
Large language models are increasingly being positioned as a wholesale replacement for nearly all language analysis tasks, from Q&A and translation to more mundane tasks like classification, entity extraction and sentiment. How does classical neutral entity extraction compare with modern LLM-driven entity recognition and do LLMs exhibit superior results in identifying and normalizing entities, especially given their superior outputs in other tasks like translation? The findings below show that LLMs actually perform significantly poorer than classical neural entity extractors like Google's NLP API at both extraction and normalization tasks. LLMs must often be run multiple times over the same passage, yielding different results each time, before one of the outputs is the correct one. Normalization frequently hallucinates the wrong normalized form, while extraction often reverts to clause extraction rather than entity isolation. LLMs struggle to recognize even heads of state across the world, are tripped up by the romanization common to news reporting (thus biasing them against cultures where names include diacritics or have a primary language other than English) and will randomly miss even omnipresent names like President Biden in English reporting. Overall, the findings here suggest that LLMs are not yet ready for use in production entity extraction workflows and that one of the most likely reasons for their poor performance is their inability to incorporate the kinds of realtime-updating knowledge graphs that enterprise entity recognizers rely upon for disambiguation and normalization. Most challenging is the fact that traditional LLM external memories (ANN embedding search) is not applicable to entity resolution in that even the entity extraction process below fails to correctly isolate entities to the point that a two-step extraction and embedding search could be used to generate a subsequent prompt containing a list of possible entities for disambiguation – not to mention the fact that the number of possible entities sharing many common names would vastly exceed the available input token space and attention of modern LLMs. The end result is that LLMs are not yet suitable for production entity extraction workloads and this raises questions about the suitability of LLMs to many similar kinds of codification workflows that require the use of realtime-updating normalization tasks.
While translation, classification and sentiment do require models capable of being updated over time as language changes, they typically are able to rely more heavily on surrounding context with the exception of specific emergent specialized terms that are fairly rare and can typically be appended in realtime via expansion glossaries. For example, when "Covid-19" emerged, many languages simply adopted it as an English loanword, allowing machine translation models to simply pass it through as-is, while for those that created new words for it, NMT applications could simply be updated through their glossary facilities, without requiring the model itself to be updated. Entity recognition, on the other hand, relies on two processes: extracting the list of named entities from the text and then normalizing those entity mentions to a standardized representation.
Entity extraction can typically lean on slow-changing linguistic context. While the possible contexts in which a human person can be mentioned do evolve over time, typically the underlying grammatical cues that suggest a person mention are relatively slow-changing, meaning a model trained in 2021 can still recognize most mentions of person names in the year 2023.
In contrast, entity normalization requires a constantly-updating database that connects all of the various forms of a name to a common identifier. Take for example a mention of "Joe Biden announced today a new policy towards China." Any entity extractor today can identify and extract "Joe Biden" as a person mention. Similarly, if another article mentions "Biden announced" and another "President Biden announced", any extractor could identify "Biden" and "President Biden" as their respective person entities. These three articles would, respectively, yield "Joe Biden", "Biden" and "President Biden" as their constituent person entities. So far, so good.
The problem is that with only a list of three names: "Joe Biden", "Biden" and "President Biden", the machine has no information telling it that these three names refer to the same person. Thus, a search for "President Biden" would not return "Joe Biden" or "Biden" and a search for "Joe Biden" would not return "Biden" or "President Biden" because the machine does not know that they all refer to the same underlying person.
The process for connecting all of the various forms of a name to a common representation is called "normalization". Normalization can function in various ways, but in most enterprise systems it involves mapping name variants to an underlying common identity code. For example, in the Google Enterprise Knowledge Graph, "Joe Biden", "Biden" and "President Biden" in the context of referring to the US President would all be resolved to a common identity code of "/m/012gx2" which is Google's unique identifier (called a "Cloud Knowledge Graph machine ID or "MID" code) for Joe Biden.
The problem with normalization is that it requires a continually updated knowledgebase of information about the world's entities. Using context alone, a sentence saying "Paris is a wonderful place to visit" can be assumed to refer to a location, while "Paris' latest song dropped today" can be assumed to refer to either a person or organization. But, only with an external knowledgebase can the latter be resolved to "Paris Hilton".
What does this process look like in real life? Using Google's Cloud Natural Language AI API, let's annotate a sample sentence via gcloud's ml language CLI:
gcloud ml language analyze-entities --content="President Biden announced today a new policy towards China."
This produces the following output:
{
"entities": [
{
"mentions": [
{
"text": {
"beginOffset": 10,
"content": "Biden"
},
"type": "PROPER"
},
{
"text": {
"beginOffset": 0,
"content": "President"
},
"type": "COMMON"
}
],
"metadata": {
"mid": "/m/012gx2",
"wikipedia_url": "https://en.wikipedia.org/wiki/Joe_Biden"
},
"name": "Biden",
"salience": 0.5953447,
"type": "PERSON"
},
{
"mentions": [
{
"text": {
"beginOffset": 38,
"content": "policy"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "policy",
"salience": 0.3388699,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 53,
"content": "China"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/0d05w3",
"wikipedia_url": "https://en.wikipedia.org/wiki/China"
},
"name": "China",
"salience": 0.06578537,
"type": "LOCATION"
}
],
"language": "en"
}
Notice how it identifies the two entities, lists all of their mentions in the text and then normalizes them to a MID code and provides the URL of the Wikipedia article about them.
