
In collaboration with the Internet Archive's TV News Archive, over the past few months we have explored the concept of "enriching democracy" through the application of new forms of analytics and interface metaphors to the Archive's CSPAN collection. The complete Internet Archive TV News Archive collection of CSPAN, CSPAN2 and CSPAN3 (2009 – present for CSPAN/CSPAN2 and 2012 – present for CSPAN3) is available in the TV Explorer and TV Visual Explorer interfaces for searching and browsing.
Within the TV Explorer, complete keyword search of the broadcaster-provided closed captioning is available for the entire 14-year archive, including interactive temporal reporting in traditional and streamgraph formats, show breakdown, word cloud and even an analytic hourly heatmap display, along with a list of matching clips. Access is available through both an intuitive non-technical interactive user interface designed for journalists, researchers and ordinary citizens, and programmatic API access that enables unique kinds of new data journalism across television news.
The entire archive is also available in the TV Visual Explorer, permitting human, machine-assisted and fully automated visual analysis of the entire decade and a half archive. Any broadcast across the three CSPAN channels can now be directly accessed through the Visual Explorer and visually skimmed to instantly locate a moment of interest, with clips playing from the Archive's website.
Historically, the TV Explorer and TV Visual Explorer were entirely separate interface experiences, with no connection between them, despite being interfaces to the same underlying archive. As an early experiment in cross search-browse interfaces, the TV Explorer was updated to link directly to the Visual Explorer for searches of the three CSPAN channels. Now, when users keyword search the CSPAN archive using the TV Explorer, clicking on any search result launches the matching clip in the Visual Explorer interface.
Powerfully, as part of the TV Explorer and Visual Explorer environments, this visual archive can be searched alongside other channels and compared inline with any other channel in the TV News Archive. For example, a Senate COVID-19 hearing featuring a contentious exchange between Dr. Anthony Fauci and Sen. Rand Paul can be visualized at 4-second resolution alongside the coverage airing at that precise moment on CNN, MSNBC and Fox News to see how they covered, narrated and contextualized the live event.
It can also be used to extract the onscreen text using OCR to provide a parallel search capability. Early experiments both point to the potential of such OCR and to the limitations of current open source OCR systems for the unique environment of television news text.
To ease at-scale programmatic analysis of the Visual Explorer’s archives, a new JSON channel inventory was released that provides a complete machine-friendly inventory of all channels available in the Visual Explorer and their relevant vital characteristics, such as start and end dates, including for the CSPAN channels. This can now be used in automated scripting in place of manual date range specification. For example, a facial analysis tracking appearances of Tucker Carlson across Russian television can now be redesigned from a manually constructed list of channels and dates to a fully automated workflow that traverses the channel inventory JSON file for channels from a specific country and their available date ranges.
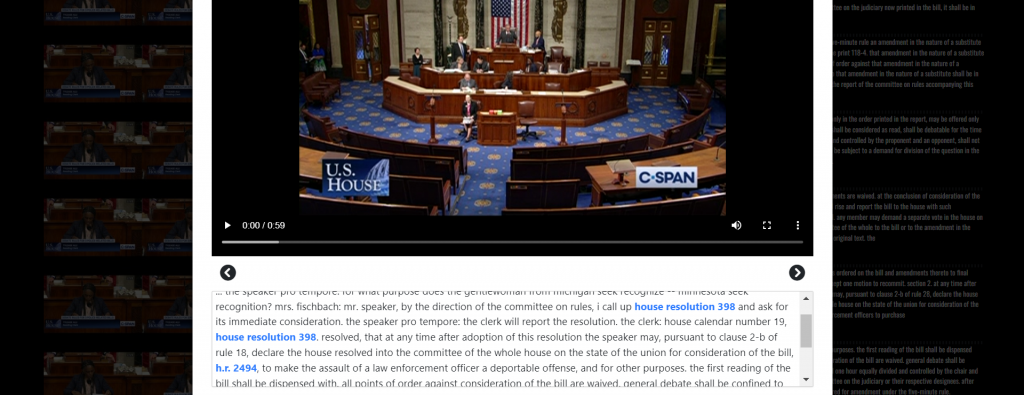
To enable joint spoken-visual analysis, the complete 1.8-billion-word captioning archive for the three CSPAN channels spanning more than a quarter-million broadcasts was integrated into the Visual Explorer, displaying the spoken word transcript alongside the Visual Explorer’s thumbnail grid interface and as an onscreen overlay when playing clips. This means that when viewing any broadcast, users can skip directly to a specific spoken word or reference and couple it with the onscreen visual.
