While all APIs can exhibit variable response times and error rates, AI APIs demonstrate uniquely complex response behaviors. The scarcity of the underlying hardware accelerators they rely upon can create transient regional capacity overloads and throttling or a failed model or infrastructure rollout can cause outages, while the basic underlying nature of AI architectures makes their performance highly unpredictable even on dedicated standalone hardware. Put all of this together and it creates highly unique scaling challenges, especially for the largest and most latency-sensitive workloads, along with unique decision making around how to scale underlying CPU resources. Let's look at a simple example of this from last night.
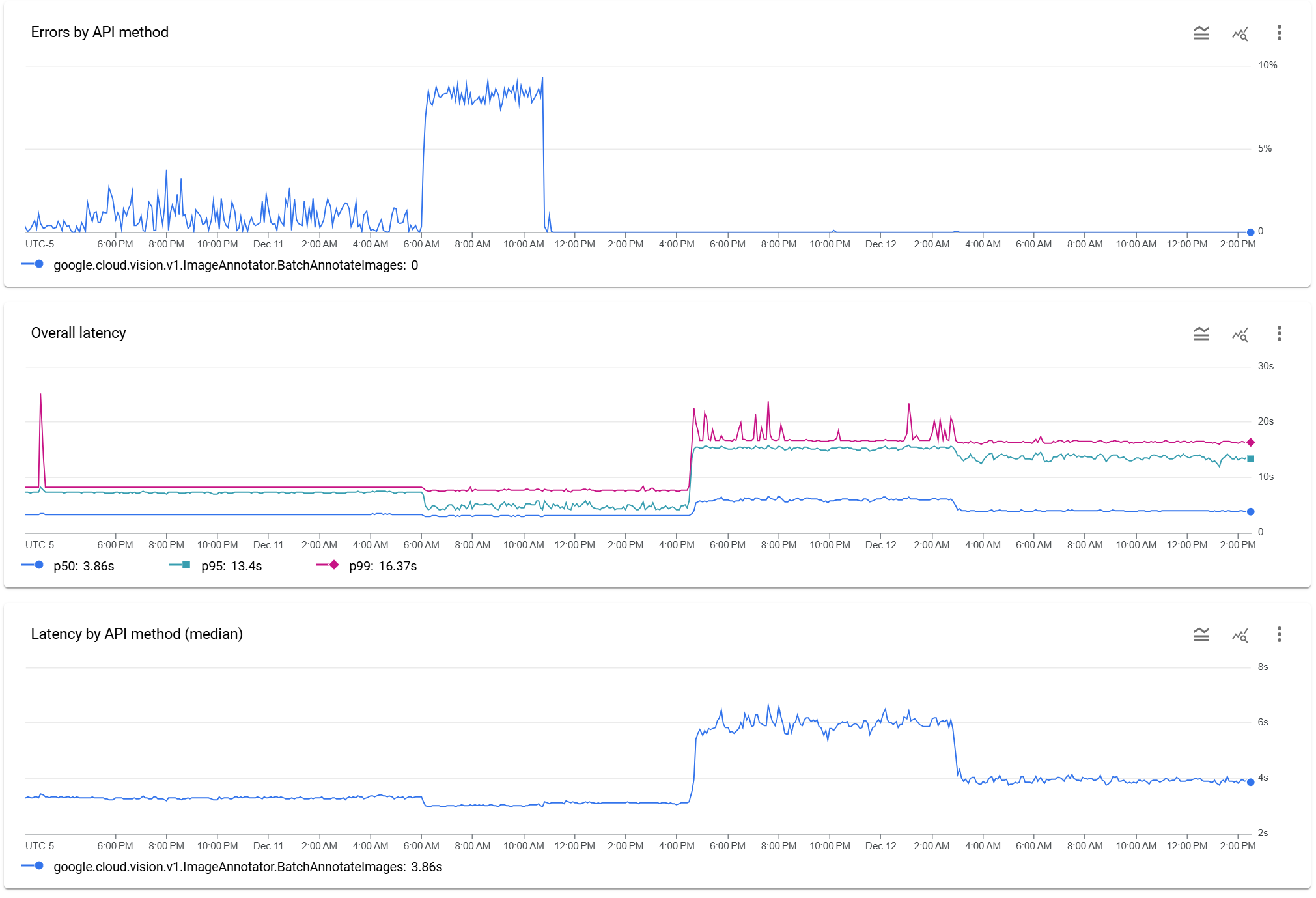
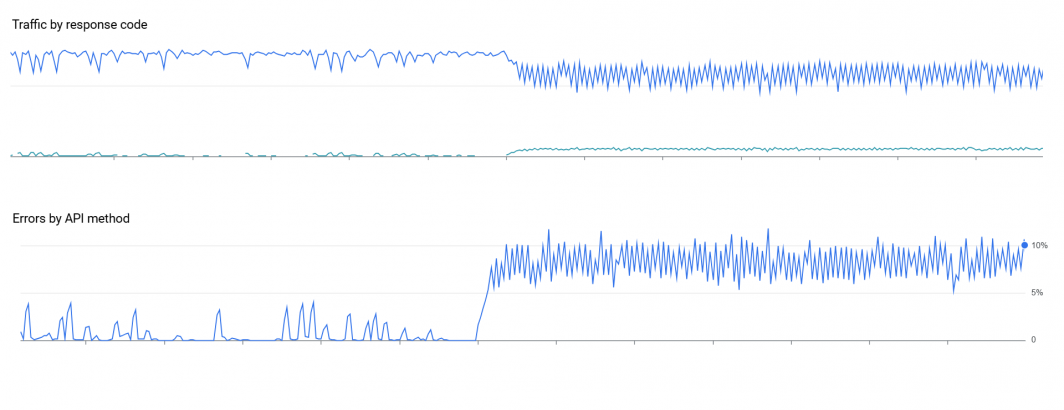
Below are a series of three graphs showing GCP Cloud Vision API's reported error rate and latencies for our archive-scale OCR initiative. We had finally stabilized our infrastructure with a tightly bound API submission rate just under the maximum quota and cluster scaling that resulted in near-equilibrium amongst all of the various moving parts and cluster sizing. Then, all of a sudden at 6AM yesterday everything began to unravel. Monitoring applications began to send alerts that error rates were exceeding what they could manage on their own and that no amount of traffic rebalancing or regional movement seemed to help. Manual intervention was required, but initial fleet-wide monitoring and logging systems showed nothing obviously amiss: traffic had been proceeding at a steady state before the API error rate suddenly hit around 7% steady state. Even as the submission rate was rapidly throttled down, the error rate remained constant. Quota reporting indicated that no automated quota changes had occurred and available diagnostic information suggested nothing out of the ordinary. Resubmitting the images yielded accurate results, meaning it was not a format or corruption error. A rolling reboot of the entire fleet brought no change.
