
In collaboration with the Internet Archive's TV News Archive, we are working to OCR the Archive's entire 7-million-hour quarter-century archive spanning 50 countries and 150 spoken languages to allow keyword search of all onscreen text using the TV Explorer. To date we have completed machine transcribing all 2.5 million hours of uncaptioned airtime using GCP's Chirp LSM model, vividly capturing the first time the prevalence of code switching at these scales.
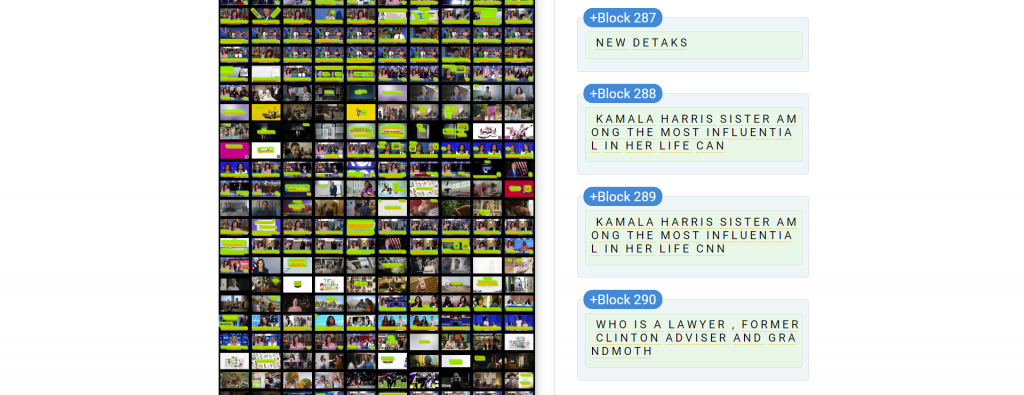
We are now working on augmenting that spoken word archive by transcribing the Archive's onscreen text. Television news OCR is many orders of magnitude more complex than print OCR: text is superimposed on top of highly visually complex scenes, there are multiple fonts/colors/backgrounds in the same image, both foreground and background text, which may be partially obscured, and text appears in multiple angles to the screen, from straight on to a significant angle to the screen and even mixed vertical and horizonal, left-to-right and right-to-left text all in the same image. Multiple languages can appear at the same time in a single frame and image resolution can be as low as 640×480 pixels and even lower in some countries, meaning extractable text might only be a few tens of pixels high.
OCR'ing a single frame at a time using GCP's Cloud Vision API results in pretty remarkable accuracy, but to achieve a 100-200x speedup and reduction in cost, we are using a montage-based workflow and accepting a small accuracy reduction. Given the sheer scale of our OCR work (OCR'ing the complete Archive would cost more than $75M using a traditional workflow), we've gotten a lot of interest in what lessons we've learned to date, especially around open source and free models like Tesseract and EasyOCR, LMMs like Gemini, ChatGPT 4 and PaliGemma and dedicated CV models like GCP Cloud Vision API, topics like block reconstruction and stability, and the initial results from our montaging workflows. Below you can find a few relevant links summarizing our work to date:
- https://blog.gdeltproject.org/can-lmms-like-chatgpt-4o-and-gemini-yield-better-results-than-cloud-visions-classical-ai-ocr/
- https://blog.gdeltproject.org/why-large-multimodal-models-lmm-like-chatgpt-are-unsuitable-for-production-ocr/
- https://blog.gdeltproject.org/ocring-television-news-comparing-gcp-cloud-vision-api-paligemma-tesseract-gemini-1-5-pro-gemini-1-5-flash-gpt-4o/
- https://blog.gdeltproject.org/ocring-television-news-experiments-with-easyocr/
- https://blog.gdeltproject.org/ocring-television-news-comparing-gcp-cloud-vision-api-paligemma-tesseract-gemini-1-5-pro-gemini-1-5-flash-gpt-4o/
- https://blog.gdeltproject.org/an-ocr-tale-of-two-images-the-impact-of-small-changes-on-ocr-block-reconstruction/
- https://blog.gdeltproject.org/the-fascinating-findings-of-applying-advanced-ocr-to-television-news-transcribing-projected-text/
- https://blog.gdeltproject.org/at-scale-ocr-of-television-news-experiments-results-from-a-sample-quarter-century-old-chinese-language-broadcast/
- https://blog.gdeltproject.org/at-scale-ocr-of-television-news-experiments-results-from-a-sample-circa-2010-sd-resolution-english-language-broadcast/
- https://blog.gdeltproject.org/at-scale-ocr-of-television-news-experiments-two-interesting-examples-of-the-ocr-inconsistencies-of-ocr-at-scale/
- https://blog.gdeltproject.org/using-thumbnail-montages-to-optimize-ai-based-video-ocr-speed-costs-part-8-cost-comparisons/
- https://blog.gdeltproject.org/using-thumbnail-montages-to-optimize-ai-based-ocr-speed-costs-part-7-what-have-we-learned-so-far/
- https://blog.gdeltproject.org/using-thumbnail-montages-to-optimize-ai-based-ocr-speed-costs-part-6-further-grid-layout-experiments/
- https://blog.gdeltproject.org/using-thumbnail-montages-to-optimize-ai-based-ocr-speed-costs-part-5-the-impact-of-grid-layout/
- https://blog.gdeltproject.org/using-thumbnail-montages-to-optimize-ai-based-ocr-speed-costs-part-4/
- https://blog.gdeltproject.org/using-thumbnail-montages-to-optimize-ai-based-ocr-speed-costs-part-3/
- https://blog.gdeltproject.org/using-thumbnail-montages-to-optimize-ai-based-ocr-speed-costs-part-2/
- https://blog.gdeltproject.org/using-thumbnail-montages-to-optimize-ai-based-ocr-speed-costs-part-1/