What about this variant?
gcloud ml language analyze-entities --content="Biden announced today a new policy towards the Chinese government."
Notice how the NLP API recognizes that Biden in this context likely refers to POTUS and thus converts "Biden" to the same unique identifier as it applied above for "President Biden":
...
{
"mentions": [
{
"text": {
"beginOffset": 0,
"content": "Biden"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/012gx2",
"wikipedia_url": "https://en.wikipedia.org/wiki/Joe_Biden"
},
"name": "Biden",
"salience": 0.3091392,
"type": "PERSON"
},
...
And again, with "Joseph Biden":
gcloud ml language analyze-entities --content="Joseph Biden announced today a new policy towards China's government."
Again, it normalizes to the same ID:
...
{
"mentions": [
{
"text": {
"beginOffset": 0,
"content": "Joseph Biden"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/012gx2",
"wikipedia_url": "https://en.wikipedia.org/wiki/Joe_Biden"
},
"name": "Joseph Biden",
"salience": 0.3091392,
"type": "PERSON"
},
...
What do the same sentences look like through the eyes of LLM's – specifically ChatGPT? Let's first try a straightforward prompt – asking for a list of entities:
Make a list of the entities in the text "President Biden announced today a new policy towards China."
To which ChatGPT responds:
Based on the given text "President Biden announced today a new policy towards China," the entities mentioned can be identified as follows:
-
- President Biden – Refers to the current president of the United States, Joe Biden.
- announced – Describes the action taken by President Biden, indicating that he made a public statement or declaration.
- today – Specifies the timing of the announcement, suggesting that it occurred on the same day as the conversation or text.
- a new policy – Indicates that President Biden unveiled or introduced a fresh approach or set of guidelines.
- towards China – Specifies the target or subject of the new policy, which is China.
Please note that this list identifies the entities mentioned explicitly in the text. Other entities that may be inferred or related to the topic, such as the United States, can be considered as well.
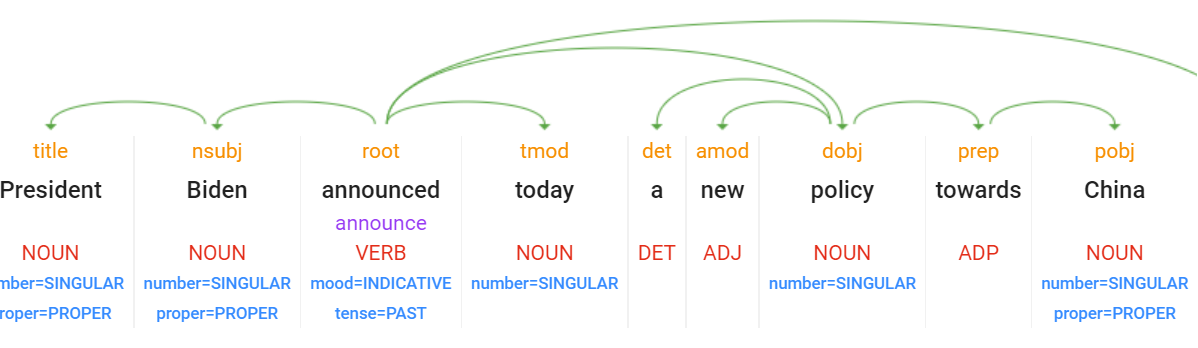
ChatGPT correctly recognizes "President Biden" as referring to "Joe Biden". However, it then proceeds to label "announced" as an entity, when it is actually a verb. The word "today" can be treated as an entity under some models, but as can be seen by the NLP API's output, is not labeled by many entity extractors. The next two entities are especially problematic: instead of isolating the actual entities of "policy" (or "new policy" depending on the extractor's design) and "China", they group them together with their surrounding text, meaning a sentence mentioning "in China" and another mentioning "towards China" would be treated as mentioning different entities, rather than both referring to the country of China.
Entity extractors are, by their definition, designed to "extract" the entity from the surrounding text, returning only the entity itself. In contrast, here ChatGPT has simply chunked the text and returned it more akin to a dependency parse.
In fact, if we look at the dependency parse for the sentence, we can see that ChatGPT chunked it nearly identically, returning what amounts to constituent clauses, rather than extracted entities:
Could we improve these results by asking ChatGPT to return only "names" instead of "entities"?
Extract a list of the names in the following text: "President Biden announced today a new policy towards China."
Unfortunately, ChatGPT interprets "names" as "person names" and returns only Biden's:
The list of names in the given text is as follows:
-
- President Biden
Let's refine this slightly:
Extract a list of the people, locations and organizations in the following text: "President Biden announced today a new policy towards China."