Then, just as suddenly as it arrived, the increased error rate dropped to zero and the pipeline recovered back to full throttle around 11AM: crisis averted.
Yet, suddenly a little before 5PM the true chaos began: automated scaling systems that automatically increased the number of API submission systems to overcome latency variability had rapidly reached their preset soft and hard maximums. In short, to maintain a fixed API submission rate of X API calls per second when each API call can take anywhere from 1 second to 10 seconds on average and up to 70+ seconds in edge cases, there is an orchestration system that automatically scales up the cluster size devoted to API submission. This automated scaling had reached its safety margins as it attempted to overcome a sharp rise in API latency.
In this case, the graphs below don't capture that that all-important >p99 top-bound latency, in which the outlier latency increased from around 15s to 70-90s. To maintain the target API QPS under these conditions required completely rearchitecting for a second time how we handled our montage-OCR split. While before we had just a small number of dedicated OCR systems, this new latency environment required instead distributing the OCR processes across the entire fleet and keeping the per-VM QPS low enough that each VM could maintain a fixed QPS and across the entire fleet combined we could remain just precisely under the API quota.
While ultimately we were able to resume API saturation, this 24-hour period required considerable human intervention and complex technical rearchitecting and is a reminder of the complexities of working at scale with AI models and APIs and that the kinds of challenges that enterprises will encounter as they move to AI-first workloads are often more complex than from traditional CPU-based workloads.