
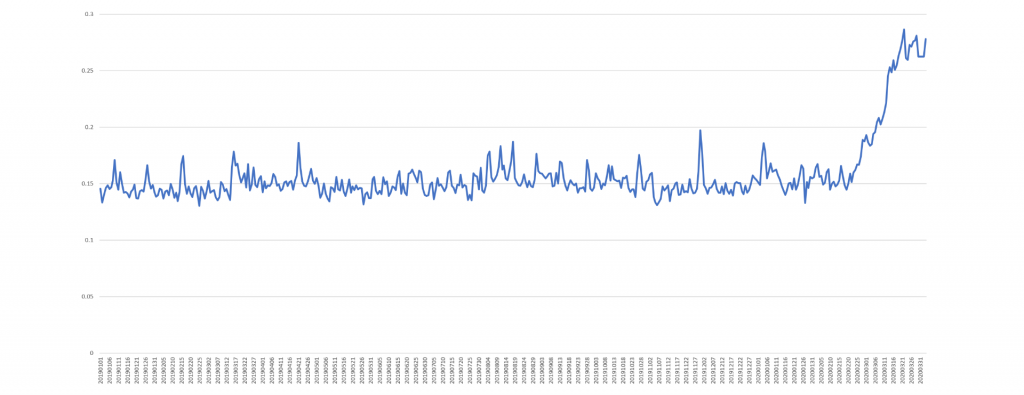
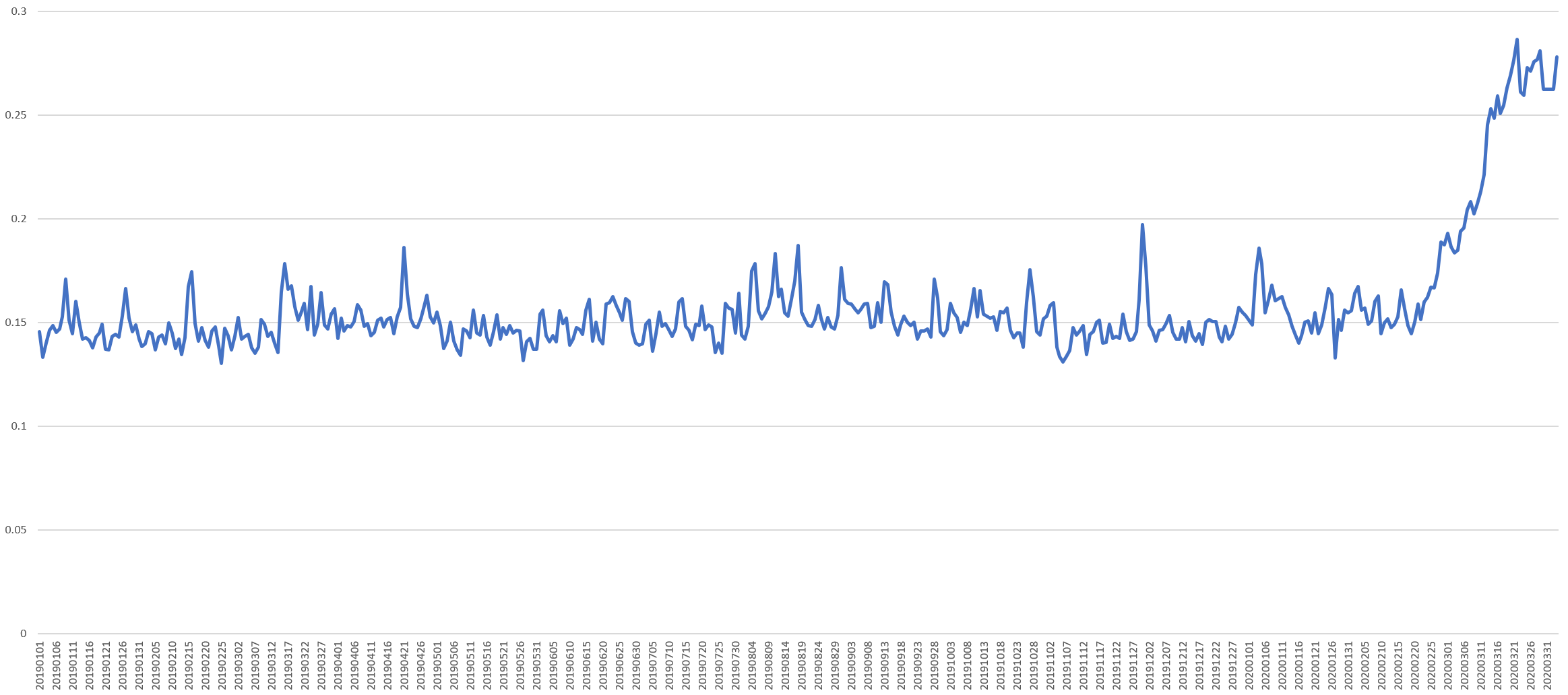
This past October we showcased using the Web News Ngrams dataset to measure global anxiety using a single BigQuery query to run it against Colin Martindale's Regressive Imagery Dictionary (RID) "anxiety" measure. The timeline below shows the same results as of today.
Beginning the last week of February, the density of "anxiety"-related words have skyrocketed in global media, showing that Covid-19's presence is now so ubiquitous that the anxiety it is causing is now measurable in the very word frequencies of English language news coverage across the entire planet.
TECHNICAL DETAILS
Constructing the graph above took just a single query (substitute your own dictionary in):
SELECT DATE, SUM(TOTMENTIONS) TOTWORDS, SUM(TONECOUNT) TOTTONEWORDS, SUM(TONECOUNT) / SUM(TOTMENTIONS) * 100 perc_anxiety from ( SELECT SUBSTR(CAST(DATE AS STRING), 0, 8) DATE, SUM(COUNT) TOTMENTIONS, SUM(COUNT) TONECOUNT FROM `gdelt-bq.gdeltv2.web_1grams` where LANG='ENGLISH' and NGRAM in (SELECT WORD FROM `YOUR-SENTIMENT-TABLE`) group by DATE, NGRAM UNION ALL SELECT SUBSTR(CAST(DATE AS STRING), 0, 8) DATE, SUM(COUNT) TOTMENTIONS, 0 TONECOUNT FROM `gdelt-bq.gdeltv2.web_1grams` where LANG='ENGLISH' and NGRAM not in (SELECT WORD FROM `YOUR-SENTIMENT-TABLE`) group by DATE, NGRAM ) group by DATE order by DATE asc