Clarifying that we want people, locations and organizations adds China to the list:
Based on the provided text, here is a list of the people, locations, and organizations mentioned:
People:
-
- President Biden
Locations:
-
- China
Organizations:
-
- None mentioned in the given text
Could we improve this by using Wikipedia as a normalization dataset? In essence, if we ask ChatGPT to only return names found in Wikipedia, we should be able to nudge it towards normalizing names like "President Biden" to "Joe Biden":
Extract a list of the names in the following text, disambiguating and normalizing each name to the title of its corresponding Wikipedia article: "President Biden announced today a new policy towards China."
This yields:
To disambiguate and normalize each name in the given text to the title of its corresponding Wikipedia article, we can perform entity recognition and linking. Here's the list of names along with their normalized titles:
-
- President Biden – Joe Biden (President of the United States): Joe Biden – Wikipedia
- China – People's Republic of China: People's Republic of China – Wikipedia
By normalizing the names to the corresponding Wikipedia articles, you can access more information about each entity.
Unlike our original "names" query when it returned only person names, this time it outputs China as well. It also correctly links both to their Wikipedia entries, normalizing "President Biden" to "Joe Biden".
What about our other two queries?
Extract a list of the names in the following text, disambiguating and normalizing each name to the title of its corresponding Wikipedia article: "Biden announced today a new policy towards the Chinese government."
This yields the following:
To disambiguate and normalize each name in the given text to the title of its corresponding Wikipedia article, we can perform entity recognition and linking. Here's the list of names along with their normalized titles:
-
- Biden – Joe Biden (President of the United States): Joe Biden – Wikipedia
- Chinese government – Government of the People's Republic of China: Government of the People's Republic of China – Wikipedia
By normalizing the names to the corresponding Wikipedia articles, you can access more information about each entity.
Interestingly, the China link above is to "https://en.wikipedia.org/wiki/Government_of_the_People%27s_Republic_of_China", which is actually a redirect to the real Wikipedia page "https://en.wikipedia.org/wiki/Government_of_China". It is unclear why ChatGPT links to a redirect instead of the original page.
What about the other two sentences?
Extract a list of the names in the following text, disambiguating and normalizing each name to the title of its corresponding Wikipedia article: "President Biden announced today a new policy towards the Chinese government."
Yields:
Here is a list of names from the given text, along with their corresponding Wikipedia article titles:
-
- President Biden: Joe Biden (https://en.wikipedia.org/wiki/Joe_Biden)
- Chinese government: Government of China (https://en.wikipedia.org/wiki/Government_of_China)
While:
Extract a list of the names in the following text, disambiguating and normalizing each name to the title of its corresponding Wikipedia article: "Joseph Biden announced today a new policy towards the Chinese government."
Yields:
Here is a list of names from the given text, along with their corresponding Wikipedia article titles:
-
- Joseph Biden: Joe Biden (https://en.wikipedia.org/wiki/Joe_Biden)
- Chinese government: Government of China (https://en.wikipedia.org/wiki/Government_of_China)
In both of these cases, ChatGPT links to the actual Wikipedia article.
Of course, for these results to be useful in a real-world application, they need to be generated in a machine-readable format like JSON. What about simply asking ChatGPT?
This yields:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{ "Joseph Biden": "Joe Biden", "Chinese government": "Government of China" }
Please note that the Wikipedia URLs can be constructed using the Wikipedia article titles.
What if we open a new ChatGPT session and repeat the prompt in a fresh session?
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "Joseph Biden",
"wikipediaurl": "https://en.wikipedia.org/wiki/Joe_Biden"
}
{
"name": "Chinese government",
"wikipediaurl": "https://en.wikipedia.org/wiki/Government_of_China"
}
And a third time – fresh session, same prompt:
Certainly! Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "Joseph Biden",
"wikipediaurl": "https://en.wikipedia.org/wiki/Joe_Biden"
}
{
"name": "Chinese government",
"wikipediaurl": "https://en.wikipedia.org/wiki/Government_of_China"
}
Two of the three runs yielded the requested JSON, but the first time it output a different JSON format. This reflects the inconsistency and instability of LLM-generated JSON.
What if we make things easy for ChatGPT and provide all three sentences in the same paragraph?
Extract a list of the names in the following text, disambiguating and normalizing each name to the title of its corresponding Wikipedia article and outputting the results in JSON in the format "{name:, wikipediaurl: }" : "President Biden announced today a new policy towards China. Biden announced today a new policy towards the Chinese government. Joseph Biden announced today a new policy towards China's government."
This yields:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "President Biden",
"wikipediaurl": "https://en.wikipedia.org/wiki/Joe_Biden"
}
{
"name": "China",
"wikipediaurl": "https://en.wikipedia.org/wiki/China"
}
{
"name": "Chinese government",
"wikipediaurl": "https://en.wikipedia.org/wiki/Government_of_China"
}
{
"name": "Joseph Biden",
"wikipediaurl": "https://en.wikipedia.org/wiki/Joe_Biden"
}
{
"name": "China's government",
"wikipediaurl": "https://en.wikipedia.org/wiki/Government_of_China"
}
Note: Since "Joseph Biden" and "President Biden" refer to the same person, they are mapped to the same Wikipedia article. Similarly, "China" and "Chinese government" are disambiguated to the same Wikipedia article.
