We continue to explore the landscape of AI-powered autonomous agents. Despite their immense hype and ubiquitous mediagenic demos on social media, we continue to find them unsuitable for the kind of production real-world use cases that define the World Of GDELT. Specifically, their inability to move beyond statistics-based autocompletion engines towards actual symbolic reasoning engines that understand the code they generate or the patterns in the data they are given means they are limited to nothing more than copy-pasting what others have done in the past.
In the creation of our split montage/API OCR workflow, we evaluated numerous production and yet-to-be-released advanced and research-grade autonomous agents and coding copilots to see if they could accelerate our development workflow, with the typically abysmal results we see from contemporary AI architectures.
First, we wanted to test their technical architecture capabilities. We provided a description of our current challenge in our OCR workload, in which we had a massive stream of videos to process that involved video processing locally on the VM CPU and submitting the results to a rate-limited external API and asked for recommendations. Remarkably, few of the systems proposed a completely functional architecture involving dual queues, one stage feeding into the next, global-level orchestration of the API stage without limiting the montage stage, etc. Not of the systems we evaluated was able to devise an architecture anywhere near as efficient and simple as the one we had constructed.
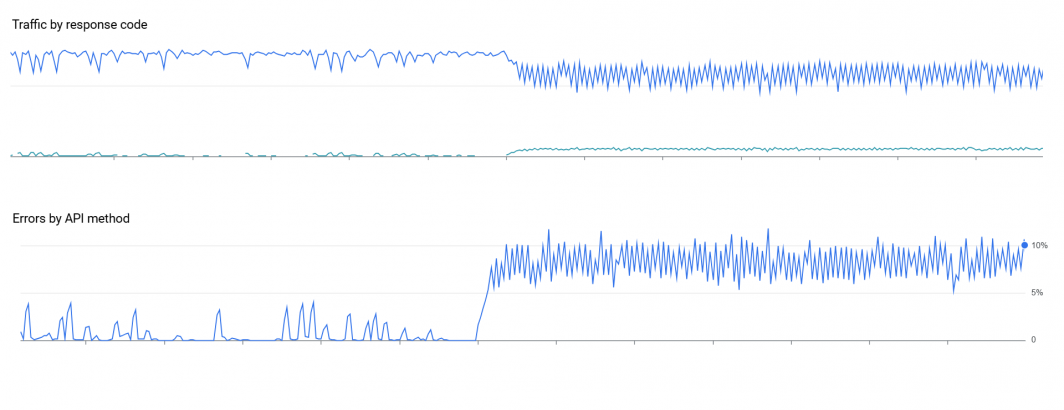
Having failed the macro-level architecture test, we decided to test their micro-level architectural development capabilities. Asked to produce a simple rate-limited API submission loop, all of the provided solutions (each tool was rerun from scratch 5 times) suffered from front loading in which as each second reset the loop would submit as many jobs as fast as it could until that second's quota was exhausted. Unfortunately, this triggered near-steady HTTP 429 errors as the API rate limiting layers rejected our massive instantaneous burst of submissions lasting a few milliseconds every second.
To see just how stark the difference this makes, here is an example of our original human-constructed code that evenly distributes API submissions at the requested QPS throughout each second and then the deployment of one of the most robust of the copilot-developed codes. API quota errors leap to a steady state of 5-10% of all submissions, triggering fleet-wide back-offs to prevent overloading the API.
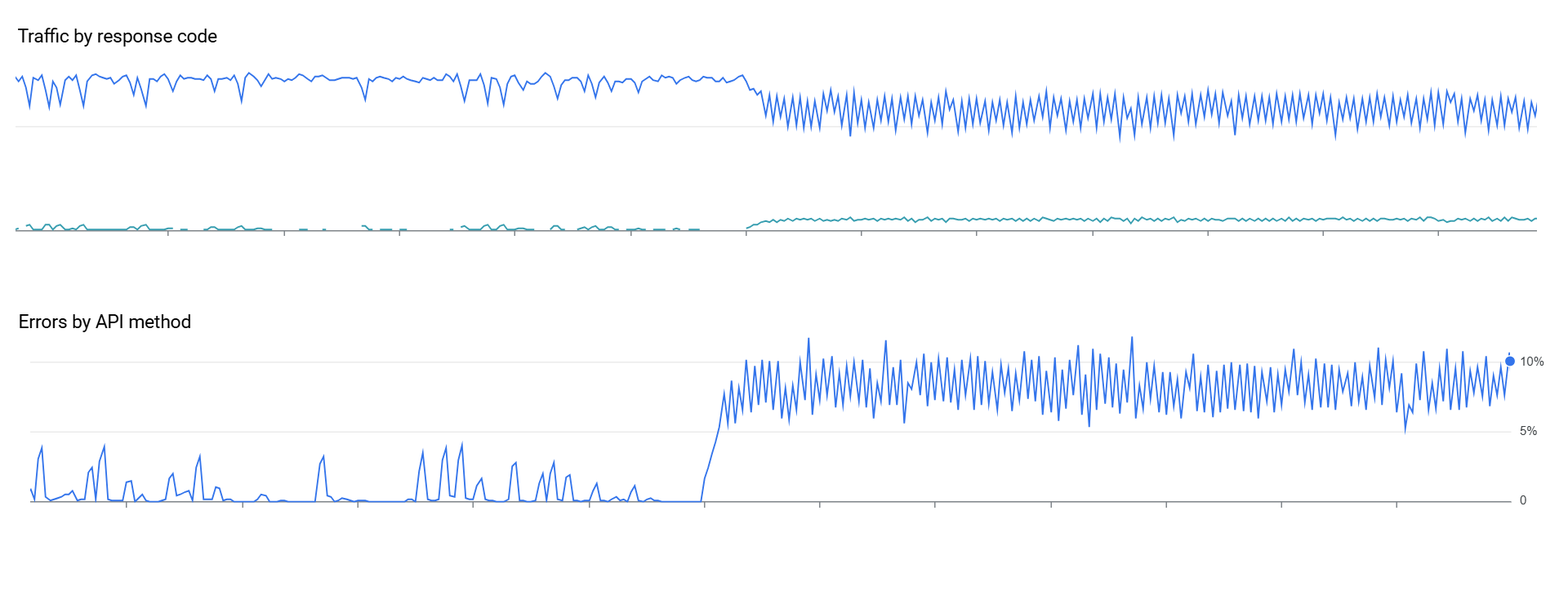
Worse, as part of our work testing AI-powered autonomous agents, we provided realtime API monitoring data via the GCP Monitoring API to each of the autonomous agent systems being evaluated and asked each of them every 60 seconds to evaluate the rolling submission, latency and error rates and determine whether it should increase, decrease or leave the same the API submission rate and what level of increase or decrease it would recommend. Once again the results were abysmal, with several of the models never once detecting any abnormality in the data, while even the best results were extremely unstable, with the models alternating randomly run to run (even when run on the same data multiple times each second to test stability) as to whether there were any abnormalities or changes required.