One of the most cumbersome tasks in data science is all of the bespoke adhoc code that must be written on the fly, from initial surveys of the data, to all the myriad data cleaning and casting, to various statistical intermediaries, to the ultimate iterative pursuit of a given finding. When working with immense datasets at GDELT scale, this kind of interactive analysis typically happens in BigQuery, where it turns out Gemini Cloud Assist can be a huge accelerator, as we learned today in interactively compiling statistics on our story inventory work to date: we let Gemini write all of the core analytic code for us that we needed to assess Gemini's performance on our segmentation task, interactively and iteratively coding with it! We started by co-coding with Gemini, giving it schemas and operators and asking it to write SQL to perform specific tasks, then eased into just giving it plain English descriptions of what we wanted and having it write the SQL. Incredibly, for our final analysis we just asked Gemini in plain English to write SQL to perform pairwise cross-correlations of all columns across our dataset and output as a list, then reformat as a correlation matrix, then give us step-by-step instructions to turn it into a heatmap in Excel. Amazingly, every line of SQL was flawless and we didn't have to debug or change a single line!
To compile overall statistics on the performance of our Gemini-based story segmentation work, we need to extract and analyze various fields stored in our logging metadata stored in BigTable using BigQuery's Bigtable integration. To do this, we have to extract each field (knowing to use JSON_EXTRACT_SCALAR()) and perform a numeric cast and remember to use safe casting with SAFE_CAST() since some legacy values may be nulls. Instead of having to remember all of this and copy-paste and edit multiple lines of code, we just copy-pasted the textual schema and asked Gemini to write the code for us using the Cloud Assist pane that appears directly in BigQuery:
write me the query to extract the following fields from JSON field FIELD: status STRING apiFinishReason STRING durSec NUMERIC tokensPrompt NUMERIC tokensCandidates NUMERIC tokensThoughts NUMERIC promptWords NUMERIC promptChars NUMERIC cntStories NUMERIC cntStoryClips NUMERIC emotionsCnt NUMERIC entitiesCnt NUMERIC keywordsCnt NUMERIC locationsCnt NUMERIC
Which yielded the following to which we added a few filtering lines. Look at all that extraction and casting SQL we didn't have to write! Note how Gemini even correctly recognized that the first two fields are STRINGS so didn't attempt to cast them to numeric!
select
JSON_EXTRACT_SCALAR(FIELD, '$.status') status,
JSON_EXTRACT_SCALAR(FIELD, '$.apiFinishReason') apiFinishReason,
SAFE_CAST(JSON_EXTRACT_SCALAR(DOWN, '$.durSec') as NUMERIC) durSec,
SAFE_CAST(JSON_EXTRACT_SCALAR(FIELD, '$.tokensPrompt') as NUMERIC) tokensPrompt,
SAFE_CAST(JSON_EXTRACT_SCALAR(FIELD, '$.tokensCandidates') AS NUMERIC) tokensCandidates,
SAFE_CAST(JSON_EXTRACT_SCALAR(FIELD, '$.tokensThoughts') AS NUMERIC) tokensThoughts,
SAFE_CAST(JSON_EXTRACT_SCALAR(FIELD, '$.promptWords') AS NUMERIC) promptWords,
SAFE_CAST(JSON_EXTRACT_SCALAR(FIELD, '$.promptChars') AS NUMERIC) promptChars,
SAFE_CAST(JSON_EXTRACT_SCALAR(FIELD, '$.cntStories') AS NUMERIC) cntStories,
SAFE_CAST(JSON_EXTRACT_SCALAR(FIELD, '$.cntStoryClips') AS NUMERIC) cntStoryClips,
SAFE_CAST(JSON_EXTRACT_SCALAR(FIELD, '$.emotionsCnt') AS NUMERIC) emotionsCnt,
SAFE_CAST(JSON_EXTRACT_SCALAR(FIELD, '$.entitiesCnt') AS NUMERIC) entitiesCnt,
SAFE_CAST(JSON_EXTRACT_SCALAR(FIELD, '$.keywordsCnt') AS NUMERIC) keywordsCnt,
SAFE_CAST(JSON_EXTRACT_SCALAR(FIELD, '$.locationsCnt') AS NUMERIC) locationsCnt,
FROM (
SELECT
rowkey,
substr(rowkey,0,8) as day,
( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('STORYINV') ) FIELD,
( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('DOWN') ) DOWN,
FROM bigtableconnections.digtwin where SAFE_CAST(substr(rowkey, 0, 8) as NUMERIC) > 20000000 and rowkey like '20%'
) where JSON_EXTRACT_SCALAR(DOWN, '$.status') ='SUCCESS' and JSON_EXTRACT_SCALAR(FIELD, '$.status') is not null
We ran this query to generate a temporary table with the results and then asked Gemini to write the SQL to sum all the fields:
write the SQL to SUM() all the fields
Note how Gemini even correctly excludes the two STRING columns!
