One of the most remarkable and difficult challenges of scaling novel workflows from one-off experiments to massive archive-scale production implementations is the strange and unexpected ways in which tools can behave differently at scale – not just their runtime performance and characteristics, but even their outputs. In all of our early scale-up OCR tests from hundreds to thousands to tens of thousands of videos, FFMPEG uniformly produced 1FPS JPEG frames with a quality setting of between 1 and 1.8, with a median of around 1.6. As we continued to scale up, we never observed variances outside of this range, even when heavily oversubscribing systems (in case FFMPEG performed resource-based throttling) or when given different quality and bitrate levels of input video. It was only after our workflow was in production that we began to see sporadic videos with vastly poorer quality settings (lower is better), such as this circa-2021 HD resolution broadcast for which FFMPEG strangely selected a quality setting of 25. After extensive experimentation with various quality settings across a range of videos (SD/HD, text heavy/light, regions, languages, etc) we ultimately settled on "-q:v 6" as the final manual quality parameter we now use for our 1FPS generation for OCR which yields filesizes half those of q=2 with no quality degradation in textual regions. You can see the comparison images below.
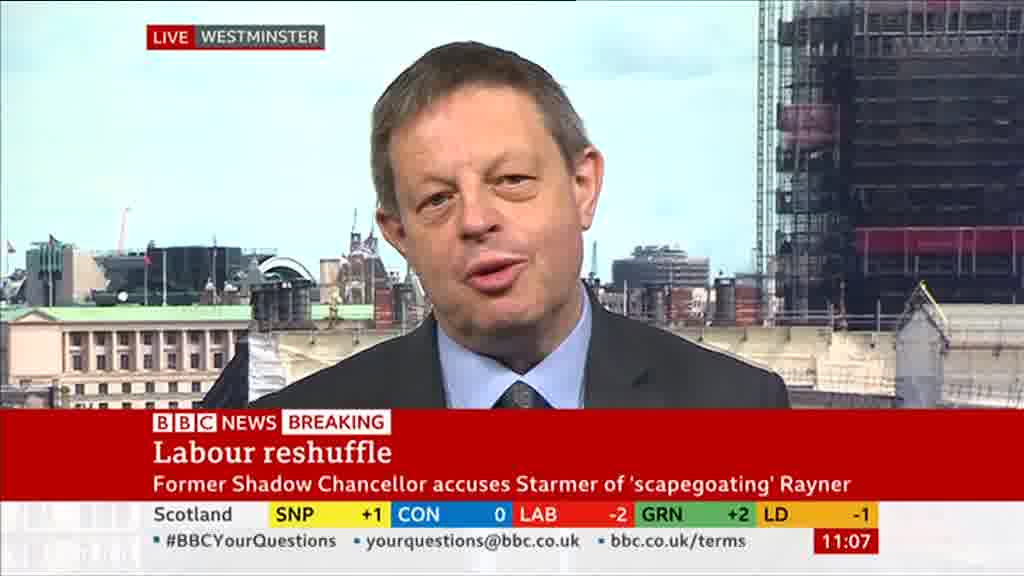
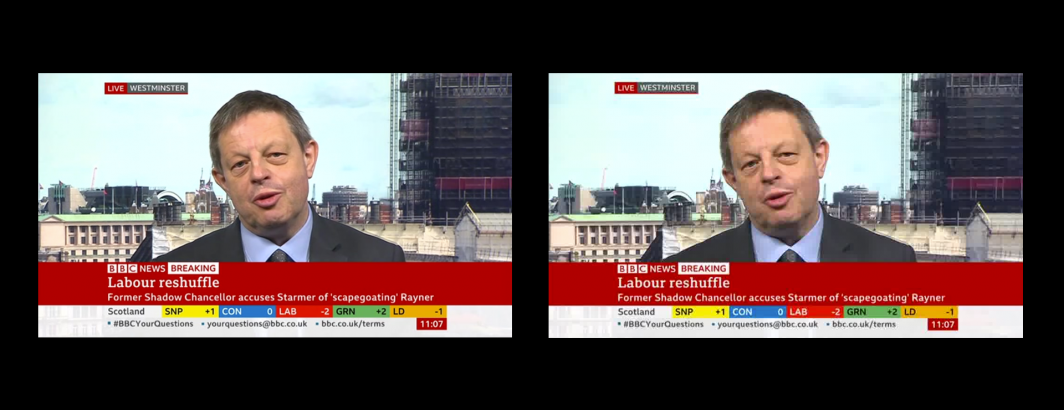
Run without a quality setting at 1/4FPS, FFMPEG automatically selects a quality setting of ~1.6 for its generated JPEGs. Below you can see a manually-set quality setting of 2. Note that the details are crisp, with only minorly visible JPEG artifacting around the text and fine detail. Importantly, if you look closely at the original video, you will see that these artifacts are actually present in the original MP4 capture stream, rather than being introduced during the 1FPS construction.