At first glance, these results appear excellent, recognizing that "President Biden" and "Joseph Biden" both resolve to "Joe Biden" and that "Chinese government" and "China's government" both resolve to "Government of China". However, look closer and notice that "Biden" is missing. While ChatGPT identified "Chinese government", it failed to recognize "Biden" as a name.
Given that Biden's half-century-long tenure in the US Government, including nearly a decade as vice president, it is likely that nearly all entity recognition systems in the world would be able to correctly identify and normalize mentions of his name. In particular, he was already president by the time of ChatGPT's 2021 knowledge cutoff.
What about a European head of state? Edgars Rinkēvičs has been the Minister of Foreign Affairs of Latvia since 2011 and is the President-elect of Latvia. What if we repeat our sentence from above and replace "Biden" with "Rinkēvičs"? The final sentence is "Rinkevics announced today a new policy towards China."
Google's NLP API correctly identifies that a mention of Rinkevics in the context of geopolitics in 2023 has the highest likelihood of referring to Latvia's President-elect:
{
"mentions": [
{
"text": {
"beginOffset": 0,
"content": "Rinkevics"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/0h_d362",
"wikipedia_url": "https://en.wikipedia.org/wiki/Edgars_Rinkēvičs"
},
"name": "Rinkevics",
"salience": 0.35867268,
"type": "PERSON"
},
ChatGPT, on the other hand, fails:
Extract a list of the names in the following text, disambiguating and normalizing each name to the title of its corresponding Wikipedia article and outputting the results in JSON in the format "{name, wikipedia url}" : "Rinkevics announced today a new policy towards China.
Yielding:
I apologize, but I couldn't identify the full name "Rinkevics" mentioned in the text. It seems to be a surname, and without additional context or information, it's challenging to disambiguate and provide the corresponding Wikipedia article. Could you please provide more details or clarify the full name of the person?
Asked a second time:
I apologize, but it seems that the name "Rinkevics" mentioned in the text does not correspond to any specific person with a Wikipedia article associated with it. Therefore, I am unable to provide a disambiguated and normalized Wikipedia URL for that name. Is there anything else I can assist you with?
And a third time:
I'm sorry, but the name "Rinkevics" does not correspond to a specific Wikipedia article as it is not a well-known individual or widely recognized name. Therefore, I cannot provide a corresponding Wikipedia URL for that name. If there is any other information or specific names you would like me to extract, please let me know.
Note that despite China appearing unambiguously, ChatGPT refused all three times to return any entities from the text due to its inability to normalize Rinkevics' name. Thus, a text containing a variety of known entities and a single unknown entity may cause ChatGPT to refuse to return any results.
Of course, in the above examples we provide the most common Romanized version of his name. What if we use his actual name with diacritics? In other words, we change the prompt to:
Extract a list of the names in the following text, disambiguating and normalizing each name to the title of its corresponding Wikipedia article and outputting the results in JSON in the format "{name, wikipedia url}" : "Rinkēvičs announced today a new policy towards China.
This time ChatGPT correctly recognizes his name:
"Rinkēvičs" refers to Edgars Rinkēvičs, a Latvian politician. Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{ "name": "Edgars Rinkēvičs", "wikipediaurl": "https://en.wikipedia.org/wiki/Edgars_Rink%C4%93vi%C4%8Ds" }
{ "name": "China", "wikipediaurl": "https://en.wikipedia.org/wiki/China" }
Please note that the Wikipedia URL for Edgars Rinkēvičs contains diacritic characters, which are URL-encoded in the provided link.
At first glance, this suggests that there is a simple fix: just provide the original form of a person's name when asking ChatGPT to perform entity recognition. There's a catch, however: Rinkevics' name is typically romanized in the media. For example, in just the last few weeks, Reuters, The Washington Post, DW, Bloomberg, France 24, NBC News, AP and even the US Department of State all used the romanized version of his name "Rinkevics" without the diacritics. Using ChatGPT to identify the names mentioned in any of that coverage would return zero hits for Rinkevics without surrounding context, while Google's NLP API would correctly identify him in each case.
In reality, most mentions of Rinkevics would likely mention him in the context of his formal government title, making normalization trivial. What if we applied ChatGPT to the following US State Department announcement that uses his romanized name?
Extract a list of the names in the following text, disambiguating and normalizing each name to the title of its corresponding Wikipedia article and outputting the results in JSON in the format "{name, wikipedia url}" : "Deputy Secretary of State Wendy Sherman met with Latvian Foreign Minister Edgars Rinkevics today in Washington, D.C. Deputy Secretary Sherman and Foreign Minister Rinkevics discussed the upcoming NATO Summit in Vilnius and NATO’s continuing work to strengthen Eastern Flank defense, counter Russian disinformation, and diplomatically isolate Russia. They also discussed ways to deepen U.S.-Latvia coordination in the Indo-Pacific and counter PRC economic coercion."
