated interstitial frames or motion bursts, ensuring that for each sequence of 100 frames, the thumbnail selected best represents the imagery of that sequence.
This particular broadcast was monitored at 25fps, meaning that each sequence of 100 frames will represent 4 seconds of airtime.
- Representative Frame Selection Preview. (960 x 7,024)
{kind=link}
time ffmpeg -i ./VIDEO.mp4 -vf "thumbnail,scale=160:-1,tile=6x92" -frames:v 1 -qscale:v 3 THUMBNAIL.jpg > /dev/null 2>&1 < /dev/null& time convert THUMBNAIL.jpg -define trim:edges=south -trim THUMBNAIL.jpg
And you can export the list of matching timestamps:
time ffmpeg -i ./VIDEO.mp4 -vf "thumbnail" -f null -
Which yields output like the following, showing the timestamps:
[Parsed_thumbnail_0 @ 0x5557646af640] frame id #26 (pts_time=1.040000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #73 (pts_time=6.920000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #72 (pts_time=10.880000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #64 (pts_time=14.560000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #42 (pts_time=17.680000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #56 (pts_time=22.240000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #89 (pts_time=27.560000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #59 (pts_time=30.360000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #51 (pts_time=34.040000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #30 (pts_time=37.200000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #93 (pts_time=43.720000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #37 (pts_time=45.480000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #79 (pts_time=51.160000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #50 (pts_time=54.000000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #25 (pts_time=57.000000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #18 (pts_time=60.720000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #17 (pts_time=64.680000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #36 (pts_time=69.440000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #50 (pts_time=74.000000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #90 (pts_time=79.600000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #33 (pts_time=81.320000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #53 (pts_time=86.120000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #63 (pts_time=90.520000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #41 (pts_time=93.640000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #20 (pts_time=96.800000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #67 (pts_time=102.680000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #9 (pts_time=104.360000) selected from a set of 100 images [Parsed_thumbnail_0 @ 0x5557646af640] frame id #58 (pts_time=110.320000) selected from a set of 100 images ...
In essence, the filter above is taking every 4 seconds of video and selecting the frame that "best" represents those seconds of airtime. What if we instead simply used a fixed frame rate of every 4 seconds to compare?
- View 1/4 Fps Preview. (960 x 7,025)
{kind=link}
time ffmpeg -i ./VIDEO.mp4 -vf "fps=1/4,scale=160:-1,tile=6x90" -frames:v 1 -qscale:v 3 THUMBNAIL.jpg > /dev/null 2>&1 < /dev/null&
The result is largely identical to the "representative" frame selection above in terms of the overall narrative arc it captures. Frames largely correspond between the two in terms of what they capture. The major difference is that the representative frame selector chooses fewer blurred or interstitial frames and qualitatively often selects a slightly better framing of a given scene, though the two are extremely similar and there are a few cases where the fixed fps version might intuitively better match what might be expected. The representative version takes around 5m2s on a single-core VM, while the fixed framerate version takes 2m40s, so computationally it is roughly twice as slow.
Conclusions
We invite you to compare the images above to see which you think offers the best representation of the broadcast's macro-level narrative arcs. Each presents a different set of tradeoffs along the continuum from maximal coverage with overwhelming detail to lesser coverage with more a more manageable image size. Subjectively, I-frame filtering appears to yield the least-representative and lowest-quality representation, while scene detection is more useful for measuring the level of camera movement through a broadcast than it is in creating a useable visual summary. In the end, fixed framerate and representative frame selection approaches appear to yield the best result, with representative selection offering slightly better results in most cases, though not all, and at a 2x factor increased computational load.
Stay tuned for more comparisons!