Yesterday we looked at a few minutes in the life of a streaming ingest VM running on GCE. Ingest nodes have equal ingest and egress network traffic, as they act simply as edge proxies, running geographically proximate to the source data center and ingesting content into GCP's network, where it streams across GCP networking to GCS for storage and distribution to compute nodes running in any GCP region.
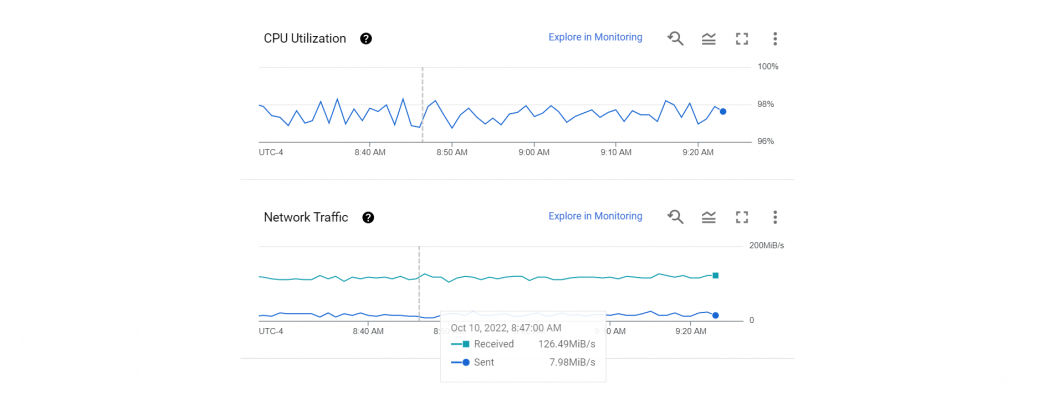
In contrast, stream processing nodes ingest large volumes of data from GCS and process those large input streams into much smaller output streams. An example is our Visual Explorer backfile processing nodes which are currently processing the Internet Archive's Television News Archive's two-decade historical backfile spanning 50 countries into thumbnail grids. An hour in the life of one of those nodes can be seen at the top of this post. CPU remains constant at around 97-98% (reported by the kernel at 99%), reflecting that the machine is CPU-limited, since all IO occurs in RAM disk.
The network traffic graph is what distinguishes stream processing from stream ingest nodes. The Visual Explorer system transforms MPEG2 and MPEG4 files into thumbnail grids, ingesting video files that range from 200MB to 10GB+ and outputting a single JPEG thumbnail grid and a small ZIP file containing the full-res versions of the thumbnail grid images.
This is a transformative process, reducing massive inputs into small outputs. As can be seen in the graph above, each of the Visual Explorer nodes averages around 120-130MiB/s of MPEG2/MPEG4 input video data and outputs around 8-9MiB/s of ZIP and JPEG data, collapsing the data size by around 15x.
Making this possible is the GCS backbone and GCP networking. GDELT's stream processing nodes are physically scattered across GCP data centers worldwide to take advantage of local resources, from specific CPU families and machine types to specific accelerators. All share a single globalized GCS namespace, meaning we can simply spin up as many as are needed worldwide and each node simply connects at startup to a centralized queuing server and begins streaming its workloads to/from that shared GCS namespace. While there is increased latency as distance increases from the US multiregion, the impacts of that latency are negligible given the high parallelism of the processing tasks per node, which fully interleave processing and ingest.