This yields:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "Deputy Secretary of State Wendy Sherman",
"wikipediaurl": "https://en.wikipedia.org/wiki/Wendy_Sherman"
}
{
"name": "Edgars Rinkēvičs",
"wikipediaurl": "https://en.wikipedia.org/wiki/Edgars_Rink%C4%93vi%C4%8Ds"
}
{
"name": "NATO",
"wikipediaurl": "https://en.wikipedia.org/wiki/NATO"
}
{
"name": "Vilnius",
"wikipediaurl": "https://en.wikipedia.org/wiki/Vilnius"
}
{
"name": "Eastern Flank",
"wikipediaurl": "https://en.wikipedia.org/wiki/Eastern_Flank"
}
{
"name": "Russia",
"wikipediaurl": "https://en.wikipedia.org/wiki/Russia"
}
{
"name": "Indo-Pacific",
"wikipediaurl": "https://en.wikipedia.org/wiki/Indo-Pacific"
}
{
"name": "PRC",
"wikipediaurl": "https://en.wikipedia.org/wiki/People%27s_Republic_of_China"
}
{
"name": "Washington, D.C.",
"wikipediaurl": "https://en.wikipedia.org/wiki/Washington,_D.C."
}
{
"name": "Latvia",
"wikipediaurl": "https://en.wikipedia.org/wiki/Latvia"
}
Please note that the Wikipedia URLs for some of the terms contain diacritic characters or special characters that are URL-encoded in the provided links.
At first glance, this seems like a reasonable codification of the text. There are two complications, however. The first is that Rinkevics' name is specified with his actual name with diacritics, meaning a downstream analysis tool that attempts to connect the name back to its location within the text will fail. This is in contrast to how GCP's NLP API provides a list of how the name actually appears in the text. The second issue is that ChatGPT normalizes "Eastern Flank" into a Wikipedia title that doesn't exist.
What about GCP's NLP API?
gcloud ml language analyze-entities --content="Deputy Secretary of State Wendy Sherman met with Latvian Foreign Minister Edgars Rinkevics today in Washington, D.C. Deputy Secretary Sherman and Foreign Minister Rinkevics discussed the upcoming NATO Summit in Vilnius and NATO’s continuing work to strengthen Eastern Flank defense, counter Russian disinformation, and diplomatically isolate Russia. They also discussed ways to deepen U.S.-Latvia coordination in the Indo-Pacific and counter PRC economic coercion."
This yields the following vastly richer annotation, which adds "NATO Summit" as a known entity and notes that Rinkevics appears in romanized form in the passage:
{
"entities": [
{
"mentions": [
{
"text": {
"beginOffset": 26,
"content": "Wendy Sherman"
},
"type": "PROPER"
},
{
"text": {
"beginOffset": 0,
"content": "Deputy Secretary of State"
},
"type": "COMMON"
},
{
"text": {
"beginOffset": 135,
"content": "Sherman"
},
"type": "PROPER"
},
{
"text": {
"beginOffset": 118,
"content": "Deputy Secretary"
},
"type": "COMMON"
}
],
"metadata": {
"mid": "/m/0gkhcs",
"wikipedia_url": "https://en.wikipedia.org/wiki/Wendy_Sherman"
},
"name": "Wendy Sherman",
"salience": 0.36719263,
"type": "PERSON"
},
{
"mentions": [
{
"text": {
"beginOffset": 74,
"content": "Edgars Rinkevics"
},
"type": "PROPER"
},
{
"text": {
"beginOffset": 57,
"content": "Foreign Minister"
},
"type": "COMMON"
},
{
"text": {
"beginOffset": 164,
"content": "Rinkevics"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/0h_d362",
"wikipedia_url": "https://en.wikipedia.org/wiki/Edgars_Rinkēvičs"
},
"name": "Edgars Rinkevics",
"salience": 0.22707683,
"type": "PERSON"
},
{
"mentions": [
{
"text": {
"beginOffset": 49,
"content": "Latvian"
},
"type": "PROPER"
},
{
"text": {
"beginOffset": 394,
"content": "Latvia"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/04g5k",
"wikipedia_url": "https://en.wikipedia.org/wiki/Latvia"
},
"name": "Latvian",
"salience": 0.09535052,
"type": "LOCATION"
},
{
"mentions": [
{
"text": {
"beginOffset": 100,
"content": "Washington, D.C."
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/0rh6k",
"wikipedia_url": "https://en.wikipedia.org/wiki/Washington,_D.C."