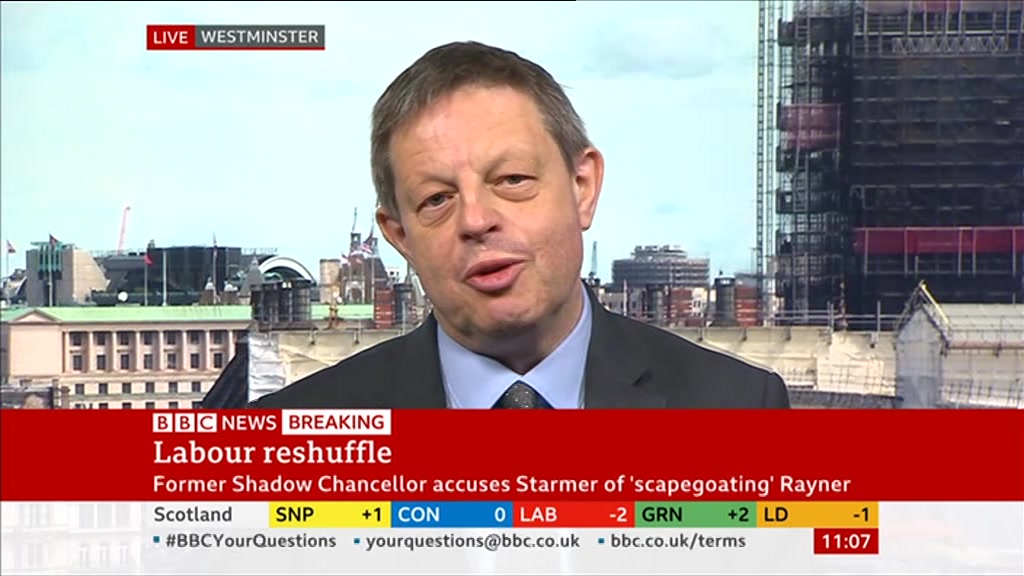
What about a quality setting of 6? Examined side-by-side with the q=2 image above, the differences are almost imperceptible. Critically, when tested across a wide range of broadcasts, we were unable to identify any major degradation to text regions or enhancement of compression artifacts surrounding characters, while the combined filesize for 1FPS sampling dropped by more than half – an important consideration when working with petascale archives.
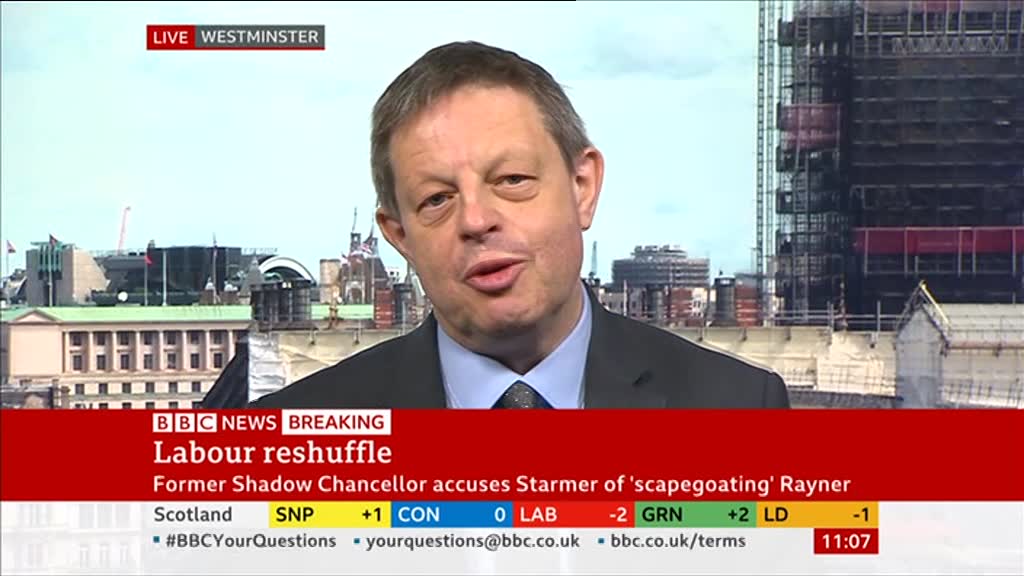
In contrast, jumping to a quality setting of 10 yields marked degradation of image quality, with the introduction of harmful compression artifacts in textual regions that reduced OCR accuracy in our tests:
Finally, with no manually-specified quality setting for this broadcast, FFMPEG automatically selected a setting of 20, yielding the extremely degraded image below. Remarkably, GCP's Cloud Vision API was still able to successfully extract the text of this image, but with significant risk of elevated error rates in general.