Amongst the TV News Archive's quarter-century of global broadcasts are interlaced broadcasts, which produce the tell-tale jagged ghosting seen below on modern displays. For the majority of these broadcasts a surrogate deinterlaced MP4 file already exists that allows us to proceed as if the video was always progressive format. Unfortunately, for some broadcasts the MP4 either doesn't exist or has technical issues, such as corruption or using frame-halving that makes the text too small to robustly OCR. While we could certainly generate our own deinterlaced MP4s in these cases using ffmpeg, the added cost of scanning petabytes of videos to identify interlaced files and then transcode them makes this an expensive pathway. Instead, we wanted to know how robustly GCP's Cloud Vision OCR can OCR interlaced text.
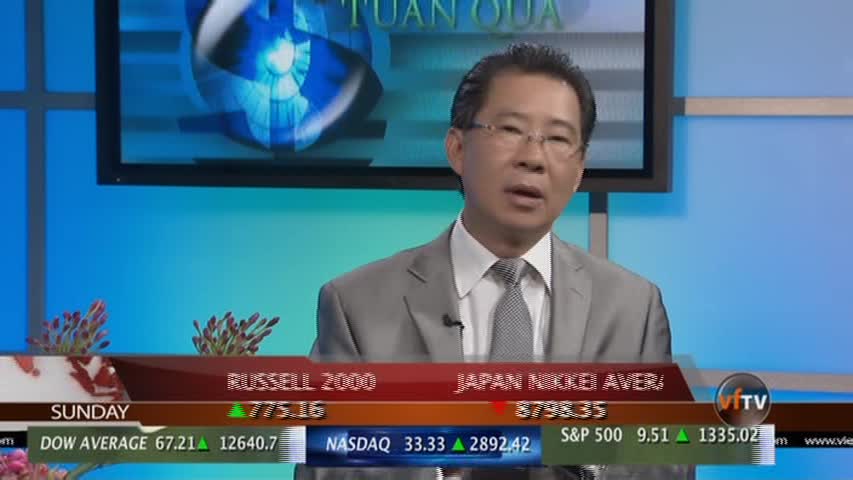
The answer is that much of the onscreen text in interlaced video, such as the all-important chyrons, remain positionally stable or slow-moving and thus are not impacted by the interlacing. For fast-moving "crawls", remarkably GCP's Cloud Vision API OCR is able to correctly OCR them in the majority of cases, such as the frame below where it correctly extracts "Russell 2000" and "Japan Nikkei Aver" (the rest of the word "average" is cut off mid-scroll in this frame). Further experiments show a high level of accuracy even in worst-case scenarios such as fast-moving graphics. This is incredibly impressive and means that we are able to successfully extract the majority of useable text from interlaced videos as-is.