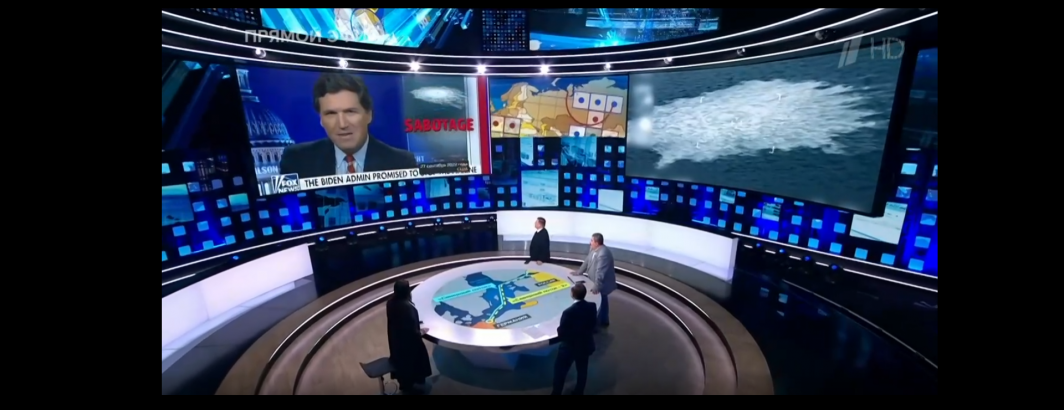
Earlier today we examined how a SOTA multimodal LLM describes a variety of news and other images, testing how well these new machine vision models are able to render complex global images covering a variety of topics into high fidelity and understandable prose for downstream analysis and indexing. When presented with the image at the top of this post, the LLM performed a remarkable feat: it extrapolated from a single screen capture of a Russian news broadcast about the Nord Stream sabotage to geopolitically contextualize Russia's invasion of Ukraine as part of a specific Russian view that it is fighting a multi-century existential battle for its existence against the West:
The image is likely from a Russian news program, and it may be related to the Bolʹshai︠a︡ igra, which is a Russian geopolitical theory. The theory states that Russia is engaged in a long-term struggle with the West for global dominance and the discussion in the image is likely depicting a modern-day continuation of this struggle.
In short, the LLM posits the Russian invasion of Ukraine as a continuation of the "Bolʹshai︠a︡ igra" or "Great Game", which refers to the 19th-century Russia-vs-West competition in Central Asia. At first glance, this description is nothing short of remarkable: from a single image, the LLM leveraged its vast archives of global history to craft its own geopolitical explanation of the Russian invasion of Ukraine, forming a new understanding of current events in their historical context. The ability of LLMs to autonomously historically contextualize breaking events would represent an immense step forward in geopolitical strategy and powerful reasoning capabilities beyond the ability of previous generations of AI systems.
In fact, when this example was given to a frontier LLM researcher for comment, the ability of the LLM to, entirely on its own without prompting or context, form a connection from current events to global world knowledge, it was cited as yet another textbook example of the "glimmers of AGI" claims increasingly emerging from the research community as LLMs perform feats previously believed limited to human intelligence.
This is typically where such examples are left: a single glimmer of incredible achievement proof of LLM's inevitable march to AGI. But what happens when we try again? This time instead of Bolʹshai︠a︡ igra referring to the Great Game and geopolitical strategy, it is merely an organization's website:
The image is likely from a Russian news program, as it can be found on websites associated with Channel One Russia and Bolʹshai︠a︡ igra. The image may have been taken in 2020, as it was first published on the GDELT Project website in that year.
Asking the LLM to describe the image a third time tears down the metaphorical magical curtain. Here we see "Bolʹshai︠a︡ igra" is actually a poor transliteration of the name of the Channel One broadcast the clip is taken from called "БОЛЬШАЯ ИГРА" or "BOL'SHAYA IGRA" that translates to "Big Game" (see original clip). In other words, Bolʹshai︠a︡ igra doesn't refer to the Russian "Great Game" geopolitical perspective of a battle against the West – it is merely the name of the Russian television show the clip was taken from:
The image is likely from a Russian news program, as the men are wearing suits and hats that are typical of Russian news anchors. The text on the screen is also in Russian. The image may be from the news program "Bolʹshai︠a︡ igra" (The Big Game), which is a popular political talk show on Channel One Russia.
Here lies one of the great challenges at the root of the "glimmer of AGI" claims from the LLM community: the very real possibility that an unprecedented LLM feat of human-like reasoning and achievement may be nothing more than random chance leading to an accidental combination of phrases anthropomorphized by a field that has steadily tilted from rational objective observation to full-throated marketing hype. In its first run, this advanced SOTA LLM appears to have made a human-like fundamental reasoning leap to contextualize Russia's invasion of Ukraine in the context of Russian geopolitical strategy, leveraging the LLM's vast historical archives of global history gleaned from crawling the open web. Subsequent runs recast its invocation of the "Great Game" from geopolitics to merely the name of an organization's website to the actual answer: just the name of the television show the clip was taken from, which the model conflated with another topic that shares the same name.
This tendency to see glimmers of brilliance in LLM outputs is why the field must move towards rerunning unexpected results multiple times to see if the finding holds and does not merely represent random chance. A closer look at our myriad explorations of LLMs applied to global news content shows just how much model outputs can vary from run to run.
Unfortunately, all-too-often when a model produces mediagenic results and then is run subsequent times and fails to produce similarly stellar results, the subsequent runs are simply ignored and only the mediagenic output reported, fueling public hype of LLM capabilities. Similarly, when evaluating models against internal and external benchmark datasets, they are all-too-frequently considered to have produced the correct response to each prompt if their initial output (or sometimes any of their outputs if run multiple times) produce the correct response. Given the brittleness and instability of contemporary LLMs and the commercial and profit and prestige pressures at stake, there are few incentives to run each benchmark prompt multiple times and consider the model successful only if it output the correct response every single time. In fact, some extremely high profile and heavily cited LLM success stories actually represent the only successful output from a long chain of far less usable outputs: this cherry picking has become increasingly common as the LLM hype cycle has built.
When evaluating LLMs, organizations should rerun each prompt multiple times (3-5 times is typically a good number), each time running it in a fresh session and then compare the outputs. Only if a successful output is generated in the majority of runs should it be considered an innate capability of the model, rather than random chance. When comparing against internal and external benchmarks, each test prompt should similarly be run 5 times and the model should be considered to have failed if any of the 5 runs do not produce the correct result.
Such reproducibility is the norm that lies at the heart of the scientific method and ensures that results are legitimate assessments of a model's capabilities rather than random chance. Moving the LLM community towards this "report all results" model would go a long way to both dispelling false hype and helping to clarify the very real actual capabilities of LLMs, helping enterprises and policymakers and the press and public better understand the current state of the field and its trajectory.