},
"name": "Washington, D.C.",
"salience": 0.03689725,
"type": "LOCATION"
},
{
"mentions": [
{
"text": {
"beginOffset": 147,
"content": "Foreign Minister"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "Foreign Minister",
"salience": 0.023114396,
"type": "PERSON"
},
{
"mentions": [
{
"text": {
"beginOffset": 244,
"content": "work"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "work",
"salience": 0.020571943,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 277,
"content": "defense"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "defense",
"salience": 0.018885095,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 302,
"content": "disinformation"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "disinformation",
"salience": 0.018885095,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 374,
"content": "ways"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "ways",
"salience": 0.014181415,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 401,
"content": "coordination"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "coordination",
"salience": 0.014181415,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 224,
"content": "NATO"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/059dn",
"wikipedia_url": "https://en.wikipedia.org/wiki/NATO"
},
"name": "NATO",
"salience": 0.013873969,
"type": "ORGANIZATION"
},
{
"mentions": [
{
"text": {
"beginOffset": 197,
"content": "NATO Summit"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/02r330x",
"wikipedia_url": "https://en.wikipedia.org/wiki/NATO_summit"
},
"name": "NATO Summit",
"salience": 0.01219253,
"type": "EVENT"
},
{
"mentions": [
{
"text": {
"beginOffset": 212,
"content": "Vilnius"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/07_kq",
"wikipedia_url": "https://en.wikipedia.org/wiki/Vilnius"
},
"name": "Vilnius",
"salience": 0.01219253,
"type": "LOCATION"
},
{
"mentions": [
{
"text": {
"beginOffset": 263,
"content": "Eastern Flank"
},
"type": "PROPER"
}
],
"metadata": {},
"name": "Eastern Flank",
"salience": 0.011189711,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 294,
"content": "Russian"
},
"type": "PROPER"
},
{
"text": {
"beginOffset": 345,
"content": "Russia"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/06bnz",
"wikipedia_url": "https://en.wikipedia.org/wiki/Russia"
},
"name": "Russian",
"salience": 0.011189711,
"type": "LOCATION"
},
{
"mentions": [
{
"text": {
"beginOffset": 459,
"content": "coercion"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "coercion",
"salience": 0.009938256,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 389,
"content": "U.S."
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/09c7w0",
"wikipedia_url": "https://en.wikipedia.org/wiki/United_States"
},
"name": "U.S.",
"salience": 0.008396304,
"type": "LOCATION"
},
{
"mentions": [
{
"text": {
"beginOffset": 421,
"content": "Indo-Pacific"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/01wvkz",
"wikipedia_url": "https://en.wikipedia.org/wiki/Indo-Pacific"
},
"name": "Indo-Pacific",
"salience": 0.0058800406,
"type": "LOCATION"
},
{
"mentions": [
{
"text": {
"beginOffset": 446,
"content": "PRC"
},
"type": "PROPER"
}
],
"metadata": {},
"name": "PRC",
"salience": 0.0058800406,
"type": "ORGANIZATION"
}
],
"language": "en"
}
What about Paraguay's President-elect? In reality, most news coverage of him refers to him only as Santiago Peña, but here we will use his full name to give ChatGPT every chance to recognize him:
Extract a list of the names in the following text, disambiguating and normalizing each name to the title of its corresponding Wikipedia article and outputting the results in JSON in the format "{name, wikipedia url}" : "Santiago Peña Palacios announces a new policy towards China."
This yields:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "Santiago Peña Palacios",
"wikipediaurl": "No Wikipedia article found"
}
{
"name": "China",
"wikipediaurl": "https://en.wikipedia.org/wiki/China"
}
Unfortunately, I couldn't find a corresponding Wikipedia article for "Santiago Peña Palacios".
And a second time:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "Santiago Peña Palacios",
"wikipediaurl": ""
}
{
"name": "China",
"wikipediaurl": "https://en.wikipedia.org/wiki/China"
}
Unfortunately, there is no specific Wikipedia article available for Santiago Peña Palacios based on the information provided. If there is more context or additional information about Santiago Peña Palacios, please provide it so that I can assist you further.
What if we just tell ChatGPT that he is Paraguayan?
Extract a list of the names in the following text, disambiguating and normalizing each name to the title of its corresponding Wikipedia article and outputting the results in JSON in the format "{name, wikipedia url}" : "Paraguay's Santiago Peña Palacios announces a new policy towards China."
As before, this fails with:
I apologize for the confusion, but I couldn't find any specific information or a corresponding Wikipedia article for Santiago Peña Palacios. It's possible that he may not be a well-known figure or his information is not readily available. However, I can still provide you with the disambiguated and normalized name for "China":
{
"name": "China",
"wikipediaurl": "https://en.wikipedia.org/wiki/China"
}
If there is any additional information or context you can provide about Santiago Peña Palacios, I'll be happy to assist you further.
And if we run a second time:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "Santiago Peña Palacios",
"wikipediaurl": ""
}
{
"name": "China",
"wikipediaurl": "https://en.wikipedia.org/wiki/China"
}
Unfortunately, there is no specific Wikipedia article available for Santiago Peña Palacios based on the information provided. If there is more context or additional information about Santiago Peña Palacios, please provide it so that I can assist you further.
And a third time – this time it hallucinates a non-existent Wikipedia article simply by presuming his name will be the title of a page:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "Santiago Peña",
"wikipediaurl": "https://en.wikipedia.org/wiki/Santiago_Pe%C3%B1a_Palacios"
}
{
"name": "China",
"wikipediaurl": "https://en.wikipedia.org/wiki/China"
}
In this case, "Santiago Peña Palacios" refers to the Paraguayan politician Santiago Peña Palacios.
In contrast, running the original text through GCP's NLP API requires no additional hints:
gcloud ml language analyze-entities --content="Santiago Peña Palacios announces a new policy towards China."