SELECT SUM(durSec) AS sum_dursec, SUM(tokensPrompt) AS sum_tokensprompt, SUM(tokensCandidates) AS sum_tokenscandidates, SUM(tokensThoughts) AS sum_tokensthoughts, SUM(promptWords) AS sum_promptwords, SUM(promptChars) AS sum_promptchars, SUM(cntStories) AS sum_cntstories, SUM(cntStoryClips) AS sum_cntstoryclips, SUM(emotionsCnt) AS sum_emotionscnt, SUM(entitiesCnt) AS sum_entitiescnt, SUM(keywordsCnt) AS sum_keywordscnt, SUM(locationsCnt) AS sum_locationscnt FROM `[TMPTABLE]`
Let's go for broke and not even hint to Gemini what SQL operators to use: we'll just describe what we want in plain English and let it figure things out for us:
make me a histogram of tokensThoughts, sorted by number of rows with each value
This yields:
SELECT tokensThoughts, COUNT(*) AS row_count FROM `[TMPTABLE]` WHERE tokensThoughts IS NOT NULL GROUP BY tokensThoughts ORDER BY row_count DESC;
Now let's try something that would ordinarily be much much messier and time-consuming: let's ask Gemini to give us the SQL to compute the pairwise correlation of every numeric value over the entire dataset. This can be done several ways, but requires either brute-force coding all of the various permutations or some complex nesting. Either way would take time. Let's just ask Gemini to do it for us:
perfect. now give me the pairwise pearson correlation of each of the numeric values and output each as a row sorted from highest to lowest correlation.
Yielding the following code that worked perfectly (truncated for space):
SELECT
field1,
field2,
corr_value
FROM (
SELECT
'durSec' AS field1,
'tokensPrompt' AS field2,
CORR(durSec, tokensPrompt) AS corr_value
FROM
`[TMPTABLE]`
WHERE
durSec IS NOT NULL AND tokensPrompt IS NOT NULL
UNION ALL
SELECT
'durSec' AS field1,
'tokensCandidates' AS field2,
CORR(durSec, tokensCandidates) AS corr_value
FROM
`[TMPTABLE]`
WHERE
durSec IS NOT NULL AND tokensCandidates IS NOT NULL
UNION ALL
SELECT
'durSec' AS field1,
'tokensThoughts' AS field2,
CORR(durSec, tokensThoughts) AS corr_value
FROM
`[TMPTABLE]`
WHERE
durSec IS NOT NULL AND tokensThoughts IS NOT NULL
UNION ALL
............
)
ORDER BY
ABS(corr_value) DESC;
This output exactly what we expected:
| field1 | field2 | corr_value |
| tokensPrompt | promptChars | 0.997927421 |
| promptWords | promptChars | 0.996994463 |
| tokensPrompt | promptWords | 0.993297727 |
| emotionsCnt | keywordsCnt | 0.983410468 |
| durSec | tokensPrompt | 0.926492994 |
| durSec | promptChars | 0.924034464 |
| durSec | promptWords | 0.919612691 |
| cntStories | keywordsCnt | 0.914936234 |
| cntStories | emotionsCnt | 0.902522682 |
| keywordsCnt | locationsCnt | 0.741347453 |
| tokensCandidates | entitiesCnt | 0.733144453 |
| emotionsCnt | locationsCnt | 0.73139142 |
| cntStories | locationsCnt | 0.689335368 |
| tokensPrompt | tokensCandidates | 0.678399271 |
But, actually, in retrospect, this isn't the best way to present this information, since it can make it difficult to visually spot underlying patterns. Instead, these pairwise correlations are typically presented in what's called a "correlation matrix". Let's ask Gemini to give us that instead.
that's perfect, now give me the code to output as a correlation matrix instead with the rows and columns ordered alphabetically top to bottom and left to right.
