Search Results for: whisper

What OpenAI's Whisper Teaches Us About The Dependence Of The Large Models Revolution On YouTube
The Internet Archive's TV News Archive spans millions of hours of television news programming from across the world in more…

Whisper Vs Chirp: The Hidden GPU Cost Of "Free" AI Models & Why Commercial Hosted Models Can Be Far Cheaper
The rapid proliferation of impressively capable "free" open source AI models with one-click installations and simplified workflows means companies increasingly…
Experiments With Speech Transcription: Comparing The Cost Of Running OpenAI's Whisper Vs Google's Chirp In Production
Over the past few months we've transcribed more than 65 million minutes of global television news coverage spanning more than…

Experiments With Speech Transcription & Translation: Meta's SeamlessM4T Vs OpenAI's Whisper Vs GCP's STT+GT Vs GCP's USM/Chirp+GT
As the final piece in our our series of evaluating Meta's new SeamlessM4T multimodal translation model, let's evaluate its speech transcription and…

What OpenAI's Whisper Teaches Us About The Future Of Large Language Models Like ChatGPT
While specialty AI models like OpenAI's Whisper ASR speech recognition and translation target a more technical and niche audience, they…

Jason Scott: The Whispering Episode
The Internet Archive's Jason Scott mentions on his latest podcast some of GDELT's work on exploring OpenAI's Whisper ASR on…
Testing The New OpenAI Whisper ASR Large-V2 Model On A Russian TV News Broadcast
This past October we explored applying OpenAI's Whisper ASR to television news broadcast selections from more than 100 channels spanning…
Experiments With Whisper ASR: No Speedup On V100 GPU From #370
As we continue our ASR experiments with OpenAI's Whisper ASR, we've examined a recent patch that restores proper attention caching…
Applying OpenAI's Whisper ASR To 101 Sample TV News Broadcasts Spanning 50 Countries
OpenAI's open source Whisper ASR has received immense interest for its multilingual transcription and translation capabilities spanning nearly 100 languages….
Experiments With Whisper ASR: Model Parameters & Non-Determinism: temperature_increment_on_fallback
Across our experiments with OpenAI's Whisper ASR this week, its unprecedented fluency has been challenged by its high non-determinism, with…
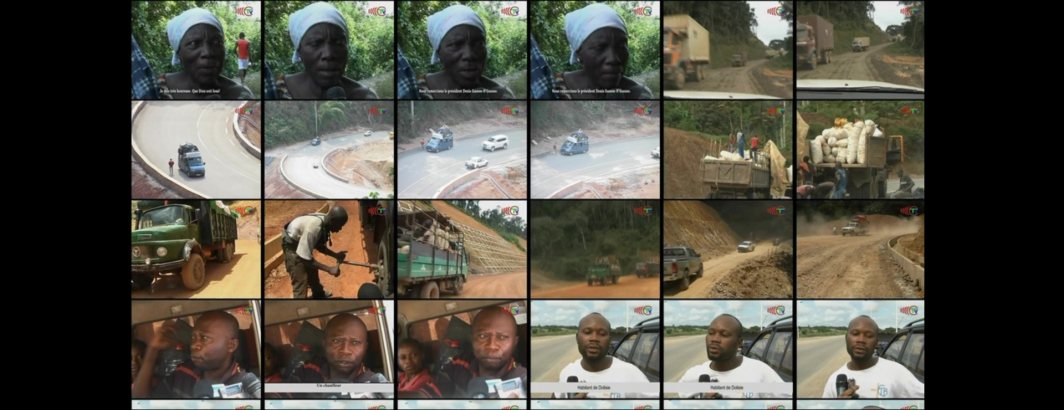
A Deep Dive Exploration Applying OpenAI's Whisper ASR To A French-Language Télé Congo TV News Broadcast
Thus far this week we have conducted deep dives applying OpenAI's Whisper ASR to Russian and English-language television news broadcasts….
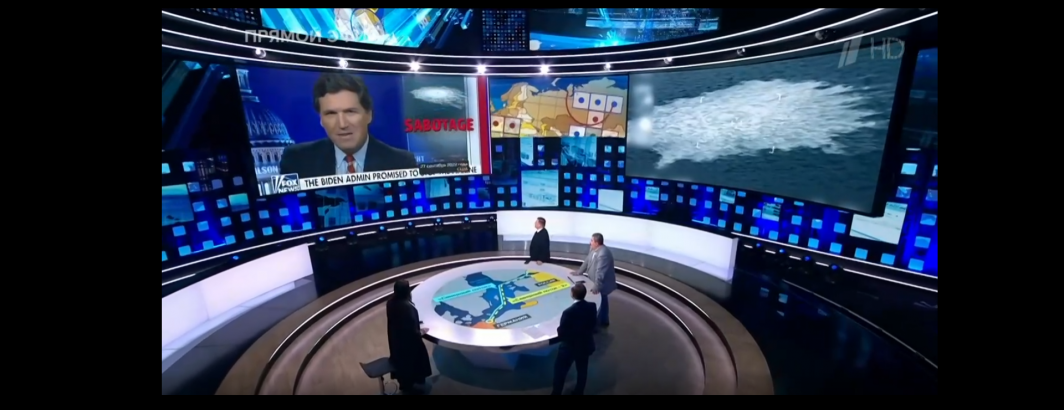
OpenAI's Whisper ASR: How The "NATO Threat To Putin" Becomes "Putin's Threats [To NATO]": The Challenges Of Machine Translation
Earlier this week we explored how OpenAI's Whisper ASR translated a Russian-language television news broadcast into English. Towards the middle…