Yields the correct result of:
...
{
"mentions": [
{
"text": {
"beginOffset": 0,
"content": "Santiago Peña Palacios"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/g/11cls8sck7",
"wikipedia_url": "https://en.wikipedia.org/wiki/Santiago_Peña"
},
"name": "Santiago Peña Palacios",
"salience": 0.19307865,
"type": "PERSON"
},
...
Note the /g/ prefix for Pena's MID code. This indicates that this code did not originate with the original Freebase graph, but rather is a new entity code constructed by Google itself. Google constantly updates its knowledge graph in realtime, meaning it represents a live view of the planet.
What about the opening sentence from this article?
Extract a list of the names in the following text, disambiguating and normalizing each name to the title of its corresponding Wikipedia article and outputting the results in JSON in the format "{name, wikipedia url}" : "On 30 April, Santiago Peña, from the ruling Colorado Party, won the presidential elections. "
This yields:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "Santiago Peña",
"wikipediaurl": "https://en.wikipedia.org/wiki/Santiago_Pe%C3%B1a"
}
In this case, "Santiago Peña" refers to the Paraguayan politician Santiago Peña, who won the presidential elections as mentioned in the text. The provided Wikipedia URL corresponds to his article.
Interestingly, this time it correctly recognized his name. Let's run a second time – this time it also recognizes the Colorado Party:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "Santiago Peña",
"wikipediaurl": "https://en.wikipedia.org/wiki/Santiago_Pe%C3%B1a"
}
{
"name": "Colorado Party (Paraguay)",
"wikipediaurl": "https://en.wikipedia.org/wiki/Colorado_Party_(Paraguay)"
}
In this case, "Santiago Peña" refers to the Paraguayan politician Santiago Peña, and the provided Wikipedia URL corresponds to his article. The "Colorado Party" refers to the political party in Paraguay, and the provided Wikipedia URL corresponds to its article.
Once again, the instability of LLM output is highly problematic, requiring the query to be repeated a second time for the LLM to additionally recognize the Colorado Party.
Instead, GCP's NLP API provides the same results each time it is run:
gcloud ml language analyze-entities --content="On 30 April, Santiago Peña, from the ruling Colorado Party, won the presidential elections. "
And yields:
...
{
"entities": [
{
"mentions": [
{
"text": {
"beginOffset": 13,
"content": "Santiago Peña"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/g/11cls8sck7",
"wikipedia_url": "https://en.wikipedia.org/wiki/Santiago_Peña"
},
"name": "Santiago Peña",
"salience": 0.37098214,
"type": "PERSON"
},
{
"mentions": [
{
"text": {
"beginOffset": 45,
"content": "Colorado Party"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/02sxjv",
"wikipedia_url": "https://en.wikipedia.org/wiki/Colorado_Party_(Paraguay)"
},
"name": "Colorado Party",
"salience": 0.3311745,
"type": "ORGANIZATION"
},
...
What about this passage?
Extract a list of the names in the following text, disambiguating and normalizing each name to the title of its corresponding Wikipedia article and outputting the results in JSON in the format "{name, wikipedia url}" : "Santiago Peña announces a new policy towards Chinese expansion."
This yields:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "Santiago Peña",
"wikipediaurl": "https://en.wikipedia.org/wiki/Santiago_Pe%C3%B1a"
}
{
"name": "Chinese expansion",
"wikipediaurl": "https://en.wikipedia.org/wiki/Chinese_expansion"
}
In this case, "Santiago Peña" refers to an individual named Santiago Peña, but there is no specific Wikipedia article available for him based on the information provided. The provided Wikipedia URL is a placeholder for illustrative purposes. The "Chinese expansion" refers to the broader concept, and the provided Wikipedia URL corresponds to an article related to that topic.
Rather than recognize "Chinese expansion" as a reference to China, ChatGPT incorrectly determines it to be its own topic, but the specified Wikipedia article does not exist. Worse, the explanation at the bottom states that there is no article about Pena and that the provided URL is merely a placeholder, while it states that the Chinese expansion article does exist. In fact, it is precisely the opposite.
In contrast, GCP's NLP API:
gcloud ml language analyze-entities --content="Santiago Peña announces a new policy towards Chinese expansion."
Yields exactly what would be expected:
...
{
"mentions": [
{
"text": {
"beginOffset": 0,
"content": "Santiago Peña"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/g/11cls8sck7",
"wikipedia_url": "https://en.wikipedia.org/wiki/Santiago_Peña"
},
"name": "Santiago Peña",
"salience": 0.3091392,
"type": "PERSON"
},
{
"mentions": [
{
"text": {
"beginOffset": 46,
"content": "Chinese"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/0d05w3",
"wikipedia_url": "https://en.wikipedia.org/wiki/China"
},
"name": "Chinese",
"salience": 0.040903203,
"type": "LOCATION"
}
...
What about other languages? Let's first translate the sentence into Russian and repeat our ChatGPT prompt:
Extract a list of the names in the following text, disambiguating and normalizing each name to the title of its corresponding Wikipedia article and outputting the results in JSON in the format "{name, wikipedia url}" : "Сантьяго Пенья объявляет о новой политике в отношении Китая."