This uniquely opens the door for the first time to true multimodal search. For example, in the Senate hearing containing the Fauci-Paul exchange above, many phrases relating to the pandemic, mitigation measures and vaccine were uttered repeatedly throughout the 4-hour hearing, but it is specific instances of those mentions during specific exchanges that are of greatest interest to journalists and researchers. A keyword search of the broadcast for the word “covid” yields 116 mentions and “grant” yields 8 mentions in three clusters, yet only a subset of those mentions garnered the most interest. Being able to keyword search within the browser in the Visual Explorer interface and see the thumbnails corresponding to each mention makes it instantly possible to isolate the moments of interest.
Using this vast captioning archive, two major research explorations were conducted using Large Language Models (LLMs).
The first examined the ability of LLMs to enhance existing hand-captioned CSPAN transcripts by adding proper capitalization (CSPAN closed captioning, like most captioning, is all-uppercase) and proper paragraph delineation by speaker (captioning is simply an endless stream of words). The end results were promising, though existential limitations of current LLMs means they are not yet ready for production use in this capacity.
The second LLM exploration examined the ability of LLMs to autonomously process CSPAN transcripts to identify all mentions of legislation. The vision was an LLM-based workflow that could process a CSPAN transcript, compile a list of all legislation mentioned within it and convert all of those mentions to links to the actual underlying legislative records. Ultimately, LLM hallucination proved too problematic: half of all mentions extracted by ChatGPT from CSPAN transcripts proved to be false inventions of the AI model where it would claim that a particular phrase in the transcript referred to a bill that does not and has never existed. Factual extraction tasks and normalization tasks are especially challenging to the current generation of LLM architectures, with congressional legislation, despite its highly structured and codified nature, proving uniquely difficult due to its perfect intersection with the hallucinogenic triggers of contemporary LLMs.
Instead, after an extensive series of at-scale research explorations across the complete 14-year 1.8-billion word CSPAN archive, a new solution was developed: a grammar-based in-browser fixed extraction system that autonomously scans each CSPAN transcript as it is displayed in the Visual Explorer interface and automatically identifies and converts every legislative mention into a hyperlink directly to the Congress.gov entry with the complete record of that legislation. The system, part of the Visual Explorer Lenses initiative, supports the complete array of congressional legislation: amendments, bills, resolutions, concurrent resolutions, joint resolutions, etc and performs a variety of normalization and preprocessing tasks: from converting from the form used in CSPAN transcripts to the form required by the Congress.gov record locator service to automatically computing the Congress in session during a given hearing since legislation numbers reset with each Congress. All of this is done in realtime in the browser as each CSPAN broadcast is viewed, allowing rapid iteration and refinement of the underlying models over time.
Today, when a CSPAN broadcast is viewed in the Visual Explorer, a cryptic mention of "s. res. 198" in a Senate session that is meaningless to the ordinary public becomes a live link to "A resolution designating the week of April 23 through April 29, 2023, as 'National Water Week'", making it instantly clear what is being debated, negotiated and discussed.
The end result is that when a clip from any CSPAN broadcast is viewed in the TV Visual Explorer, the transcript for that clip is automatically scanned on-the-fly for legislative mentions which become live clickable hyperlinks in the transcript directly to the underlying Congressional record. In short, CSPAN broadcasts are now deep-linked to the record of our nation’s government. Similarly, when CSPAN is keyword searched in the TV Explorer, clicking on the search results will launch the matching clip in the TV Visual Explorer with the legislative mentions hyperlinked. A keyword search for “climate change” in the TV Explorer yields matching clips that display in the TV Visual Explorer with the underlying legislative mentions converted to hyperlinks that deep link directly to their complete congressional records.
Historically, there has been a disconnect between finished legislation available on Congress.gov and the democracy-in-action legislative process that led to the final bill as captured by CSPAN. Not merely the spoken words of the back-and-forth debate and their tenor, but the unspoken body language and symbolic gestures of speakers through the myriad behind-the-scenes discussions across the floor that CSPAN's cameras capture. In short, to truly understand democracy, we must understand the democratic process that creates the laws that define and govern our nation. Through these efforts we have now connected those two worlds: legislation and the legislative process, the text of Congress.gov with the video of CSPAN.
In the end, the future of democracy rests on an informed electorate. Through these new forms of annotation and interface metaphors, drawing together legislation and the legislative process, we are taking powerful new steps towards a world in which citizens can play a far more active role in the governing process, continuing the long tradition of leveraging the digital world for government transparency from the earliest White House document repository under the Clinton administration. As we unsilo and interconnect these vast repositories of society, bridging modalities, languages, geographies, domains and the planet itself, we hope to unlock fundamentally new insights and understandings of the world itself.