A Deep Dive Exploration Applying OpenAI's Whisper ASR To A PBS NewsHour Broadcast
Yesterday we explored applying OpenAI's open source Whisper ASR to transcribe and translate a Russian television news broadcast, finding that…
A Deep Dive Exploration Applying OpenAI's Whisper ASR To A Russian Television News Broadcast
Last month OpenAI released an open source ASR system called Whisper, trained on 680,000 hours of multilingual data. Earlier this week…
OpenAI Whisper ASR + Russian TV News Deep Dive Coming Tomorrow
Tomorrow we will be unveiling a massive deep dive exploring OpenAI's new Whisper ASR system on a complete Russian television…
Experiments Applying OpenAI's Whisper ASR To Russian Television News
Last month OpenAI released an open source ASR system called Whisper, trained on 680,000 hours of multilingual data. How does…
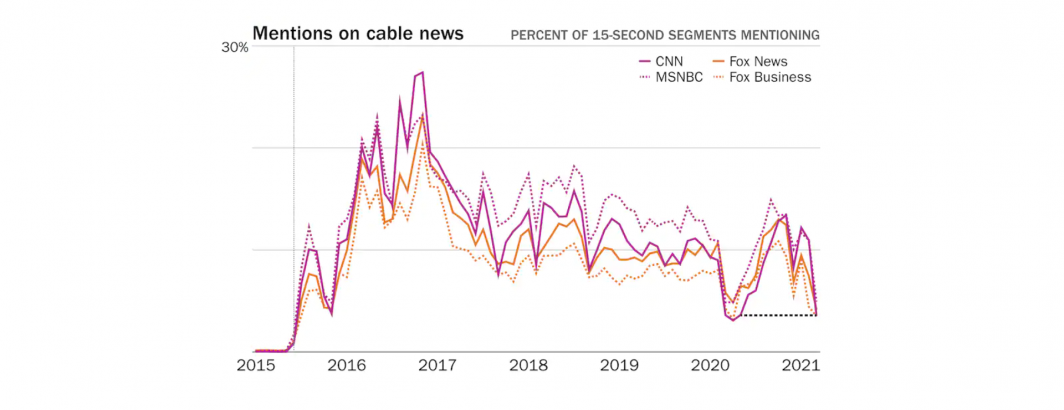
WashPost: The Trump Media Era Ends Not With A Wow But A Whisper
The Washington Post's Philip Bump uses GDELT to examine television news mentions of Donald Trump. Read The Full Article.
The Challenges Of Multilingualism In The The Large Model Era: Using LSMs & LMMs To Transcribe An Amharic Broadcast
The Internet Archive's TV News Archive spans more than 2.5 million hours of global television news in 150 languages spanning…

More Experiments In LLM Filtering Of TV News Shows: Adding More Detail Doesn't Improve Consistency Or Accuracy
Continuing our experiments in using SOTA foundation model LLMs to categorize television news shows into "news" and "not news", earlier…
How We Transcribed 2.5 Million Hours Of TV News In Just 7 Days & How We Could Have Finished In A Single Afternoon
On Wednesday, we announced in collaboration with the Internet Archive TV News Archive the machine transcription of its complete 2.5…
Generative AI & A Reminder That "Accuracy" Is Not The Same Thing As "Output"
One of the more remarkable reminders of the Wild West state of Generative AI came in a recent meeting I…
Visual Explorer: Another 30 Million Minutes Transcribed Through Google's Chirp Transcription Model
Our massive collaborative initiative to transcribe the entire Internet Archive Television News Archive added another 30 million minutes of transcribed broadcasts…
Visual Explorer: 65M Minutes Transcribed Through Google's Chirp Transcription Model
Our massive collaborative initiative to transcribe the entire Internet Archive Television News Archive has reached 65 million minutes of transcribed broadcasts…

Generative Image AI & The Potential Of At-Scale Citizen-Led National Promotional Campaigns During Times Of Crisis: A Ukraine Experiment
As we continue to explore the potential of generative AI for autonomous production and ideation of national and organizational branding…