This yields the following, despite "Сантьяго Пенья" being the correct Russian translation of his name:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "Сантьяго Пенья",
"wikipediaurl": ""
}
{
"name": "Китай",
"wikipediaurl": "https://ru.wikipedia.org/wiki/%D0%9A%D0%B8%D1%82%D0%B0%D0%B9"
}
Unfortunately, there is no specific Wikipedia article available for "Сантьяго Пенья" based on the provided information. If there is more context or additional information about Сантьяго Пенья, please provide it so that I can assist you further.
In contrast, GCP's NLP API, which supports Russian:
gcloud ml language analyze-entities --content="Сантьяго Пенья объявляет о новой политике в отношении Китая."
Yields:
{
"mentions": [
{
"text": {
"beginOffset": 0,
"content": "Сантьяго Пенья"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/g/11cls8sck7",
"wikipedia_url": "https://en.wikipedia.org/wiki/Santiago_Peña"
},
"name": "Сантьяго Пенья",
"salience": 0.41332832,
"type": "PERSON"
},
{
"mentions": [
{
"text": {
"beginOffset": 100,
"content": "Китая"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/0d05w3",
"wikipedia_url": "https://en.wikipedia.org/wiki/China"
},
"name": "Китая",
"salience": 0.3229302,
"type": "LOCATION"
}
What about returning to Biden and trying in Chinese?
Extract a list of the names in the following text, disambiguating and normalizing each name to the title of its corresponding Wikipedia article and outputting the results in JSON in the format "{name, wikipedia url}" : "拜登宣布对中国扩张的新政策。"
This yields:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "拜登",
"wikipediaurl": "https://zh.wikipedia.org/wiki/%E7%B4%84%E7%91%9E%C2%B7%E6%8B%9C%E7%99%BB"
}
{
"name": "中国",
"wikipediaurl": "https://zh.wikipedia.org/wiki/%E4%B8%AD%E5%9B%BD"
}
The name "拜登" corresponds to Joe Biden, and the provided Wikipedia URL leads to his Chinese Wikipedia article. "中国" refers to China, and the provided Wikipedia URL leads to its Chinese Wikipedia article.
This is less helpful, since it links to the Chinese Wikipedia entries, requiring a separate post-processing step to convert to their English normalized entries. However, the more problematic issue is that the URL given for Joe Biden simply doesn't exist.
Repeating a second time yields:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "拜登",
"wikipediaurl": "https://zh.wikipedia.org/wiki/%E7%B4%84%E6%91%A9%C2%B7%E5%B0%94%E6%9C%97"
}
{
"name": "中国扩张",
"wikipediaurl": "https://zh.wikipedia.org/wiki/%E4%B8%AD%E5%9B%BD%E6%89%A9%E5%BC%A0"
}
In this case, "拜登" refers to Joe Biden, and the provided Wikipedia URL corresponds to his article in Chinese. "中国扩张" translates to "Chinese expansion" and does not have a specific Wikipedia article. The provided Wikipedia URL is a placeholder for illustrative purposes.
Once again, the Biden entry does not exist.
Trying a third time:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "拜登",
"wikipediaurl": "https://zh.wikipedia.org/wiki/%E7%B4%84%E7%91%9E%C2%B7%E6%8B%9C%E7%99%BB"
}
{
"name": "中国",
"wikipediaurl": "https://zh.wikipedia.org/wiki/%E4%B8%AD%E5%9B%BD"
}
{
"name": "扩张",
"wikipediaurl": "https://zh.wikipedia.org/wiki/%E6%89%A9%E5%BC%A0"
}
Please note that the provided Wikipedia URLs are in the Chinese (Simplified) language.
Not only does the Biden URL not exist, but this time a third entity is extracted, "expansion" which does not exist.
Running a fourth time finally yields the expected results:
Here is the list of names from the given text, disambiguated and normalized with their corresponding Wikipedia article titles in JSON format:
{
"name": "Joe Biden",
"wikipediaurl": "https://en.wikipedia.org/wiki/Joe_Biden"
}
{
"name": "China",
"wikipediaurl": "https://en.wikipedia.org/wiki/China"
}
Please note that "拜登" (Biden) is normalized to "Joe Biden" as there is no specific Wikipedia article for the Chinese translation.
Thus, we had to run the query four times to get the correct results.
In contrast, once again the GCP NLP API yields exactly the expected results the very first time:
gcloud ml language analyze-entities --content="拜登宣布对中国扩张的新政策。"
Yielding:
...
{
"mentions": [
{
"text": {
"beginOffset": 0,
"content": "拜登"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/012gx2",
"wikipedia_url": "https://en.wikipedia.org/wiki/Joe_Biden"
},
"name": "拜登",
"salience": 0.63032186,
"type": "ORGANIZATION"
},
{
"mentions": [
{
"text": {
"beginOffset": 15,
"content": "中国"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/0d05w3",
"wikipedia_url": "https://en.wikipedia.org/wiki/China"
},
"name": "中国",
"salience": 0.22017856,
"type": "LOCATION"
},
...