Incredibly, Gemini instantly transforms output from a long list into the requested correlation matrix (truncated for space):
SELECT
field_name,
CORR(cntStories, value) AS cntStories,
CORR(cntStoryClips, value) AS cntStoryClips,
CORR(durSec, value) AS durSec,
CORR(emotionsCnt, value) AS emotionsCnt,
CORR(entitiesCnt, value) AS entitiesCnt,
CORR(keywordsCnt, value) AS keywordsCnt,
CORR(locationsCnt, value) AS locationsCnt,
CORR(promptChars, value) AS promptChars,
CORR(promptWords, value) AS promptWords,
CORR(tokensCandidates, value) AS tokensCandidates,
CORR(tokensPrompt, value) AS tokensPrompt,
CORR(tokensThoughts, value) AS tokensThoughts
FROM
(
SELECT
cntStories,
cntStoryClips,
durSec,
emotionsCnt,
entitiesCnt,
keywordsCnt,
locationsCnt,
promptChars,
promptWords,
tokensCandidates,
tokensPrompt,
tokensThoughts,
'cntStories' AS field_name,
cntStories AS value
FROM
`[TMPTABLE]`
WHERE
cntStories IS NOT NULL
UNION ALL
SELECT
cntStories,
cntStoryClips,
durSec,
emotionsCnt,
entitiesCnt,
keywordsCnt,
locationsCnt,
promptChars,
promptWords,
tokensCandidates,
tokensPrompt,
tokensThoughts,
'cntStoryClips' AS field_name,
cntStoryClips AS value
FROM
`[TMPTABLE]`
WHERE
cntStoryClips IS NOT NULL
UNION ALL
..........
)
GROUP BY
field_name
ORDER BY
field_name;
Yielding exactly what we requested:
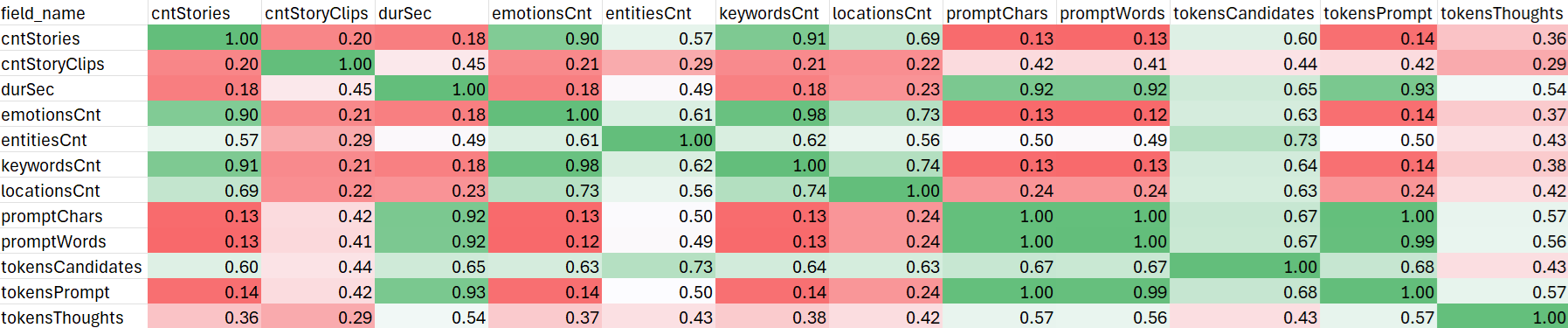
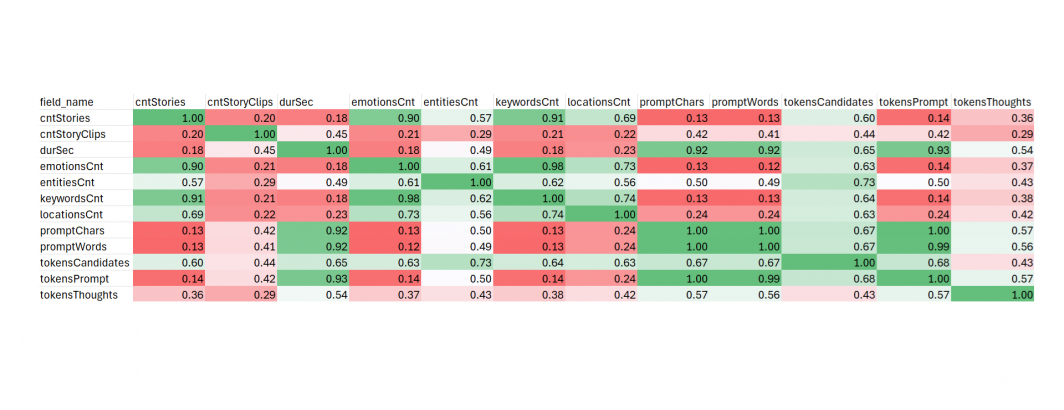
| field_name | cntStories | cntStoryClips | durSec | emotionsCnt | entitiesCnt | keywordsCnt | locationsCnt | promptChars | promptWords | tokensCandidates | tokensPrompt | tokensThoughts |
| cntStories | 1 | 0.200296346 | 0.179297425 | 0.902522682 | 0.573129814 | 0.914936234 | 0.689335368 | 0.131207921 | 0.126558097 | 0.599625358 | 0.141428972 | 0.357401833 |
| cntStoryClips | 0.200296346 | 1 | 0.452408735 | 0.20810114 | 0.294740727 | 0.211894857 | 0.221829594 | 0.418794685 | 0.4134904 | 0.43909004 | 0.420511932 | 0.293430561 |
| durSec | 0.179297425 | 0.452408735 | 1 | 0.181291738 | 0.491692803 | 0.184496431 | 0.234972858 | 0.924034464 | 0.919612691 | 0.650416452 | 0.926492994 | 0.538289572 |
| emotionsCnt | 0.902522682 | 0.20810114 | 0.181291738 | 1 | 0.613528235 | 0.983410468 | 0.73139142 | 0.129973678 | 0.124968629 | 0.631453648 | 0.14093968 | 0.374128798 |
| entitiesCnt | 0.573129814 | 0.294740727 | 0.491692803 | 0.613528235 | 1 | 0.61843528 | 0.562146762 | 0.498507607 | 0.493484693 | 0.733144453 | 0.50380652 | 0.431885144 |
| keywordsCnt | 0.914936234 | 0.211894857 | 0.184496431 | 0.983410468 | 0.61843528 | 1 | 0.741347453 | 0.133116151 | 0.128084048 | 0.63924357 | 0.144089898 | 0.375932311 |
| locationsCnt | 0.689335368 | 0.221829594 | 0.234972858 | 0.73139142 | 0.562146762 | 0.741347453 | 1 | 0.239508566 | 0.23789482 | 0.629665871 | 0.241643895 | 0.423105498 |
| promptChars | 0.131207921 | 0.418794685 | 0.924034464 | 0.129973678 | 0.498507607 | 0.133116151 | 0.239508566 | 1 | 0.996994463 | 0.674127833 | 0.997927421 | 0.568473166 |
| promptWords | 0.126558097 | 0.4134904 | 0.919612691 | 0.124968629 | 0.493484693 | 0.128084048 | 0.23789482 | 0.996994463 | 1 | 0.66984916 | 0.993297727 | 0.563727512 |
| tokensCandidates | 0.599625358 | 0.43909004 | 0.650416452 | 0.631453648 | 0.733144453 | 0.63924357 | 0.629665871 | 0.674127833 | 0.66984916 | 1 | 0.678399271 | 0.426388285 |
| tokensPrompt | 0.141428972 | 0.420511932 | 0.926492994 | 0.14093968 | 0.50380652 | 0.144089898 | 0.241643895 | 0.997927421 | 0.993297727 | 0.678399271 | 1 | 0.570853657 |
| tokensThoughts | 0.357401833 | 0.293430561 | 0.538289572 | 0.374128798 | 0.431885144 | 0.375932311 | 0.423105498 | 0.568473166 | 0.563727512 | 0.426388285 | 0.570853657 | 1 |
Usually these kinds of tables are colored-coded, with each cell colored based on its value. Can Gemini even tell us what to do in Excel?
how can i color code this into a heatmap in excel?
Incredibly, Gemini is even able to give us step-by-step instructions on how to find and use Conditional Formatting in Excel, giving us the following results. It is hard to believe that Gemini not only coded the SQL to make this table, but even walked us through color-coding it in Excel: